Project Team ID = PTID-CDS-JUL21-1171 (Members - Diana, Hema, Pavithra and Sophiya)
Project ID = PRCL-0017 Customer Churn Business case
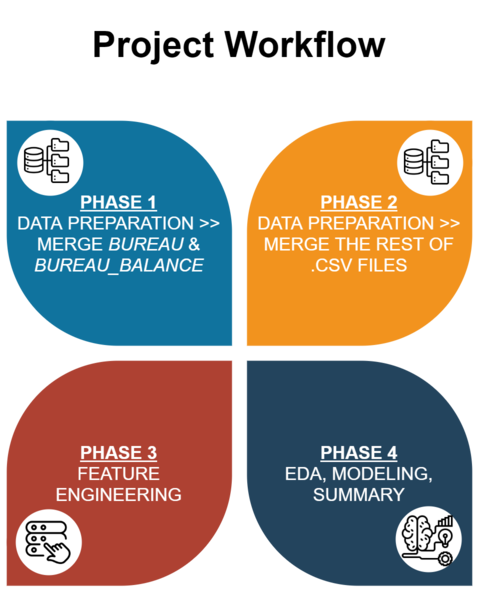
Due to the immensely colossal dataset, the whole process is divided into 4 Colabs notebooks (generally speaking),
the rest of it was just additional phase to compare models after reduce 4 features (on Phase 5, which refers to highly correlated to each other).
Phases Outline
Due to the immensely colossal datasets, we were facing difficulties in executing all the commands in a single notebook, so we are utilizing 4 Colab notebooks each executing a particular Phase of the project as noted below:
- Phase 1 → Done in the first notebook to load and merge the bureau and bureau_Balance datasets and then after Data Preparation exporting the merged dataset to GDrive.
- Phase 2 → Load the rest of datasets and then merged dataset from previous phase. After data preparation, merges all the datasets and exports the dataset to GDrive.
- Phase 3 → Do a PCA for the final merged dataset and find the consequential features that are utilizable for modeling, then export that dataset to GDrive.
- Phase 4 → Load the final dataset, EDA, Modeling, and Summary.
- [Optional] Phase 5 → Additional phase to compare models after reduce 4 features
(refers to highly correlated to each other).
—— Preliminary → Identify The Business Case ——

This is a Home Loan Default Data which contains multiple databases and sources to predict how capable each loan applicant is competent in repaying the loan.
The target is to predict their clients repayment abilities.Doing so will ensure that clients capable of repayment are not rejected and that loans are given with a principal, maturity, and repayment calendar that will empower their clients to be successful. Consequently, in order to avoid ‘the curse of dimensionality’, we’re gonna involve the top 10 of most influence features and will involve it to be a part of prediction journey (passing 10 selected features into X).
The most opportune method to solve this case is by applying classification(Logistic Regression, KNN, Decision Tree, Random Forest, XG Boost, SVM Classification).
There are 7 databases that provide data for this project so analysing the databases in 7 steps, given by the workflow below:
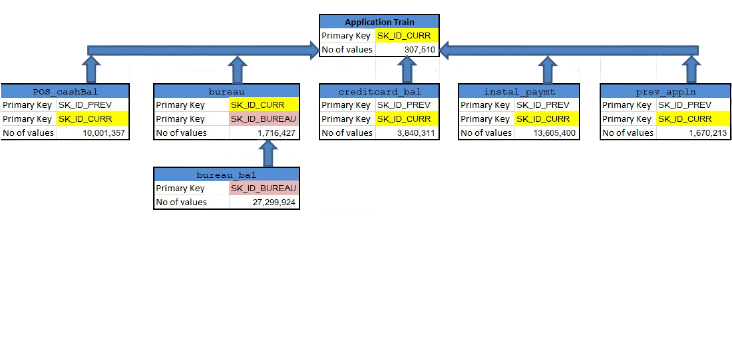
Image Credit
import numpy as np
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns',999) #set column display number
pd.set_option('display.max_rows',200) #set row display number
pd.set_option('float_format', '{:f}'.format) #set float format
from google.colab import drive
drive.mount('/content/grive')
Drive already mounted at /content/grive; to attempt to forcibly remount, call drive.mount("/content/grive", force_remount=True).
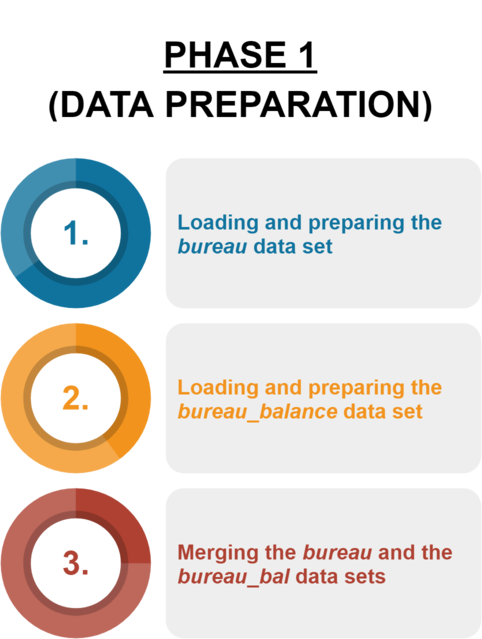
STEP 1: Loading and preparing the bureau data set
bureau = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/bureau.csv')
bureau.head()
| SK_ID_CURR | SK_ID_BUREAU | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | AMT_CREDIT_MAX_OVERDUE | CNT_CREDIT_PROLONG | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_SUM_LIMIT | AMT_CREDIT_SUM_OVERDUE | CREDIT_TYPE | DAYS_CREDIT_UPDATE | AMT_ANNUITY | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 215354 | 5714462 | Closed | currency 1 | -497 | 0 | -153.000000 | -153.000000 | nan | 0 | 91323.000000 | 0.000000 | nan | 0.000000 | Consumer credit | -131 | nan |
| 1 | 215354 | 5714463 | Active | currency 1 | -208 | 0 | 1075.000000 | nan | nan | 0 | 225000.000000 | 171342.000000 | nan | 0.000000 | Credit card | -20 | nan |
| 2 | 215354 | 5714464 | Active | currency 1 | -203 | 0 | 528.000000 | nan | nan | 0 | 464323.500000 | nan | nan | 0.000000 | Consumer credit | -16 | nan |
| 3 | 215354 | 5714465 | Active | currency 1 | -203 | 0 | nan | nan | nan | 0 | 90000.000000 | nan | nan | 0.000000 | Credit card | -16 | nan |
| 4 | 215354 | 5714466 | Active | currency 1 | -629 | 0 | 1197.000000 | nan | 77674.500000 | 0 | 2700000.000000 | nan | nan | 0.000000 | Consumer credit | -21 | nan |
bureau.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1716428 entries, 0 to 1716427
Data columns (total 17 columns):
# Column Dtype
--- ------ -----
0 SK_ID_CURR int64
1 SK_ID_BUREAU int64
2 CREDIT_ACTIVE object
3 CREDIT_CURRENCY object
4 DAYS_CREDIT int64
5 CREDIT_DAY_OVERDUE int64
6 DAYS_CREDIT_ENDDATE float64
7 DAYS_ENDDATE_FACT float64
8 AMT_CREDIT_MAX_OVERDUE float64
9 CNT_CREDIT_PROLONG int64
10 AMT_CREDIT_SUM float64
11 AMT_CREDIT_SUM_DEBT float64
12 AMT_CREDIT_SUM_LIMIT float64
13 AMT_CREDIT_SUM_OVERDUE float64
14 CREDIT_TYPE object
15 DAYS_CREDIT_UPDATE int64
16 AMT_ANNUITY float64
dtypes: float64(8), int64(6), object(3)
memory usage: 222.6+ MB
Description of The Dataset:
SK_ID_CURR → ID of loan in our sample (one loan in our sample can have 0,1,2 or more related previous credits in credit bureau).
SK_ID_BUREAU → Recoded ID of previous Credit Bureau credit related to our loan (unique coding for each loan application).
CREDIT_ACTIVE → Status of the Credit Bureau (CB) reported credits.
CREDIT_CURRENCY → Recoded currency of the Credit Bureau credit.
DAYS_CREDIT → How many days before current application did client apply for Credit Bureau credit.
CREDIT_DAY_OVERDUE → Number of days past due on CB credit at the time of application for related loan in our sample.
DAYS_CREDIT_ENDDATE → Remaining duration of CB credit (in days) at the time of application in Home Credit.
DAYS_ENDDATE_FACT → Days since CB credit ended at the time of application in Home Credit (only for closed credit).
AMT_CREDIT_MAX_OVERDUE → Maximal amount overdue on the Credit Bureau credit so far (at application date of loan in our sample).
CNT_CREDIT_PROLONG → How many times was the Credit Bureau credit prolonged.
AMT_CREDIT_SUM → Current credit amount for the Credit Bureau credit.
AMT_CREDIT_SUM_DEBT → Current debt on Credit Bureau credit.
AMT_CREDIT_SUM_LIMIT → Current credit limit of credit card reported in Credit Bureau.
AMT_CREDIT_SUM_OVERDUE → Current amount overdue on Credit Bureau credit.
CREDIT_TYPE → Type of Credit Bureau credit (Car, cash,…).
DAYS_CREDIT_UPDATE → How many days before loan application did last information about the Credit Bureau credit come.
AMT_ANNUITY → Loan annuity.
# checking if the columns have null values
bureau.isnull().sum()
SK_ID_CURR 0
SK_ID_BUREAU 0
CREDIT_ACTIVE 0
CREDIT_CURRENCY 0
DAYS_CREDIT 0
CREDIT_DAY_OVERDUE 0
DAYS_CREDIT_ENDDATE 105553
DAYS_ENDDATE_FACT 633653
AMT_CREDIT_MAX_OVERDUE 1124488
CNT_CREDIT_PROLONG 0
AMT_CREDIT_SUM 13
AMT_CREDIT_SUM_DEBT 257669
AMT_CREDIT_SUM_LIMIT 591780
AMT_CREDIT_SUM_OVERDUE 0
CREDIT_TYPE 0
DAYS_CREDIT_UPDATE 0
AMT_ANNUITY 1226791
dtype: int64
# Finding the % of missing values in each column
round(100*(bureau.isnull().sum()/len(bureau.index)),2)
SK_ID_CURR 0.000000
SK_ID_BUREAU 0.000000
CREDIT_ACTIVE 0.000000
CREDIT_CURRENCY 0.000000
DAYS_CREDIT 0.000000
CREDIT_DAY_OVERDUE 0.000000
DAYS_CREDIT_ENDDATE 6.150000
DAYS_ENDDATE_FACT 36.920000
AMT_CREDIT_MAX_OVERDUE 65.510000
CNT_CREDIT_PROLONG 0.000000
AMT_CREDIT_SUM 0.000000
AMT_CREDIT_SUM_DEBT 15.010000
AMT_CREDIT_SUM_LIMIT 34.480000
AMT_CREDIT_SUM_OVERDUE 0.000000
CREDIT_TYPE 0.000000
DAYS_CREDIT_UPDATE 0.000000
AMT_ANNUITY 71.470000
dtype: float64
#Assigning NULL percentage value to a variable
bur_null = round(100*(bureau.isnull().sum()/len(bureau.index)),2)
# find columns with more than 50% missing values
colBur = bur_null[bur_null >= 50].index
# drop columns with high null percentage
bureau.drop(colBur,axis = 1,inplace = True)
#check null percentage after dropping
round(100*(bureau.isnull().sum()/len(bureau.index)),2)
SK_ID_CURR 0.000000
SK_ID_BUREAU 0.000000
CREDIT_ACTIVE 0.000000
CREDIT_CURRENCY 0.000000
DAYS_CREDIT 0.000000
CREDIT_DAY_OVERDUE 0.000000
DAYS_CREDIT_ENDDATE 6.150000
DAYS_ENDDATE_FACT 36.920000
CNT_CREDIT_PROLONG 0.000000
AMT_CREDIT_SUM 0.000000
AMT_CREDIT_SUM_DEBT 15.010000
AMT_CREDIT_SUM_LIMIT 34.480000
AMT_CREDIT_SUM_OVERDUE 0.000000
CREDIT_TYPE 0.000000
DAYS_CREDIT_UPDATE 0.000000
dtype: float64
# checking the shape after dropping
bureau.shape
(1716428, 15)
Remarks → 2 columns were dropped (they had > 50% of missing values.)
# checking the description
bureau.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SK_ID_CURR | 1716428.000000 | 278214.933645 | 102938.558112 | 100001.000000 | 188866.750000 | 278055.000000 | 367426.000000 | 456255.000000 |
| SK_ID_BUREAU | 1716428.000000 | 5924434.489032 | 532265.728552 | 5000000.000000 | 5463953.750000 | 5926303.500000 | 6385681.250000 | 6843457.000000 |
| DAYS_CREDIT | 1716428.000000 | -1142.107685 | 795.164928 | -2922.000000 | -1666.000000 | -987.000000 | -474.000000 | 0.000000 |
| CREDIT_DAY_OVERDUE | 1716428.000000 | 0.818167 | 36.544428 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2792.000000 |
| DAYS_CREDIT_ENDDATE | 1610875.000000 | 510.517362 | 4994.219837 | -42060.000000 | -1138.000000 | -330.000000 | 474.000000 | 31199.000000 |
| DAYS_ENDDATE_FACT | 1082775.000000 | -1017.437148 | 714.010626 | -42023.000000 | -1489.000000 | -897.000000 | -425.000000 | 0.000000 |
| CNT_CREDIT_PROLONG | 1716428.000000 | 0.006410 | 0.096224 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 9.000000 |
| AMT_CREDIT_SUM | 1716415.000000 | 354994.591918 | 1149811.343980 | 0.000000 | 51300.000000 | 125518.500000 | 315000.000000 | 585000000.000000 |
| AMT_CREDIT_SUM_DEBT | 1458759.000000 | 137085.119952 | 677401.130952 | -4705600.320000 | 0.000000 | 0.000000 | 40153.500000 | 170100000.000000 |
| AMT_CREDIT_SUM_LIMIT | 1124648.000000 | 6229.514980 | 45032.031476 | -586406.115000 | 0.000000 | 0.000000 | 0.000000 | 4705600.320000 |
| AMT_CREDIT_SUM_OVERDUE | 1716428.000000 | 37.912758 | 5937.650035 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 3756681.000000 |
| DAYS_CREDIT_UPDATE | 1716428.000000 | -593.748320 | 720.747312 | -41947.000000 | -908.000000 | -395.000000 | -33.000000 | 372.000000 |
Days credit, Days Credit End date, Days Enddate Fact, amt credit sum debt and amt credit sum limit have negative values. These negative values are noted and accepted as the negative values represent the past data from the date of application.
# Filling the null values with mean of their respective columns
bureau['DAYS_CREDIT_ENDDATE'].fillna(bureau['DAYS_CREDIT_ENDDATE'].mean(), inplace = True)
bureau['DAYS_ENDDATE_FACT'].fillna(bureau['DAYS_ENDDATE_FACT'].mean(), inplace = True)
bureau['AMT_CREDIT_SUM_DEBT'].fillna(bureau['AMT_CREDIT_SUM_DEBT'].mean(), inplace = True)
bureau['AMT_CREDIT_SUM_LIMIT'].fillna(bureau['AMT_CREDIT_SUM_LIMIT'].mean(), inplace = True)
bureau['AMT_CREDIT_SUM'].fillna(bureau['AMT_CREDIT_SUM'].mean(), inplace = True)
# checking to see if all the null values are filled
bureau.isnull().sum()
SK_ID_CURR 0
SK_ID_BUREAU 0
CREDIT_ACTIVE 0
CREDIT_CURRENCY 0
DAYS_CREDIT 0
CREDIT_DAY_OVERDUE 0
DAYS_CREDIT_ENDDATE 0
DAYS_ENDDATE_FACT 0
CNT_CREDIT_PROLONG 0
AMT_CREDIT_SUM 0
AMT_CREDIT_SUM_DEBT 0
AMT_CREDIT_SUM_LIMIT 0
AMT_CREDIT_SUM_OVERDUE 0
CREDIT_TYPE 0
DAYS_CREDIT_UPDATE 0
dtype: int64
The bureau data set is now clean with no missing values and ready to be merged with the other datasets.
STEP 2: Loading and preparing the bureau_balance data set
bureau_bal = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/bureau_balance.csv')
bureau_bal.head()
| SK_ID_BUREAU | MONTHS_BALANCE | STATUS | |
|---|---|---|---|
| 0 | 5715448 | 0 | C |
| 1 | 5715448 | -1 | C |
| 2 | 5715448 | -2 | C |
| 3 | 5715448 | -3 | C |
| 4 | 5715448 | -4 | C |
bureau_bal.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27299925 entries, 0 to 27299924
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 SK_ID_BUREAU int64
1 MONTHS_BALANCE int64
2 STATUS object
dtypes: int64(2), object(1)
memory usage: 624.8+ MB
# checking for missing values
bureau_bal.isnull().sum()
SK_ID_BUREAU 0
MONTHS_BALANCE 0
STATUS 0
dtype: int64
bureau_bal.describe()
| SK_ID_BUREAU | MONTHS_BALANCE | |
|---|---|---|
| count | 27299925.000000 | 27299925.000000 |
| mean | 6036297.332974 | -30.741687 |
| std | 492348.856904 | 23.864509 |
| min | 5001709.000000 | -96.000000 |
| 25% | 5730933.000000 | -46.000000 |
| 50% | 6070821.000000 | -25.000000 |
| 75% | 6431951.000000 | -11.000000 |
| max | 6842888.000000 | 0.000000 |
The MONTHS_BALANCE column has negative values but the team has chosen to leave the negative values as is because MONTHS_BALANCE describes the Month of balance relative to application date (-1 means the freshest balance date).
Description of the dataset:
SK_ID_BUREAU → Recoded ID of Credit Bureau credit (unique coding for each application) - use this to join to CREDIT_BUREAU table.
MONTHS_BALANCE → Month of balance relative to application date (-1 means the freshest balance date).
STATUS → Status of Credit Bureau loan during the month (active, closed, DPD0-30,… [C means closed, X means status unknown, 0 means no DPD, 1 means maximal did during month between 1-30, 2 means DPD 31-60,… 5 means DPD 120+ or sold or written off ]).
# Checking the no. of unique SK_ID_BUREAU values
countbur = bureau_bal["SK_ID_BUREAU"].unique()
countbur.shape
(817395,)
For each unique SK_ID_BUREAU there are duplicate rows that provide the data for multiple dates so we need to keep only that row that has the most recent information and drop the old information. In this dataset we will keep only those rows that have the most recent information about the MONTHS_BALANCE for each applicant relative to the application date (-1 means the freshest balance date) by retaining those rows that have the max value for months balance (given the negative values, max operator will give the most recent info) and delete the other rows for each unique SK_ID_BUREAU.
bureau_bal = bureau_bal.groupby('SK_ID_BUREAU', group_keys=False).apply(lambda x: x.loc[x.MONTHS_BALANCE.idxmax()])
bureau_bal.shape
(817395, 3)
bureau_bal['index'] = bureau_bal.index
| SK_ID_CURR | SK_ID_BUREAU | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | CNT_CREDIT_PROLONG | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_SUM_LIMIT | AMT_CREDIT_SUM_OVERDUE | CREDIT_TYPE | DAYS_CREDIT_UPDATE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 215354 | 5714462 | Closed | currency 1 | -497 | 0 | -153.000000 | -153.000000 | 0 | 91323.000000 | 0.000000 | 6229.514980 | 0.000000 | Consumer credit | -131 |
| 1 | 215354 | 5714463 | Active | currency 1 | -208 | 0 | 1075.000000 | -1017.437148 | 0 | 225000.000000 | 171342.000000 | 6229.514980 | 0.000000 | Credit card | -20 |
| 2 | 215354 | 5714464 | Active | currency 1 | -203 | 0 | 528.000000 | -1017.437148 | 0 | 464323.500000 | 137085.119952 | 6229.514980 | 0.000000 | Consumer credit | -16 |
| 3 | 215354 | 5714465 | Active | currency 1 | -203 | 0 | 510.517362 | -1017.437148 | 0 | 90000.000000 | 137085.119952 | 6229.514980 | 0.000000 | Credit card | -16 |
| 4 | 215354 | 5714466 | Active | currency 1 | -629 | 0 | 1197.000000 | -1017.437148 | 0 | 2700000.000000 | 137085.119952 | 6229.514980 | 0.000000 | Consumer credit | -21 |
bureau_bal.index.name = None
bureau_bal.head()
| SK_ID_BUREAU | MONTHS_BALANCE | STATUS | index | |
|---|---|---|---|---|
| 5001709 | 5001709 | 0 | C | 5001709 |
| 5001710 | 5001710 | 0 | C | 5001710 |
| 5001711 | 5001711 | 0 | X | 5001711 |
| 5001712 | 5001712 | 0 | C | 5001712 |
| 5001713 | 5001713 | 0 | X | 5001713 |
The bureau_balance data set is now clean with no missing values and duplicates and is now ready to be merged with the other datasets.
STEP 3: Merging the bureau and the bureau_bal data sets
# Left merge the two datasets
bureau_merged = pd.merge(bureau, bureau_bal, on='SK_ID_BUREAU', how='left')
print(bureau.shape, bureau_bal.shape, bureau_merged.shape)
(1716428, 15) (817395, 4) (1716428, 18)
# the above results show that there are duplicate rows for each SK_ID_CURR, we must keep only those rows that have the most recent info for applicant
# Checking the no. of unique SK_ID_CURR values
countmer = bureau_merged["SK_ID_CURR"].unique()
countmer.shape
(305811,)
# Keeping only those rows that have the most recent info from the application date and deleting old rows for each SK_ID_CURR
bureau_merged = bureau_merged.groupby('SK_ID_CURR', group_keys=False).apply(lambda x: x.loc[x.DAYS_CREDIT.idxmax()])
bureau_merged.shape
(305811, 18)
# Dropping SK_ID_BUREAU column as it is no longer needed for further merging of the datasets
bureau_merged.drop(['SK_ID_BUREAU'], axis = 1, inplace = True)
bureau_merged.shape
(305811, 17)
#Export the file
bureau_merged.to_csv('bureau_merged.csv')
from google.colab import files
files.download("bureau_merged.csv")
<IPython.core.display.Javascript object>
<IPython.core.display.Javascript object>
import numpy as np
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns',999) #set column display number
pd.set_option('display.max_rows',200) #set row display number
pd.set_option('float_format', '{:f}'.format) #set float format
from google.colab import drive
drive.mount('/content/grive')
Mounted at /content/grive
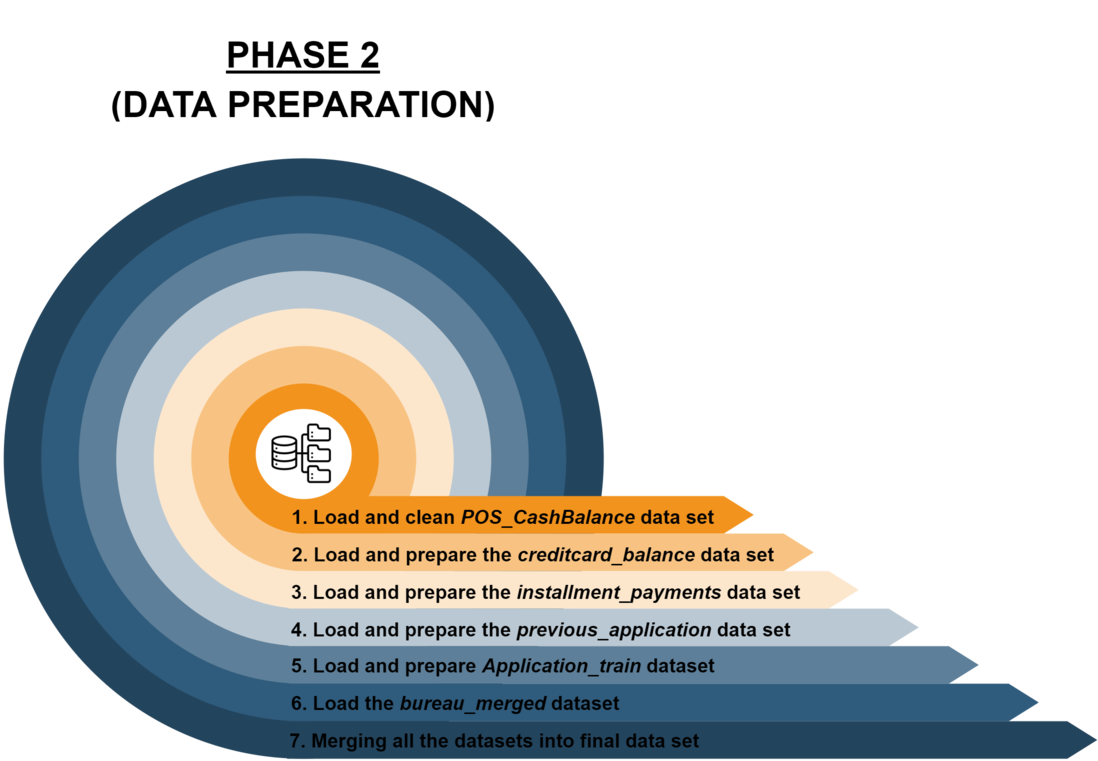
STEP 1: Loading and cleaning POS_CashBalance data set
# Loading the dataset
POS_cashBal = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/POS_CASH_balance.csv')
POS_cashBal.head()
| SK_ID_PREV | SK_ID_CURR | MONTHS_BALANCE | CNT_INSTALMENT | CNT_INSTALMENT_FUTURE | NAME_CONTRACT_STATUS | SK_DPD | SK_DPD_DEF | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1803195 | 182943 | -31 | 48.000000 | 45.000000 | Active | 0 | 0 |
| 1 | 1715348 | 367990 | -33 | 36.000000 | 35.000000 | Active | 0 | 0 |
| 2 | 1784872 | 397406 | -32 | 12.000000 | 9.000000 | Active | 0 | 0 |
| 3 | 1903291 | 269225 | -35 | 48.000000 | 42.000000 | Active | 0 | 0 |
| 4 | 2341044 | 334279 | -35 | 36.000000 | 35.000000 | Active | 0 | 0 |
POS_cashBal.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10001358 entries, 0 to 10001357
Data columns (total 8 columns):
# Column Dtype
--- ------ -----
0 SK_ID_PREV int64
1 SK_ID_CURR int64
2 MONTHS_BALANCE int64
3 CNT_INSTALMENT float64
4 CNT_INSTALMENT_FUTURE float64
5 NAME_CONTRACT_STATUS object
6 SK_DPD int64
7 SK_DPD_DEF int64
dtypes: float64(2), int64(5), object(1)
memory usage: 610.4+ MB
Description of The Dataset:
SK_ID_PREV → ID of previous credit in Home Credit related to loan in our sample. (One loan in our sample can have 0,1,2 or more previous loans in Home Credit).
SK_ID_CURR → ID of loan in our sample.
MONTHS_BALANCE → Month of balance relative to application date (-1 means the freshest balance date).
CNT_INSTALMENT → Term of previous credit (can change over time).
CNT_INSTALMENT_FUTURE → Installments left to pay on the previous credit.
NAME_CONTRACT_STATUS → Contract status during the month.
SK_DPD → DPD (days past due) during the month of previous credit.
SK_DPD_DEF → DPD during the month with tolerance (debts with low loan amounts are ignored) of the previous credit.
# checking for the null values in the columns
POS_cashBal.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
MONTHS_BALANCE 0
CNT_INSTALMENT 26071
CNT_INSTALMENT_FUTURE 26087
NAME_CONTRACT_STATUS 0
SK_DPD 0
SK_DPD_DEF 0
dtype: int64
# checking to see if there are any negative values
POS_cashBal.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SK_ID_PREV | 10001358.000000 | 1903216.598957 | 535846.530722 | 1000001.000000 | 1434405.000000 | 1896565.000000 | 2368963.000000 | 2843499.000000 |
| SK_ID_CURR | 10001358.000000 | 278403.863306 | 102763.745090 | 100001.000000 | 189550.000000 | 278654.000000 | 367429.000000 | 456255.000000 |
| MONTHS_BALANCE | 10001358.000000 | -35.012588 | 26.066570 | -96.000000 | -54.000000 | -28.000000 | -13.000000 | -1.000000 |
| CNT_INSTALMENT | 9975287.000000 | 17.089650 | 11.995056 | 1.000000 | 10.000000 | 12.000000 | 24.000000 | 92.000000 |
| CNT_INSTALMENT_FUTURE | 9975271.000000 | 10.483840 | 11.109058 | 0.000000 | 3.000000 | 7.000000 | 14.000000 | 85.000000 |
| SK_DPD | 10001358.000000 | 11.606928 | 132.714043 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 4231.000000 |
| SK_DPD_DEF | 10001358.000000 | 0.654468 | 32.762491 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 3595.000000 |
MONTHS_BALANCE is the only column that has negative values. We have chosen to leave the negative signs as is, as it makes sense to have the negative values as it reflects the Month of balance relative to application date (-1 means the freshest balance date).
# Checking the % of missing values in each column
round(100*(POS_cashBal.isnull().sum()/len(POS_cashBal.index)),2)
SK_ID_PREV 0.000000
SK_ID_CURR 0.000000
MONTHS_BALANCE 0.000000
CNT_INSTALMENT 0.260000
CNT_INSTALMENT_FUTURE 0.260000
NAME_CONTRACT_STATUS 0.000000
SK_DPD 0.000000
SK_DPD_DEF 0.000000
dtype: float64
# Filling the missing values in the columns with means of the respective columns
POS_cashBal['CNT_INSTALMENT'].fillna(POS_cashBal['CNT_INSTALMENT'].mean(), inplace = True)
POS_cashBal['CNT_INSTALMENT_FUTURE'].fillna(POS_cashBal['CNT_INSTALMENT_FUTURE'].mean(), inplace = True)
# checking if there are any more null values
POS_cashBal.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
MONTHS_BALANCE 0
CNT_INSTALMENT 0
CNT_INSTALMENT_FUTURE 0
NAME_CONTRACT_STATUS 0
SK_DPD 0
SK_DPD_DEF 0
dtype: int64
#Checking the no. of unique SK_ID_CURR values
count = POS_cashBal["SK_ID_CURR"].unique()
count.shape
(337252,)
For each unique SK_ID_CURR there are duplicate rows that provide the data for the applicant on multiple dates so we need to keep only that row that has the most recent information and drop the old information. In this dataset we will keep only those rows that have the max MONTHS_BALANCE (least negative values as to the latest Month of balance relative to application date (-1 means the freshest balance date)) and delete the other rows for each unique SK_ID_CURR.
POS_cashBal = POS_cashBal.groupby('SK_ID_CURR', group_keys=False).apply(lambda x: x.loc[x.MONTHS_BALANCE.idxmax()])
POS_cashBal.shape
(337252, 8)
POS_cashBal['index'] = POS_cashBal.index
POS_cashBal.index.name = None
POS_cashBal.drop(['SK_ID_PREV', 'index'], axis = 1, inplace = True)
POS_cashBal.head()
| SK_ID_CURR | MONTHS_BALANCE | CNT_INSTALMENT | CNT_INSTALMENT_FUTURE | NAME_CONTRACT_STATUS | SK_DPD | SK_DPD_DEF | |
|---|---|---|---|---|---|---|---|
| 100001 | 100001 | -53 | 4.000000 | 0.000000 | Completed | 0 | 0 |
| 100002 | 100002 | -1 | 24.000000 | 6.000000 | Active | 0 | 0 |
| 100003 | 100003 | -18 | 7.000000 | 0.000000 | Completed | 0 | 0 |
| 100004 | 100004 | -24 | 3.000000 | 0.000000 | Completed | 0 | 0 |
| 100005 | 100005 | -15 | 9.000000 | 0.000000 | Completed | 0 | 0 |
The POSitive_cash_balance data set is now clean with no missing values and duplicates and is now ready to be merged with the other datasets.
STEP 2: Loading and preparing the creditcard_balance data set
creditcard_bal = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/credit_card_balance.csv')
creditcard_bal.head()
| SK_ID_PREV | SK_ID_CURR | MONTHS_BALANCE | AMT_BALANCE | AMT_CREDIT_LIMIT_ACTUAL | AMT_DRAWINGS_ATM_CURRENT | AMT_DRAWINGS_CURRENT | AMT_DRAWINGS_OTHER_CURRENT | AMT_DRAWINGS_POS_CURRENT | AMT_INST_MIN_REGULARITY | AMT_PAYMENT_CURRENT | AMT_PAYMENT_TOTAL_CURRENT | AMT_RECEIVABLE_PRINCIPAL | AMT_RECIVABLE | AMT_TOTAL_RECEIVABLE | CNT_DRAWINGS_ATM_CURRENT | CNT_DRAWINGS_CURRENT | CNT_DRAWINGS_OTHER_CURRENT | CNT_DRAWINGS_POS_CURRENT | CNT_INSTALMENT_MATURE_CUM | NAME_CONTRACT_STATUS | SK_DPD | SK_DPD_DEF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2562384 | 378907 | -6 | 56.970000 | 135000 | 0.000000 | 877.500000 | 0.000000 | 877.500000 | 1700.325000 | 1800.000000 | 1800.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1 | 0.000000 | 1.000000 | 35.000000 | Active | 0 | 0 |
| 1 | 2582071 | 363914 | -1 | 63975.555000 | 45000 | 2250.000000 | 2250.000000 | 0.000000 | 0.000000 | 2250.000000 | 2250.000000 | 2250.000000 | 60175.080000 | 64875.555000 | 64875.555000 | 1.000000 | 1 | 0.000000 | 0.000000 | 69.000000 | Active | 0 | 0 |
| 2 | 1740877 | 371185 | -7 | 31815.225000 | 450000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2250.000000 | 2250.000000 | 2250.000000 | 26926.425000 | 31460.085000 | 31460.085000 | 0.000000 | 0 | 0.000000 | 0.000000 | 30.000000 | Active | 0 | 0 |
| 3 | 1389973 | 337855 | -4 | 236572.110000 | 225000 | 2250.000000 | 2250.000000 | 0.000000 | 0.000000 | 11795.760000 | 11925.000000 | 11925.000000 | 224949.285000 | 233048.970000 | 233048.970000 | 1.000000 | 1 | 0.000000 | 0.000000 | 10.000000 | Active | 0 | 0 |
| 4 | 1891521 | 126868 | -1 | 453919.455000 | 450000 | 0.000000 | 11547.000000 | 0.000000 | 11547.000000 | 22924.890000 | 27000.000000 | 27000.000000 | 443044.395000 | 453919.455000 | 453919.455000 | 0.000000 | 1 | 0.000000 | 1.000000 | 101.000000 | Active | 0 | 0 |
creditcard_bal.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3840312 entries, 0 to 3840311
Data columns (total 23 columns):
# Column Dtype
--- ------ -----
0 SK_ID_PREV int64
1 SK_ID_CURR int64
2 MONTHS_BALANCE int64
3 AMT_BALANCE float64
4 AMT_CREDIT_LIMIT_ACTUAL int64
5 AMT_DRAWINGS_ATM_CURRENT float64
6 AMT_DRAWINGS_CURRENT float64
7 AMT_DRAWINGS_OTHER_CURRENT float64
8 AMT_DRAWINGS_POS_CURRENT float64
9 AMT_INST_MIN_REGULARITY float64
10 AMT_PAYMENT_CURRENT float64
11 AMT_PAYMENT_TOTAL_CURRENT float64
12 AMT_RECEIVABLE_PRINCIPAL float64
13 AMT_RECIVABLE float64
14 AMT_TOTAL_RECEIVABLE float64
15 CNT_DRAWINGS_ATM_CURRENT float64
16 CNT_DRAWINGS_CURRENT int64
17 CNT_DRAWINGS_OTHER_CURRENT float64
18 CNT_DRAWINGS_POS_CURRENT float64
19 CNT_INSTALMENT_MATURE_CUM float64
20 NAME_CONTRACT_STATUS object
21 SK_DPD int64
22 SK_DPD_DEF int64
dtypes: float64(15), int64(7), object(1)
memory usage: 673.9+ MB
# checking for missing values in the columns
creditcard_bal.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
MONTHS_BALANCE 0
AMT_BALANCE 0
AMT_CREDIT_LIMIT_ACTUAL 0
AMT_DRAWINGS_ATM_CURRENT 749816
AMT_DRAWINGS_CURRENT 0
AMT_DRAWINGS_OTHER_CURRENT 749816
AMT_DRAWINGS_POS_CURRENT 749816
AMT_INST_MIN_REGULARITY 305236
AMT_PAYMENT_CURRENT 767988
AMT_PAYMENT_TOTAL_CURRENT 0
AMT_RECEIVABLE_PRINCIPAL 0
AMT_RECIVABLE 0
AMT_TOTAL_RECEIVABLE 0
CNT_DRAWINGS_ATM_CURRENT 749816
CNT_DRAWINGS_CURRENT 0
CNT_DRAWINGS_OTHER_CURRENT 749816
CNT_DRAWINGS_POS_CURRENT 749816
CNT_INSTALMENT_MATURE_CUM 305236
NAME_CONTRACT_STATUS 0
SK_DPD 0
SK_DPD_DEF 0
dtype: int64
# Finding the % of missing values in the columns
round(100*(creditcard_bal.isnull().sum()/len(creditcard_bal.index)),2)
SK_ID_PREV 0.000000
SK_ID_CURR 0.000000
MONTHS_BALANCE 0.000000
AMT_BALANCE 0.000000
AMT_CREDIT_LIMIT_ACTUAL 0.000000
AMT_DRAWINGS_ATM_CURRENT 19.520000
AMT_DRAWINGS_CURRENT 0.000000
AMT_DRAWINGS_OTHER_CURRENT 19.520000
AMT_DRAWINGS_POS_CURRENT 19.520000
AMT_INST_MIN_REGULARITY 7.950000
AMT_PAYMENT_CURRENT 20.000000
AMT_PAYMENT_TOTAL_CURRENT 0.000000
AMT_RECEIVABLE_PRINCIPAL 0.000000
AMT_RECIVABLE 0.000000
AMT_TOTAL_RECEIVABLE 0.000000
CNT_DRAWINGS_ATM_CURRENT 19.520000
CNT_DRAWINGS_CURRENT 0.000000
CNT_DRAWINGS_OTHER_CURRENT 19.520000
CNT_DRAWINGS_POS_CURRENT 19.520000
CNT_INSTALMENT_MATURE_CUM 7.950000
NAME_CONTRACT_STATUS 0.000000
SK_DPD 0.000000
SK_DPD_DEF 0.000000
dtype: float64
creditcard_bal.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SK_ID_PREV | 3840312.000000 | 1904503.589900 | 536469.470563 | 1000018.000000 | 1434385.000000 | 1897122.000000 | 2369327.750000 | 2843496.000000 |
| SK_ID_CURR | 3840312.000000 | 278324.207289 | 102704.475133 | 100006.000000 | 189517.000000 | 278396.000000 | 367580.000000 | 456250.000000 |
| MONTHS_BALANCE | 3840312.000000 | -34.521921 | 26.667751 | -96.000000 | -55.000000 | -28.000000 | -11.000000 | -1.000000 |
| AMT_BALANCE | 3840312.000000 | 58300.155262 | 106307.031025 | -420250.185000 | 0.000000 | 0.000000 | 89046.686250 | 1505902.185000 |
| AMT_CREDIT_LIMIT_ACTUAL | 3840312.000000 | 153807.957400 | 165145.699523 | 0.000000 | 45000.000000 | 112500.000000 | 180000.000000 | 1350000.000000 |
| AMT_DRAWINGS_ATM_CURRENT | 3090496.000000 | 5961.324822 | 28225.688579 | -6827.310000 | 0.000000 | 0.000000 | 0.000000 | 2115000.000000 |
| AMT_DRAWINGS_CURRENT | 3840312.000000 | 7433.388179 | 33846.077334 | -6211.620000 | 0.000000 | 0.000000 | 0.000000 | 2287098.315000 |
| AMT_DRAWINGS_OTHER_CURRENT | 3090496.000000 | 288.169582 | 8201.989345 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1529847.000000 |
| AMT_DRAWINGS_POS_CURRENT | 3090496.000000 | 2968.804848 | 20796.887047 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2239274.160000 |
| AMT_INST_MIN_REGULARITY | 3535076.000000 | 3540.204129 | 5600.154122 | 0.000000 | 0.000000 | 0.000000 | 6633.911250 | 202882.005000 |
| AMT_PAYMENT_CURRENT | 3072324.000000 | 10280.537702 | 36078.084953 | 0.000000 | 152.370000 | 2702.700000 | 9000.000000 | 4289207.445000 |
| AMT_PAYMENT_TOTAL_CURRENT | 3840312.000000 | 7588.856739 | 32005.987768 | 0.000000 | 0.000000 | 0.000000 | 6750.000000 | 4278315.690000 |
| AMT_RECEIVABLE_PRINCIPAL | 3840312.000000 | 55965.876905 | 102533.616843 | -423305.820000 | 0.000000 | 0.000000 | 85359.240000 | 1472316.795000 |
| AMT_RECIVABLE | 3840312.000000 | 58088.811177 | 105965.369908 | -420250.185000 | 0.000000 | 0.000000 | 88899.491250 | 1493338.185000 |
| AMT_TOTAL_RECEIVABLE | 3840312.000000 | 58098.285489 | 105971.801103 | -420250.185000 | 0.000000 | 0.000000 | 88914.510000 | 1493338.185000 |
| CNT_DRAWINGS_ATM_CURRENT | 3090496.000000 | 0.309449 | 1.100401 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 51.000000 |
| CNT_DRAWINGS_CURRENT | 3840312.000000 | 0.703144 | 3.190347 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 165.000000 |
| CNT_DRAWINGS_OTHER_CURRENT | 3090496.000000 | 0.004812 | 0.082639 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 12.000000 |
| CNT_DRAWINGS_POS_CURRENT | 3090496.000000 | 0.559479 | 3.240649 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 165.000000 |
| CNT_INSTALMENT_MATURE_CUM | 3535076.000000 | 20.825084 | 20.051494 | 0.000000 | 4.000000 | 15.000000 | 32.000000 | 120.000000 |
| SK_DPD | 3840312.000000 | 9.283667 | 97.515700 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 3260.000000 |
| SK_DPD_DEF | 3840312.000000 | 0.331622 | 21.479231 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 3260.000000 |
MONTHS_BALANCE, AMT_BALANCE, AMT_DRAWINGS_ATM_CURRENT, AMT_DRAWINGS_CURRENT, AMT_RECEIVABLE_PRINCIPAL, AMT_RECIVABLE, AMT_TOTAL_RECEIVABLE columns have negative values.
Description of The Dataset:
SK_ID_PREV ID of previous credit in Home Credit related to loan in our sample. (One loan in our sample can have 0,1,2 or more previous loans in Home Credit).
SK_ID_CURR → ID of loan in our sample.
MONTHS_BALANCE → Month of balance relative to application date (-1 means the freshest balance date).
AMT_BALANCE → Balance during the month of previous credit.
AMT_CREDIT_LIMIT_ACTUAL → Credit card limit during the month of the previous credit.
AMT_DRAWINGS_ATM_CURRENT → Amount drawing at ATM during the month of the previous credit.
AMT_DRAWINGS_CURRENT → Amount drawing during the month of the previous credit.
AMT_DRAWINGS_OTHER_CURRENT → Amount of other drawings during the month of the previous credit.
AMT_DRAWINGS_POS_CURRENT → Amount drawing or buying goods during the month of the previous credit.
AMT_INST_MIN_REGULARITY → Minimal installment for this month of the previous credit.
AMT_PAYMENT_CURRENT → How much did the client pay during the month on the previous credit.
AMT_PAYMENT_TOTAL_CURRENT → How much did the client pay during the month in total on the previous credit.
AMT_RECEIVABLE_PRINCIPAL → Amount receivable for principal on the previous credit.
AMT_RECIVABLE → Amount receivable on the previous credit.
AMT_TOTAL_RECEIVABLE → Total amount receivable on the previous credit.
CNT_DRAWINGS_ATM_CURRENT → Number of drawings at ATM during this month on the previous credit.
CNT_DRAWINGS_CURRENT → Number of drawings during this month on the previous credit.
CNT_DRAWINGS_OTHER_CURRENT → Number of other drawings during this month on the previous credit.
CNT_DRAWINGS_POS_CURRENT → Number of drawings for goods during this month on the previous credit.
CNT_INSTALMENT_MATURE_CUM → Number of paid installments on the previous credit.
NAME_CONTRACT_STATUS → Contract status during the month.
SK_DPD → DPD (days past due) during the month of previous credit.
SK_DPD_DEF → DPD during the month with tolerance (debts with low loan amounts are ignored) of the previous credit.
# Replacing the missing values with the means of each column
creditcard_bal['AMT_DRAWINGS_ATM_CURRENT'].fillna(creditcard_bal['AMT_DRAWINGS_ATM_CURRENT'].mean(), inplace = True)
creditcard_bal['AMT_DRAWINGS_OTHER_CURRENT'].fillna(creditcard_bal['AMT_DRAWINGS_OTHER_CURRENT'].mean(), inplace = True)
creditcard_bal['AMT_DRAWINGS_POS_CURRENT'].fillna(creditcard_bal['AMT_DRAWINGS_POS_CURRENT'].mean(), inplace = True)
creditcard_bal['AMT_INST_MIN_REGULARITY'].fillna(creditcard_bal['AMT_INST_MIN_REGULARITY'].mean(), inplace = True)
creditcard_bal['AMT_PAYMENT_CURRENT'].fillna(creditcard_bal['AMT_PAYMENT_CURRENT'].mean(), inplace = True)
creditcard_bal['CNT_DRAWINGS_ATM_CURRENT'].fillna(creditcard_bal['CNT_DRAWINGS_ATM_CURRENT'].mean(), inplace = True)
creditcard_bal['CNT_DRAWINGS_OTHER_CURRENT'].fillna(creditcard_bal['CNT_DRAWINGS_OTHER_CURRENT'].mean(), inplace = True)
creditcard_bal['CNT_DRAWINGS_POS_CURRENT'].fillna(creditcard_bal['CNT_DRAWINGS_POS_CURRENT'].mean(), inplace = True)
creditcard_bal['CNT_INSTALMENT_MATURE_CUM'].fillna(creditcard_bal['CNT_INSTALMENT_MATURE_CUM'].mean(), inplace = True)
# checking for missing values in the columns
creditcard_bal.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
MONTHS_BALANCE 0
AMT_BALANCE 0
AMT_CREDIT_LIMIT_ACTUAL 0
AMT_DRAWINGS_ATM_CURRENT 0
AMT_DRAWINGS_CURRENT 0
AMT_DRAWINGS_OTHER_CURRENT 0
AMT_DRAWINGS_POS_CURRENT 0
AMT_INST_MIN_REGULARITY 0
AMT_PAYMENT_CURRENT 0
AMT_PAYMENT_TOTAL_CURRENT 0
AMT_RECEIVABLE_PRINCIPAL 0
AMT_RECIVABLE 0
AMT_TOTAL_RECEIVABLE 0
CNT_DRAWINGS_ATM_CURRENT 0
CNT_DRAWINGS_CURRENT 0
CNT_DRAWINGS_OTHER_CURRENT 0
CNT_DRAWINGS_POS_CURRENT 0
CNT_INSTALMENT_MATURE_CUM 0
NAME_CONTRACT_STATUS 0
SK_DPD 0
SK_DPD_DEF 0
dtype: int64
#Checking the no. of unique SK_ID_CURR values
count1 = creditcard_bal["SK_ID_CURR"].unique()
count1.shape
(103558,)
For each unique SK_ID_CURR there are duplicate rows that provide the data for multiple dates so we need to keep only that row that has the most recent information and drop the old information. In this dataset we will keep only those rows that have the max MONTHS_BALANCE (least negative values as to the latest Month of balance relative to application date (-1 means the freshest balance date)) and delete the other rows for each unique SK_ID_CURR.
creditcard_bal = creditcard_bal.groupby('SK_ID_CURR', group_keys=False).apply(lambda x: x.loc[x.MONTHS_BALANCE.idxmax()])
creditcard_bal.shape
(103558, 23)
creditcard_bal['index'] = creditcard_bal.index
creditcard_bal.index.name = None
creditcard_bal.drop(['SK_ID_PREV', 'index'], axis = 1, inplace = True)
creditcard_bal.head()
| SK_ID_CURR | MONTHS_BALANCE | AMT_BALANCE | AMT_CREDIT_LIMIT_ACTUAL | AMT_DRAWINGS_ATM_CURRENT | AMT_DRAWINGS_CURRENT | AMT_DRAWINGS_OTHER_CURRENT | AMT_DRAWINGS_POS_CURRENT | AMT_INST_MIN_REGULARITY | AMT_PAYMENT_CURRENT | AMT_PAYMENT_TOTAL_CURRENT | AMT_RECEIVABLE_PRINCIPAL | AMT_RECIVABLE | AMT_TOTAL_RECEIVABLE | CNT_DRAWINGS_ATM_CURRENT | CNT_DRAWINGS_CURRENT | CNT_DRAWINGS_OTHER_CURRENT | CNT_DRAWINGS_POS_CURRENT | CNT_INSTALMENT_MATURE_CUM | NAME_CONTRACT_STATUS | SK_DPD | SK_DPD_DEF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100006 | 100006 | -1 | 0.000000 | 270000 | 5961.324822 | 0.000000 | 288.169582 | 2968.804848 | 0.000000 | 10280.537702 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.309449 | 0 | 0.004812 | 0.559479 | 0.000000 | Active | 0 | 0 |
| 100011 | 100011 | -2 | 0.000000 | 90000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 563.355000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 | 0.000000 | 0.000000 | 33.000000 | Active | 0 | 0 |
| 100013 | 100013 | -1 | 0.000000 | 45000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 274.320000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 | 0.000000 | 0.000000 | 22.000000 | Active | 0 | 0 |
| 100021 | 100021 | -2 | 0.000000 | 675000 | 5961.324822 | 0.000000 | 288.169582 | 2968.804848 | 0.000000 | 10280.537702 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.309449 | 0 | 0.004812 | 0.559479 | 0.000000 | Completed | 0 | 0 |
| 100023 | 100023 | -4 | 0.000000 | 225000 | 5961.324822 | 0.000000 | 288.169582 | 2968.804848 | 0.000000 | 10280.537702 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.309449 | 0 | 0.004812 | 0.559479 | 0.000000 | Active | 0 | 0 |
The creditcard_balance data set is now clean with no missing values and duplicates and is ready to be merged with the other datasets.
STEP 3: Loading and preparing the installment_payments data set
instal_paymt = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/installments_payments.csv')
instal_paymt.head()
| SK_ID_PREV | SK_ID_CURR | NUM_INSTALMENT_VERSION | NUM_INSTALMENT_NUMBER | DAYS_INSTALMENT | DAYS_ENTRY_PAYMENT | AMT_INSTALMENT | AMT_PAYMENT | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1054186 | 161674 | 1.000000 | 6 | -1180.000000 | -1187.000000 | 6948.360000 | 6948.360000 |
| 1 | 1330831 | 151639 | 0.000000 | 34 | -2156.000000 | -2156.000000 | 1716.525000 | 1716.525000 |
| 2 | 2085231 | 193053 | 2.000000 | 1 | -63.000000 | -63.000000 | 25425.000000 | 25425.000000 |
| 3 | 2452527 | 199697 | 1.000000 | 3 | -2418.000000 | -2426.000000 | 24350.130000 | 24350.130000 |
| 4 | 2714724 | 167756 | 1.000000 | 2 | -1383.000000 | -1366.000000 | 2165.040000 | 2160.585000 |
instal_paymt.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13605401 entries, 0 to 13605400
Data columns (total 8 columns):
# Column Dtype
--- ------ -----
0 SK_ID_PREV int64
1 SK_ID_CURR int64
2 NUM_INSTALMENT_VERSION float64
3 NUM_INSTALMENT_NUMBER int64
4 DAYS_INSTALMENT float64
5 DAYS_ENTRY_PAYMENT float64
6 AMT_INSTALMENT float64
7 AMT_PAYMENT float64
dtypes: float64(5), int64(3)
memory usage: 830.4 MB
# checking for missing values in each column
instal_paymt.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
NUM_INSTALMENT_VERSION 0
NUM_INSTALMENT_NUMBER 0
DAYS_INSTALMENT 0
DAYS_ENTRY_PAYMENT 2905
AMT_INSTALMENT 0
AMT_PAYMENT 2905
dtype: int64
instal_paymt.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SK_ID_PREV | 13605401.000000 | 1903364.969549 | 536202.905546 | 1000001.000000 | 1434191.000000 | 1896520.000000 | 2369094.000000 | 2843499.000000 |
| SK_ID_CURR | 13605401.000000 | 278444.881738 | 102718.310411 | 100001.000000 | 189639.000000 | 278685.000000 | 367530.000000 | 456255.000000 |
| NUM_INSTALMENT_VERSION | 13605401.000000 | 0.856637 | 1.035216 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 178.000000 |
| NUM_INSTALMENT_NUMBER | 13605401.000000 | 18.870896 | 26.664067 | 1.000000 | 4.000000 | 8.000000 | 19.000000 | 277.000000 |
| DAYS_INSTALMENT | 13605401.000000 | -1042.269992 | 800.946284 | -2922.000000 | -1654.000000 | -818.000000 | -361.000000 | -1.000000 |
| DAYS_ENTRY_PAYMENT | 13602496.000000 | -1051.113684 | 800.585883 | -4921.000000 | -1662.000000 | -827.000000 | -370.000000 | -1.000000 |
| AMT_INSTALMENT | 13605401.000000 | 17050.906989 | 50570.254429 | 0.000000 | 4226.085000 | 8884.080000 | 16710.210000 | 3771487.845000 |
| AMT_PAYMENT | 13602496.000000 | 17238.223250 | 54735.783981 | 0.000000 | 3398.265000 | 8125.515000 | 16108.425000 | 3771487.845000 |
DAYS_INSTALMENT, DAYS_ENTRY_PAYMENT has negative values.
Description of The Dataset:
SK_ID_PREV → ID of previous credit in Home Credit related to loan in our sample. (One loan in our sample can have 0,1,2 or more previous loans in Home Credit).
SK_ID_CURR → ID of loan in our sample.
NUM_INSTALMENT_VERSION → Version of installment calendar (0 is for credit card) of previous credit. Change of installment version from month to month signifies that some parameter of payment calendar has changed.
NUM_INSTALMENT_NUMBER → On which installment we observe payment.
DAYS_INSTALMENT → When the installment of previous credit was supposed to be paid (relative to application date of current loan).
DAYS_ENTRY_PAYMENT → When was the installments of previous credit paid actually (relative to application date of current loan).
AMT_INSTALMENT → What was the prescribed installment amount of previous credit on this installment.
AMT_PAYMENT → What the client actually paid on previous credit on this installment.
# Replacing the missing values with the means of each column
instal_paymt['DAYS_ENTRY_PAYMENT'].fillna(instal_paymt['DAYS_ENTRY_PAYMENT'].mean(), inplace = True)
instal_paymt['AMT_PAYMENT'].fillna(instal_paymt['AMT_PAYMENT'].mean(), inplace = True)
# checking for missing values in each column
instal_paymt.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
NUM_INSTALMENT_VERSION 0
NUM_INSTALMENT_NUMBER 0
DAYS_INSTALMENT 0
DAYS_ENTRY_PAYMENT 0
AMT_INSTALMENT 0
AMT_PAYMENT 0
dtype: int64
#Checking the no. of unique SK_ID_CURR values
count2 = instal_paymt["SK_ID_CURR"].unique()
count2.shape
(339587,)
For each unique SK_ID_CURR there are duplicate rows that provide the data for multiple dates so we need to keep only that row that has the most recent information and drop the old information. In this dataset we will keep only those rows that have the max DAYS_INSTALMENT When the installment of previous credit was supposed to be paid (relative to application date of current loan, -1 means closer to the application date)) and delete the other rows for each unique SK_ID_CURR.
instal_paymt = instal_paymt.groupby('SK_ID_CURR', group_keys=False).apply(lambda x: x.loc[x.DAYS_INSTALMENT.idxmax()])
instal_paymt.shape
(339587, 8)
instal_paymt['index'] = instal_paymt.index
instal_paymt.index.name = None
instal_paymt.drop(['SK_ID_PREV', 'index'], axis = 1, inplace = True)
instal_paymt.head()
| SK_ID_CURR | NUM_INSTALMENT_VERSION | NUM_INSTALMENT_NUMBER | DAYS_INSTALMENT | DAYS_ENTRY_PAYMENT | AMT_INSTALMENT | AMT_PAYMENT | |
|---|---|---|---|---|---|---|---|
| 100001 | 100001.000000 | 2.000000 | 4.000000 | -1619.000000 | -1628.000000 | 17397.900000 | 17397.900000 |
| 100002 | 100002.000000 | 2.000000 | 19.000000 | -25.000000 | -49.000000 | 53093.745000 | 53093.745000 |
| 100003 | 100003.000000 | 2.000000 | 7.000000 | -536.000000 | -544.000000 | 560835.360000 | 560835.360000 |
| 100004 | 100004.000000 | 2.000000 | 3.000000 | -724.000000 | -727.000000 | 10573.965000 | 10573.965000 |
| 100005 | 100005.000000 | 2.000000 | 9.000000 | -466.000000 | -470.000000 | 17656.245000 | 17656.245000 |
The installment_payments data set is now clean with no missing values and duplicates and is ready to be merged with the other datasets.
STEP 4: Loading and preparing the previous_application data set
prev_appln = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/previous_application.csv')
prev_appln.head()
| SK_ID_PREV | SK_ID_CURR | NAME_CONTRACT_TYPE | AMT_ANNUITY | AMT_APPLICATION | AMT_CREDIT | AMT_DOWN_PAYMENT | AMT_GOODS_PRICE | WEEKDAY_APPR_PROCESS_START | HOUR_APPR_PROCESS_START | FLAG_LAST_APPL_PER_CONTRACT | NFLAG_LAST_APPL_IN_DAY | RATE_DOWN_PAYMENT | RATE_INTEREST_PRIMARY | RATE_INTEREST_PRIVILEGED | NAME_CASH_LOAN_PURPOSE | NAME_CONTRACT_STATUS | DAYS_DECISION | NAME_PAYMENT_TYPE | CODE_REJECT_REASON | NAME_TYPE_SUITE | NAME_CLIENT_TYPE | NAME_GOODS_CATEGORY | NAME_PORTFOLIO | NAME_PRODUCT_TYPE | CHANNEL_TYPE | SELLERPLACE_AREA | NAME_SELLER_INDUSTRY | CNT_PAYMENT | NAME_YIELD_GROUP | PRODUCT_COMBINATION | DAYS_FIRST_DRAWING | DAYS_FIRST_DUE | DAYS_LAST_DUE_1ST_VERSION | DAYS_LAST_DUE | DAYS_TERMINATION | NFLAG_INSURED_ON_APPROVAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2030495 | 271877 | Consumer loans | 1730.430000 | 17145.000000 | 17145.000000 | 0.000000 | 17145.000000 | SATURDAY | 15 | Y | 1 | 0.000000 | 0.182832 | 0.867336 | XAP | Approved | -73 | Cash through the bank | XAP | NaN | Repeater | Mobile | POS | XNA | Country-wide | 35 | Connectivity | 12.000000 | middle | POS mobile with interest | 365243.000000 | -42.000000 | 300.000000 | -42.000000 | -37.000000 | 0.000000 |
| 1 | 2802425 | 108129 | Cash loans | 25188.615000 | 607500.000000 | 679671.000000 | nan | 607500.000000 | THURSDAY | 11 | Y | 1 | nan | nan | nan | XNA | Approved | -164 | XNA | XAP | Unaccompanied | Repeater | XNA | Cash | x-sell | Contact center | -1 | XNA | 36.000000 | low_action | Cash X-Sell: low | 365243.000000 | -134.000000 | 916.000000 | 365243.000000 | 365243.000000 | 1.000000 |
| 2 | 2523466 | 122040 | Cash loans | 15060.735000 | 112500.000000 | 136444.500000 | nan | 112500.000000 | TUESDAY | 11 | Y | 1 | nan | nan | nan | XNA | Approved | -301 | Cash through the bank | XAP | Spouse, partner | Repeater | XNA | Cash | x-sell | Credit and cash offices | -1 | XNA | 12.000000 | high | Cash X-Sell: high | 365243.000000 | -271.000000 | 59.000000 | 365243.000000 | 365243.000000 | 1.000000 |
| 3 | 2819243 | 176158 | Cash loans | 47041.335000 | 450000.000000 | 470790.000000 | nan | 450000.000000 | MONDAY | 7 | Y | 1 | nan | nan | nan | XNA | Approved | -512 | Cash through the bank | XAP | NaN | Repeater | XNA | Cash | x-sell | Credit and cash offices | -1 | XNA | 12.000000 | middle | Cash X-Sell: middle | 365243.000000 | -482.000000 | -152.000000 | -182.000000 | -177.000000 | 1.000000 |
| 4 | 1784265 | 202054 | Cash loans | 31924.395000 | 337500.000000 | 404055.000000 | nan | 337500.000000 | THURSDAY | 9 | Y | 1 | nan | nan | nan | Repairs | Refused | -781 | Cash through the bank | HC | NaN | Repeater | XNA | Cash | walk-in | Credit and cash offices | -1 | XNA | 24.000000 | high | Cash Street: high | nan | nan | nan | nan | nan | nan |
prev_appln.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1670214 entries, 0 to 1670213
Data columns (total 37 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SK_ID_PREV 1670214 non-null int64
1 SK_ID_CURR 1670214 non-null int64
2 NAME_CONTRACT_TYPE 1670214 non-null object
3 AMT_ANNUITY 1297979 non-null float64
4 AMT_APPLICATION 1670214 non-null float64
5 AMT_CREDIT 1670213 non-null float64
6 AMT_DOWN_PAYMENT 774370 non-null float64
7 AMT_GOODS_PRICE 1284699 non-null float64
8 WEEKDAY_APPR_PROCESS_START 1670214 non-null object
9 HOUR_APPR_PROCESS_START 1670214 non-null int64
10 FLAG_LAST_APPL_PER_CONTRACT 1670214 non-null object
11 NFLAG_LAST_APPL_IN_DAY 1670214 non-null int64
12 RATE_DOWN_PAYMENT 774370 non-null float64
13 RATE_INTEREST_PRIMARY 5951 non-null float64
14 RATE_INTEREST_PRIVILEGED 5951 non-null float64
15 NAME_CASH_LOAN_PURPOSE 1670214 non-null object
16 NAME_CONTRACT_STATUS 1670214 non-null object
17 DAYS_DECISION 1670214 non-null int64
18 NAME_PAYMENT_TYPE 1670214 non-null object
19 CODE_REJECT_REASON 1670214 non-null object
20 NAME_TYPE_SUITE 849809 non-null object
21 NAME_CLIENT_TYPE 1670214 non-null object
22 NAME_GOODS_CATEGORY 1670214 non-null object
23 NAME_PORTFOLIO 1670214 non-null object
24 NAME_PRODUCT_TYPE 1670214 non-null object
25 CHANNEL_TYPE 1670214 non-null object
26 SELLERPLACE_AREA 1670214 non-null int64
27 NAME_SELLER_INDUSTRY 1670214 non-null object
28 CNT_PAYMENT 1297984 non-null float64
29 NAME_YIELD_GROUP 1670214 non-null object
30 PRODUCT_COMBINATION 1669868 non-null object
31 DAYS_FIRST_DRAWING 997149 non-null float64
32 DAYS_FIRST_DUE 997149 non-null float64
33 DAYS_LAST_DUE_1ST_VERSION 997149 non-null float64
34 DAYS_LAST_DUE 997149 non-null float64
35 DAYS_TERMINATION 997149 non-null float64
36 NFLAG_INSURED_ON_APPROVAL 997149 non-null float64
dtypes: float64(15), int64(6), object(16)
memory usage: 471.5+ MB
# checking for missing values
prev_appln.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
NAME_CONTRACT_TYPE 0
AMT_ANNUITY 372235
AMT_APPLICATION 0
AMT_CREDIT 1
AMT_DOWN_PAYMENT 895844
AMT_GOODS_PRICE 385515
WEEKDAY_APPR_PROCESS_START 0
HOUR_APPR_PROCESS_START 0
FLAG_LAST_APPL_PER_CONTRACT 0
NFLAG_LAST_APPL_IN_DAY 0
RATE_DOWN_PAYMENT 895844
RATE_INTEREST_PRIMARY 1664263
RATE_INTEREST_PRIVILEGED 1664263
NAME_CASH_LOAN_PURPOSE 0
NAME_CONTRACT_STATUS 0
DAYS_DECISION 0
NAME_PAYMENT_TYPE 0
CODE_REJECT_REASON 0
NAME_TYPE_SUITE 820405
NAME_CLIENT_TYPE 0
NAME_GOODS_CATEGORY 0
NAME_PORTFOLIO 0
NAME_PRODUCT_TYPE 0
CHANNEL_TYPE 0
SELLERPLACE_AREA 0
NAME_SELLER_INDUSTRY 0
CNT_PAYMENT 372230
NAME_YIELD_GROUP 0
PRODUCT_COMBINATION 346
DAYS_FIRST_DRAWING 673065
DAYS_FIRST_DUE 673065
DAYS_LAST_DUE_1ST_VERSION 673065
DAYS_LAST_DUE 673065
DAYS_TERMINATION 673065
NFLAG_INSURED_ON_APPROVAL 673065
dtype: int64
# Finding the % of missing values
round(100*(prev_appln.isnull().sum()/len(prev_appln.index)),2)
SK_ID_PREV 0.000000
SK_ID_CURR 0.000000
NAME_CONTRACT_TYPE 0.000000
AMT_ANNUITY 22.290000
AMT_APPLICATION 0.000000
AMT_CREDIT 0.000000
AMT_DOWN_PAYMENT 53.640000
AMT_GOODS_PRICE 23.080000
WEEKDAY_APPR_PROCESS_START 0.000000
HOUR_APPR_PROCESS_START 0.000000
FLAG_LAST_APPL_PER_CONTRACT 0.000000
NFLAG_LAST_APPL_IN_DAY 0.000000
RATE_DOWN_PAYMENT 53.640000
RATE_INTEREST_PRIMARY 99.640000
RATE_INTEREST_PRIVILEGED 99.640000
NAME_CASH_LOAN_PURPOSE 0.000000
NAME_CONTRACT_STATUS 0.000000
DAYS_DECISION 0.000000
NAME_PAYMENT_TYPE 0.000000
CODE_REJECT_REASON 0.000000
NAME_TYPE_SUITE 49.120000
NAME_CLIENT_TYPE 0.000000
NAME_GOODS_CATEGORY 0.000000
NAME_PORTFOLIO 0.000000
NAME_PRODUCT_TYPE 0.000000
CHANNEL_TYPE 0.000000
SELLERPLACE_AREA 0.000000
NAME_SELLER_INDUSTRY 0.000000
CNT_PAYMENT 22.290000
NAME_YIELD_GROUP 0.000000
PRODUCT_COMBINATION 0.020000
DAYS_FIRST_DRAWING 40.300000
DAYS_FIRST_DUE 40.300000
DAYS_LAST_DUE_1ST_VERSION 40.300000
DAYS_LAST_DUE 40.300000
DAYS_TERMINATION 40.300000
NFLAG_INSURED_ON_APPROVAL 40.300000
dtype: float64
#Assigning NULL percentage value to variable
prevapp_null = round(100*(prev_appln.isnull().sum()/len(prev_appln.index)),2)
# find columns with more than 50% missing values
columnprev = prevapp_null[prevapp_null >= 50].index
# drop columns with high null percentage
prev_appln.drop(columnprev,axis = 1,inplace = True)
#check null percentage after dropping
round(100*(prev_appln.isnull().sum()/len(prev_appln.index)),2)
SK_ID_PREV 0.000000
SK_ID_CURR 0.000000
NAME_CONTRACT_TYPE 0.000000
AMT_ANNUITY 22.290000
AMT_APPLICATION 0.000000
AMT_CREDIT 0.000000
AMT_GOODS_PRICE 23.080000
WEEKDAY_APPR_PROCESS_START 0.000000
HOUR_APPR_PROCESS_START 0.000000
FLAG_LAST_APPL_PER_CONTRACT 0.000000
NFLAG_LAST_APPL_IN_DAY 0.000000
NAME_CASH_LOAN_PURPOSE 0.000000
NAME_CONTRACT_STATUS 0.000000
DAYS_DECISION 0.000000
NAME_PAYMENT_TYPE 0.000000
CODE_REJECT_REASON 0.000000
NAME_TYPE_SUITE 49.120000
NAME_CLIENT_TYPE 0.000000
NAME_GOODS_CATEGORY 0.000000
NAME_PORTFOLIO 0.000000
NAME_PRODUCT_TYPE 0.000000
CHANNEL_TYPE 0.000000
SELLERPLACE_AREA 0.000000
NAME_SELLER_INDUSTRY 0.000000
CNT_PAYMENT 22.290000
NAME_YIELD_GROUP 0.000000
PRODUCT_COMBINATION 0.020000
DAYS_FIRST_DRAWING 40.300000
DAYS_FIRST_DUE 40.300000
DAYS_LAST_DUE_1ST_VERSION 40.300000
DAYS_LAST_DUE 40.300000
DAYS_TERMINATION 40.300000
NFLAG_INSURED_ON_APPROVAL 40.300000
dtype: float64
# checking the shape of the dataframe after the columns are dropped
prev_appln.shape
(1670214, 33)
4 columns have been dropped.
#getting the list of columns that have missing values > 0
null_count = prev_appln.isnull().sum()
null_ap = null_count[null_count > 0]
null_ap
AMT_ANNUITY 372235
AMT_CREDIT 1
AMT_GOODS_PRICE 385515
NAME_TYPE_SUITE 820405
CNT_PAYMENT 372230
PRODUCT_COMBINATION 346
DAYS_FIRST_DRAWING 673065
DAYS_FIRST_DUE 673065
DAYS_LAST_DUE_1ST_VERSION 673065
DAYS_LAST_DUE 673065
DAYS_TERMINATION 673065
NFLAG_INSURED_ON_APPROVAL 673065
dtype: int64
prev_appln.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SK_ID_PREV | 1670214.000000 | 1923089.135331 | 532597.958696 | 1000001.000000 | 1461857.250000 | 1923110.500000 | 2384279.750000 | 2845382.000000 |
| SK_ID_CURR | 1670214.000000 | 278357.174099 | 102814.823849 | 100001.000000 | 189329.000000 | 278714.500000 | 367514.000000 | 456255.000000 |
| AMT_ANNUITY | 1297979.000000 | 15955.120659 | 14782.137335 | 0.000000 | 6321.780000 | 11250.000000 | 20658.420000 | 418058.145000 |
| AMT_APPLICATION | 1670214.000000 | 175233.860360 | 292779.762387 | 0.000000 | 18720.000000 | 71046.000000 | 180360.000000 | 6905160.000000 |
| AMT_CREDIT | 1670213.000000 | 196114.021218 | 318574.616546 | 0.000000 | 24160.500000 | 80541.000000 | 216418.500000 | 6905160.000000 |
| AMT_GOODS_PRICE | 1284699.000000 | 227847.279283 | 315396.557937 | 0.000000 | 50841.000000 | 112320.000000 | 234000.000000 | 6905160.000000 |
| HOUR_APPR_PROCESS_START | 1670214.000000 | 12.484182 | 3.334028 | 0.000000 | 10.000000 | 12.000000 | 15.000000 | 23.000000 |
| NFLAG_LAST_APPL_IN_DAY | 1670214.000000 | 0.996468 | 0.059330 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| DAYS_DECISION | 1670214.000000 | -880.679668 | 779.099667 | -2922.000000 | -1300.000000 | -581.000000 | -280.000000 | -1.000000 |
| SELLERPLACE_AREA | 1670214.000000 | 313.951115 | 7127.443459 | -1.000000 | -1.000000 | 3.000000 | 82.000000 | 4000000.000000 |
| CNT_PAYMENT | 1297984.000000 | 16.054082 | 14.567288 | 0.000000 | 6.000000 | 12.000000 | 24.000000 | 84.000000 |
| DAYS_FIRST_DRAWING | 997149.000000 | 342209.855039 | 88916.115834 | -2922.000000 | 365243.000000 | 365243.000000 | 365243.000000 | 365243.000000 |
| DAYS_FIRST_DUE | 997149.000000 | 13826.269337 | 72444.869708 | -2892.000000 | -1628.000000 | -831.000000 | -411.000000 | 365243.000000 |
| DAYS_LAST_DUE_1ST_VERSION | 997149.000000 | 33767.774054 | 106857.034789 | -2801.000000 | -1242.000000 | -361.000000 | 129.000000 | 365243.000000 |
| DAYS_LAST_DUE | 997149.000000 | 76582.403064 | 149647.415123 | -2889.000000 | -1314.000000 | -537.000000 | -74.000000 | 365243.000000 |
| DAYS_TERMINATION | 997149.000000 | 81992.343838 | 153303.516729 | -2874.000000 | -1270.000000 | -499.000000 | -44.000000 | 365243.000000 |
| NFLAG_INSURED_ON_APPROVAL | 997149.000000 | 0.332570 | 0.471134 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 |
DAYS_DECISION, SELLERPLACE_AREA, DAYS_FIRST_DRAWING, DAYS_FIRST_DUE, DAYS_LAST_DUE_1ST_VERSION, DAYS_LAST_DUE, DAYS_TERMINATION have negative values.
Description of The Dataset:
SK_ID_PREV → ID of previous credit in Home Credit related to loan in our sample. (One loan in our sample can have 0,1,2 or more previous loans in Home Credit).
SK_ID_CURR → ID of loan in our sample.
NAME_CONTRACT_TYPE → Identification if loan is cash or revolving.
AMT_ANNUITY → Loan annuity.
AMT_APPLICATION → For how much credit did client ask on the previous application.
AMT_CREDIT → Credit amount of the loan.
AMT_GOODS_PRICE → For consumer loans it is the price of the goods for which the loan is given.
WEEKDAY_APPR_PROCESS_START → On which day of the week did the client apply for the loan.
HOUR_APPR_PROCESS_START → Approximately at what hour did the client apply for the loan.
FLAG_LAST_APPL_PER_CONTRACT → Flag if it was last application for the previous contract. Sometimes by mistake of client or our clerk there could be more applications for one single contract.
NFLAG_LAST_APPL_IN_DAY → Flag if the application was the last application per day of the client. Sometimes clients apply for more applications a day. Rarely it could also be error in our system that one application is in the database twice.
NAME_CASH_LOAN_PURPOSE → Purpose of the cash loan.
NAME_CONTRACT_STATUS → Contract status during the month.
DAYS_DECISION → Relative to current application when was the decision about previous application made.
NAME_PAYMENT_TYPE → Payment method that client chose to pay for the previous application.
CODE_REJECT_REASON → Why was the previous application rejected.
NAME_TYPE_SUITE Who was accompanying client when he was applying for the loan.
NAME_CLIENT_TYPE → Was the client old or new client when applying for the previous application.
NAME_GOODS_CATEGORY → What kind of goods did the client apply for in the previous application.
NAME_PORTFOLIO → Was the previous application for CASH, POS, CAR, …
NAME_PRODUCT_TYPE → Was the previous application x-sell o walk-in.
CHANNEL_TYPE → Through which channel we acquired the client on the previous application.
SELLERPLACE_AREA → Selling area of seller place of the previous application.
NAME_SELLER_INDUSTRY → The industry of the seller.
CNT_PAYMENT → Term of previous credit at application of the previous application.
NAME_YIELD_GROUP → Grouped interest rate into small medium and high of the previous application.
PRODUCT_COMBINATION → Detailed product combination of the previous application.
DAYS_FIRST_DRAWING → Relative to application date of current application when was the first disbursement of the previous application.
DAYS_FIRST_DUE → Relative to application date of current application when was the first due supposed to be of the previous application.
DAYS_LAST_DUE_1ST_VERSION → Relative to application date of current application when was the first due of the previous application.
DAYS_LAST_DUE → Relative to application date of current application when was the last due date of the previous application.
DAYS_TERMINATION → Relative to application date of current application when was the expected termination of the previous application. Description of the data set.
SK_ID_PREV → ID of previous credit in Home Credit related to loan in our sample. (One loan in our sample can have 0,1,2 or more previous loans in Home Credit).
SK_ID_CURR → ID of loan in our sample.
NAME_CONTRACT_TYPE Identification if loan is cash or revolving.
AMT_ANNUITY → Loan annuity.
AMT_APPLICATION → For how much credit did client ask on the previous application.
AMT_CREDIT → Credit amount of the loan.
AMT_GOODS_PRICE → For consumer loans it is the price of the goods for which the loan is given.
WEEKDAY_APPR_PROCESS_START → On which day of the week did the client apply for the loan.
HOUR_APPR_PROCESS_START → Approximately at what hour did the client apply for the loan.
FLAG_LAST_APPL_PER_CONTRACT → Flag if it was last application for the previous contract. Sometimes by mistake of client or our clerk there could be more applications for one single contract.
NFLAG_LAST_APPL_IN_DAY → Flag if the application was the last application per day of the client. Sometimes clients apply for more applications a day. Rarely it could also be error in our system that one application is in the database twice.
NAME_CASH_LOAN_PURPOSE → Purpose of the cash loan.
NAME_CONTRACT_STATUS → Contract status during the month.
DAYS_DECISION → Relative to current application when was the decision about previous application made.
NAME_PAYMENT_TYPE → Payment method that client chose to pay for the previous application.
CODE_REJECT_REASON → Why was the previous application rejected.
NAME_TYPE_SUITE → Who was accompanying client when he was applying for the loan.
NAME_CLIENT_TYPE → Was the client old or new client when applying for the previous application.
NAME_GOODS_CATEGORY → What kind of goods did the client apply for in the previous application.
NAME_PORTFOLIO → Was the previous application for CASH, POS, CAR, …
NAME_PRODUCT_TYPE → Was the previous application x-sell o walk-in.
CHANNEL_TYPE → Through which channel we acquired the client on the previous application.
SELLERPLACE_AREA → Selling area of seller place of the previous application.
NAME_SELLER_INDUSTRY → The industry of the seller.
CNT_PAYMENT → Term of previous credit at application of the previous application.
NAME_YIELD_GROUP → Grouped interest rate into small medium and high of the previous application.
PRODUCT_COMBINATION → Detailed product combination of the previous application.
DAYS_FIRST_DRAWING → Relative to application date of current application when was the first disbursement of the previous application.
DAYS_FIRST_DUE → Relative to application date of current application when was the first due supposed to be of the previous application.
DAYS_LAST_DUE_1ST_VERSION → Relative to application date of current application when was the first due of the previous application.
DAYS_LAST_DUE → Relative to application date of current application when was the last due date of the previous application.
DAYS_TERMINATION → Relative to application date of current application when was the expected termination of the previous application.
NFLAG_INSURED_ON_APPROVAL → Did the client requested insurance during the previous application.
NFLAG_INSURED_ON_APPROVAL → Did the client requested insurance during the previous application.
# Replacing the missing values for the columns
# For the numerical values, replacing the missing values with mean of their respective columns
prev_appln['AMT_ANNUITY'].fillna(prev_appln['AMT_ANNUITY'].mean(), inplace = True)
prev_appln['AMT_CREDIT'].fillna(prev_appln['AMT_CREDIT'].mean(), inplace = True)
prev_appln['AMT_GOODS_PRICE'].fillna(prev_appln['AMT_GOODS_PRICE'].mean(), inplace = True)
prev_appln['CNT_PAYMENT'].fillna(prev_appln['CNT_PAYMENT'].mean(), inplace = True)
prev_appln['DAYS_FIRST_DRAWING'].fillna(prev_appln['DAYS_FIRST_DRAWING'].mean(), inplace = True)
prev_appln['DAYS_FIRST_DUE'].fillna(prev_appln['DAYS_FIRST_DUE'].mean(), inplace = True)
prev_appln['DAYS_LAST_DUE_1ST_VERSION'].fillna(prev_appln['DAYS_LAST_DUE_1ST_VERSION'].mean(), inplace = True)
prev_appln['DAYS_LAST_DUE'].fillna(prev_appln['DAYS_LAST_DUE'].mean(), inplace = True)
prev_appln['DAYS_TERMINATION'].fillna(prev_appln['DAYS_TERMINATION'].mean(), inplace = True)
prev_appln['NFLAG_INSURED_ON_APPROVAL'].fillna(prev_appln['NFLAG_INSURED_ON_APPROVAL'].mean(), inplace = True)
# For the categorical values, replacing the missing values with most frequently appearing values
# Getting the mode of the categorical columns and for no of family members
print(prev_appln['NAME_TYPE_SUITE'].mode())
print(prev_appln['PRODUCT_COMBINATION'].mode())
0 Unaccompanied
dtype: object
0 Cash
dtype: object
# Replacing the missing values for the below with the most frequently appearing values from above
prev_appln.loc[pd.isnull(prev_appln['NAME_TYPE_SUITE']),'NAME_TYPE_SUITE'] = "Unaccompanied"
prev_appln.loc[pd.isnull(prev_appln['PRODUCT_COMBINATION']),'PRODUCT_COMBINATION'] = "Cash"
prev_appln.isnull().sum()
SK_ID_PREV 0
SK_ID_CURR 0
NAME_CONTRACT_TYPE 0
AMT_ANNUITY 0
AMT_APPLICATION 0
AMT_CREDIT 0
AMT_GOODS_PRICE 0
WEEKDAY_APPR_PROCESS_START 0
HOUR_APPR_PROCESS_START 0
FLAG_LAST_APPL_PER_CONTRACT 0
NFLAG_LAST_APPL_IN_DAY 0
NAME_CASH_LOAN_PURPOSE 0
NAME_CONTRACT_STATUS 0
DAYS_DECISION 0
NAME_PAYMENT_TYPE 0
CODE_REJECT_REASON 0
NAME_TYPE_SUITE 0
NAME_CLIENT_TYPE 0
NAME_GOODS_CATEGORY 0
NAME_PORTFOLIO 0
NAME_PRODUCT_TYPE 0
CHANNEL_TYPE 0
SELLERPLACE_AREA 0
NAME_SELLER_INDUSTRY 0
CNT_PAYMENT 0
NAME_YIELD_GROUP 0
PRODUCT_COMBINATION 0
DAYS_FIRST_DRAWING 0
DAYS_FIRST_DUE 0
DAYS_LAST_DUE_1ST_VERSION 0
DAYS_LAST_DUE 0
DAYS_TERMINATION 0
NFLAG_INSURED_ON_APPROVAL 0
dtype: int64
#Checking the no. of unique SK_ID_CURR values
count3 = prev_appln["SK_ID_CURR"].unique()
count3.shape
(338857,)
For each unique SK_ID_CURR there are duplicate rows that provide the data for multiple dates so we need to keep only that row that has the most recent information and drop the old information. In this dataset we will keep only those rows that have the max DAYS_DECISION which is Relative to current application when was the decision about previous application made(-1 means the freshest balance date)) and delete the other rows for each unique SK_ID_CURR.
prev_appln = prev_appln.groupby('SK_ID_CURR', group_keys=False).apply(lambda x: x.loc[x.DAYS_DECISION.idxmax()])
prev_appln.shape
(338857, 33)
prev_appln['index'] = prev_appln.index
prev_appln.index.name = None
prev_appln.drop(['SK_ID_PREV', 'index'], axis = 1, inplace = True)
prev_appln.head()
| SK_ID_CURR | NAME_CONTRACT_TYPE | AMT_ANNUITY | AMT_APPLICATION | AMT_CREDIT | AMT_GOODS_PRICE | WEEKDAY_APPR_PROCESS_START | HOUR_APPR_PROCESS_START | FLAG_LAST_APPL_PER_CONTRACT | NFLAG_LAST_APPL_IN_DAY | NAME_CASH_LOAN_PURPOSE | NAME_CONTRACT_STATUS | DAYS_DECISION | NAME_PAYMENT_TYPE | CODE_REJECT_REASON | NAME_TYPE_SUITE | NAME_CLIENT_TYPE | NAME_GOODS_CATEGORY | NAME_PORTFOLIO | NAME_PRODUCT_TYPE | CHANNEL_TYPE | SELLERPLACE_AREA | NAME_SELLER_INDUSTRY | CNT_PAYMENT | NAME_YIELD_GROUP | PRODUCT_COMBINATION | DAYS_FIRST_DRAWING | DAYS_FIRST_DUE | DAYS_LAST_DUE_1ST_VERSION | DAYS_LAST_DUE | DAYS_TERMINATION | NFLAG_INSURED_ON_APPROVAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100001 | 100001 | Consumer loans | 3951.000000 | 24835.500000 | 23787.000000 | 24835.500000 | FRIDAY | 13 | Y | 1 | XAP | Approved | -1740 | Cash through the bank | XAP | Family | Refreshed | Mobile | POS | XNA | Country-wide | 23 | Connectivity | 8.000000 | high | POS mobile with interest | 365243.000000 | -1709.000000 | -1499.000000 | -1619.000000 | -1612.000000 | 0.000000 |
| 100002 | 100002 | Consumer loans | 9251.775000 | 179055.000000 | 179055.000000 | 179055.000000 | SATURDAY | 9 | Y | 1 | XAP | Approved | -606 | XNA | XAP | Unaccompanied | New | Vehicles | POS | XNA | Stone | 500 | Auto technology | 24.000000 | low_normal | POS other with interest | 365243.000000 | -565.000000 | 125.000000 | -25.000000 | -17.000000 | 0.000000 |
| 100003 | 100003 | Cash loans | 98356.995000 | 900000.000000 | 1035882.000000 | 900000.000000 | FRIDAY | 12 | Y | 1 | XNA | Approved | -746 | XNA | XAP | Unaccompanied | Repeater | XNA | Cash | x-sell | Credit and cash offices | -1 | XNA | 12.000000 | low_normal | Cash X-Sell: low | 365243.000000 | -716.000000 | -386.000000 | -536.000000 | -527.000000 | 1.000000 |
| 100004 | 100004 | Consumer loans | 5357.250000 | 24282.000000 | 20106.000000 | 24282.000000 | FRIDAY | 5 | Y | 1 | XAP | Approved | -815 | Cash through the bank | XAP | Unaccompanied | New | Mobile | POS | XNA | Regional / Local | 30 | Connectivity | 4.000000 | middle | POS mobile without interest | 365243.000000 | -784.000000 | -694.000000 | -724.000000 | -714.000000 | 0.000000 |
| 100005 | 100005 | Cash loans | 15955.120659 | 0.000000 | 0.000000 | 227847.279283 | FRIDAY | 10 | Y | 1 | XNA | Canceled | -315 | XNA | XAP | Unaccompanied | Repeater | XNA | XNA | XNA | Credit and cash offices | -1 | XNA | 16.054082 | XNA | Cash | 342209.855039 | 13826.269337 | 33767.774054 | 76582.403064 | 81992.343838 | 0.332570 |
The previous_application data set is now clean with no missing values and ready to be merged with the other datasets.
STEP 5: Loading and preparing Application_train dataset
#Loading the dataset
app_train = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/application_train.csv')
app_train.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| SK_ID_CURR | 100002 | 100003 | 100004 | 100006 | 100007 |
| TARGET | 1 | 0 | 0 | 0 | 0 |
| NAME_CONTRACT_TYPE | Cash loans | Cash loans | Revolving loans | Cash loans | Cash loans |
| CODE_GENDER | M | F | M | F | M |
| FLAG_OWN_CAR | N | N | Y | N | N |
| FLAG_OWN_REALTY | Y | N | Y | Y | Y |
| CNT_CHILDREN | 0 | 0 | 0 | 0 | 0 |
| AMT_INCOME_TOTAL | 202500.000000 | 270000.000000 | 67500.000000 | 135000.000000 | 121500.000000 |
| AMT_CREDIT | 406597.500000 | 1293502.500000 | 135000.000000 | 312682.500000 | 513000.000000 |
| AMT_ANNUITY | 24700.500000 | 35698.500000 | 6750.000000 | 29686.500000 | 21865.500000 |
| AMT_GOODS_PRICE | 351000.000000 | 1129500.000000 | 135000.000000 | 297000.000000 | 513000.000000 |
| NAME_TYPE_SUITE | Unaccompanied | Family | Unaccompanied | Unaccompanied | Unaccompanied |
| NAME_INCOME_TYPE | Working | State servant | Working | Working | Working |
| NAME_EDUCATION_TYPE | Secondary / secondary special | Higher education | Secondary / secondary special | Secondary / secondary special | Secondary / secondary special |
| NAME_FAMILY_STATUS | Single / not married | Married | Single / not married | Civil marriage | Single / not married |
| NAME_HOUSING_TYPE | House / apartment | House / apartment | House / apartment | House / apartment | House / apartment |
| REGION_POPULATION_RELATIVE | 0.018801 | 0.003541 | 0.010032 | 0.008019 | 0.028663 |
| DAYS_BIRTH | -9461 | -16765 | -19046 | -19005 | -19932 |
| DAYS_EMPLOYED | -637 | -1188 | -225 | -3039 | -3038 |
| DAYS_REGISTRATION | -3648.000000 | -1186.000000 | -4260.000000 | -9833.000000 | -4311.000000 |
| DAYS_ID_PUBLISH | -2120 | -291 | -2531 | -2437 | -3458 |
| OWN_CAR_AGE | NaN | NaN | 26.000000 | NaN | NaN |
| FLAG_MOBIL | 1 | 1 | 1 | 1 | 1 |
| FLAG_EMP_PHONE | 1 | 1 | 1 | 1 | 1 |
| FLAG_WORK_PHONE | 0 | 0 | 1 | 0 | 0 |
| FLAG_CONT_MOBILE | 1 | 1 | 1 | 1 | 1 |
| FLAG_PHONE | 1 | 1 | 1 | 0 | 0 |
| FLAG_EMAIL | 0 | 0 | 0 | 0 | 0 |
| OCCUPATION_TYPE | Laborers | Core staff | Laborers | Laborers | Core staff |
| CNT_FAM_MEMBERS | 1.000000 | 2.000000 | 1.000000 | 2.000000 | 1.000000 |
| REGION_RATING_CLIENT | 2 | 1 | 2 | 2 | 2 |
| REGION_RATING_CLIENT_W_CITY | 2 | 1 | 2 | 2 | 2 |
| WEEKDAY_APPR_PROCESS_START | WEDNESDAY | MONDAY | MONDAY | WEDNESDAY | THURSDAY |
| HOUR_APPR_PROCESS_START | 10 | 11 | 9 | 17 | 11 |
| REG_REGION_NOT_LIVE_REGION | 0 | 0 | 0 | 0 | 0 |
| REG_REGION_NOT_WORK_REGION | 0 | 0 | 0 | 0 | 0 |
| LIVE_REGION_NOT_WORK_REGION | 0 | 0 | 0 | 0 | 0 |
| REG_CITY_NOT_LIVE_CITY | 0 | 0 | 0 | 0 | 0 |
| REG_CITY_NOT_WORK_CITY | 0 | 0 | 0 | 0 | 1 |
| LIVE_CITY_NOT_WORK_CITY | 0 | 0 | 0 | 0 | 1 |
| ORGANIZATION_TYPE | Business Entity Type 3 | School | Government | Business Entity Type 3 | Religion |
| EXT_SOURCE_1 | 0.083037 | 0.311267 | NaN | NaN | NaN |
| EXT_SOURCE_2 | 0.262949 | 0.622246 | 0.555912 | 0.650442 | 0.322738 |
| EXT_SOURCE_3 | 0.139376 | NaN | 0.729567 | NaN | NaN |
| APARTMENTS_AVG | 0.024700 | 0.095900 | NaN | NaN | NaN |
| BASEMENTAREA_AVG | 0.036900 | 0.052900 | NaN | NaN | NaN |
| YEARS_BEGINEXPLUATATION_AVG | 0.972200 | 0.985100 | NaN | NaN | NaN |
| YEARS_BUILD_AVG | 0.619200 | 0.796000 | NaN | NaN | NaN |
| COMMONAREA_AVG | 0.014300 | 0.060500 | NaN | NaN | NaN |
| ELEVATORS_AVG | 0.000000 | 0.080000 | NaN | NaN | NaN |
| ENTRANCES_AVG | 0.069000 | 0.034500 | NaN | NaN | NaN |
| FLOORSMAX_AVG | 0.083300 | 0.291700 | NaN | NaN | NaN |
| FLOORSMIN_AVG | 0.125000 | 0.333300 | NaN | NaN | NaN |
| LANDAREA_AVG | 0.036900 | 0.013000 | NaN | NaN | NaN |
| LIVINGAPARTMENTS_AVG | 0.020200 | 0.077300 | NaN | NaN | NaN |
| LIVINGAREA_AVG | 0.019000 | 0.054900 | NaN | NaN | NaN |
| NONLIVINGAPARTMENTS_AVG | 0.000000 | 0.003900 | NaN | NaN | NaN |
| NONLIVINGAREA_AVG | 0.000000 | 0.009800 | NaN | NaN | NaN |
| APARTMENTS_MODE | 0.025200 | 0.092400 | NaN | NaN | NaN |
| BASEMENTAREA_MODE | 0.038300 | 0.053800 | NaN | NaN | NaN |
| YEARS_BEGINEXPLUATATION_MODE | 0.972200 | 0.985100 | NaN | NaN | NaN |
| YEARS_BUILD_MODE | 0.634100 | 0.804000 | NaN | NaN | NaN |
| COMMONAREA_MODE | 0.014400 | 0.049700 | NaN | NaN | NaN |
| ELEVATORS_MODE | 0.000000 | 0.080600 | NaN | NaN | NaN |
| ENTRANCES_MODE | 0.069000 | 0.034500 | NaN | NaN | NaN |
| FLOORSMAX_MODE | 0.083300 | 0.291700 | NaN | NaN | NaN |
| FLOORSMIN_MODE | 0.125000 | 0.333300 | NaN | NaN | NaN |
| LANDAREA_MODE | 0.037700 | 0.012800 | NaN | NaN | NaN |
| LIVINGAPARTMENTS_MODE | 0.022000 | 0.079000 | NaN | NaN | NaN |
| LIVINGAREA_MODE | 0.019800 | 0.055400 | NaN | NaN | NaN |
| NONLIVINGAPARTMENTS_MODE | 0.000000 | 0.000000 | NaN | NaN | NaN |
| NONLIVINGAREA_MODE | 0.000000 | 0.000000 | NaN | NaN | NaN |
| APARTMENTS_MEDI | 0.025000 | 0.096800 | NaN | NaN | NaN |
| BASEMENTAREA_MEDI | 0.036900 | 0.052900 | NaN | NaN | NaN |
| YEARS_BEGINEXPLUATATION_MEDI | 0.972200 | 0.985100 | NaN | NaN | NaN |
| YEARS_BUILD_MEDI | 0.624300 | 0.798700 | NaN | NaN | NaN |
| COMMONAREA_MEDI | 0.014400 | 0.060800 | NaN | NaN | NaN |
| ELEVATORS_MEDI | 0.000000 | 0.080000 | NaN | NaN | NaN |
| ENTRANCES_MEDI | 0.069000 | 0.034500 | NaN | NaN | NaN |
| FLOORSMAX_MEDI | 0.083300 | 0.291700 | NaN | NaN | NaN |
| FLOORSMIN_MEDI | 0.125000 | 0.333300 | NaN | NaN | NaN |
| LANDAREA_MEDI | 0.037500 | 0.013200 | NaN | NaN | NaN |
| LIVINGAPARTMENTS_MEDI | 0.020500 | 0.078700 | NaN | NaN | NaN |
| LIVINGAREA_MEDI | 0.019300 | 0.055800 | NaN | NaN | NaN |
| NONLIVINGAPARTMENTS_MEDI | 0.000000 | 0.003900 | NaN | NaN | NaN |
| NONLIVINGAREA_MEDI | 0.000000 | 0.010000 | NaN | NaN | NaN |
| FONDKAPREMONT_MODE | reg oper account | reg oper account | NaN | NaN | NaN |
| HOUSETYPE_MODE | block of flats | block of flats | NaN | NaN | NaN |
| TOTALAREA_MODE | 0.014900 | 0.071400 | NaN | NaN | NaN |
| WALLSMATERIAL_MODE | Stone, brick | Block | NaN | NaN | NaN |
| EMERGENCYSTATE_MODE | No | No | NaN | NaN | NaN |
| OBS_30_CNT_SOCIAL_CIRCLE | 2.000000 | 1.000000 | 0.000000 | 2.000000 | 0.000000 |
| DEF_30_CNT_SOCIAL_CIRCLE | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| OBS_60_CNT_SOCIAL_CIRCLE | 2.000000 | 1.000000 | 0.000000 | 2.000000 | 0.000000 |
| DEF_60_CNT_SOCIAL_CIRCLE | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| DAYS_LAST_PHONE_CHANGE | -1134.000000 | -828.000000 | -815.000000 | -617.000000 | -1106.000000 |
| FLAG_DOCUMENT_2 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_3 | 1 | 1 | 0 | 1 | 0 |
| FLAG_DOCUMENT_4 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_5 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_6 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_7 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_8 | 0 | 0 | 0 | 0 | 1 |
| FLAG_DOCUMENT_9 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_10 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_11 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_12 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_13 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_14 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_15 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_16 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_17 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_18 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_19 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_20 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_21 | 0 | 0 | 0 | 0 | 0 |
| AMT_REQ_CREDIT_BUREAU_HOUR | 0.000000 | 0.000000 | 0.000000 | NaN | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_DAY | 0.000000 | 0.000000 | 0.000000 | NaN | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_WEEK | 0.000000 | 0.000000 | 0.000000 | NaN | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_MON | 0.000000 | 0.000000 | 0.000000 | NaN | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_QRT | 0.000000 | 0.000000 | 0.000000 | NaN | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_YEAR | 1.000000 | 0.000000 | 0.000000 | NaN | 0.000000 |
#dataset info
app_train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Columns: 122 entries, SK_ID_CURR to AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MB
#checking if the dataset has missing values
app_train.isnull().sum()
SK_ID_CURR 0
TARGET 0
NAME_CONTRACT_TYPE 0
CODE_GENDER 0
FLAG_OWN_CAR 0
FLAG_OWN_REALTY 0
CNT_CHILDREN 0
AMT_INCOME_TOTAL 0
AMT_CREDIT 0
AMT_ANNUITY 12
AMT_GOODS_PRICE 278
NAME_TYPE_SUITE 1292
NAME_INCOME_TYPE 0
NAME_EDUCATION_TYPE 0
NAME_FAMILY_STATUS 0
NAME_HOUSING_TYPE 0
REGION_POPULATION_RELATIVE 0
DAYS_BIRTH 0
DAYS_EMPLOYED 0
DAYS_REGISTRATION 0
DAYS_ID_PUBLISH 0
OWN_CAR_AGE 202929
FLAG_MOBIL 0
FLAG_EMP_PHONE 0
FLAG_WORK_PHONE 0
FLAG_CONT_MOBILE 0
FLAG_PHONE 0
FLAG_EMAIL 0
OCCUPATION_TYPE 96391
CNT_FAM_MEMBERS 2
REGION_RATING_CLIENT 0
REGION_RATING_CLIENT_W_CITY 0
WEEKDAY_APPR_PROCESS_START 0
HOUR_APPR_PROCESS_START 0
REG_REGION_NOT_LIVE_REGION 0
REG_REGION_NOT_WORK_REGION 0
LIVE_REGION_NOT_WORK_REGION 0
REG_CITY_NOT_LIVE_CITY 0
REG_CITY_NOT_WORK_CITY 0
LIVE_CITY_NOT_WORK_CITY 0
ORGANIZATION_TYPE 0
EXT_SOURCE_1 173378
EXT_SOURCE_2 660
EXT_SOURCE_3 60965
APARTMENTS_AVG 156061
BASEMENTAREA_AVG 179943
YEARS_BEGINEXPLUATATION_AVG 150007
YEARS_BUILD_AVG 204488
COMMONAREA_AVG 214865
ELEVATORS_AVG 163891
ENTRANCES_AVG 154828
FLOORSMAX_AVG 153020
FLOORSMIN_AVG 208642
LANDAREA_AVG 182590
LIVINGAPARTMENTS_AVG 210199
LIVINGAREA_AVG 154350
NONLIVINGAPARTMENTS_AVG 213514
NONLIVINGAREA_AVG 169682
APARTMENTS_MODE 156061
BASEMENTAREA_MODE 179943
YEARS_BEGINEXPLUATATION_MODE 150007
YEARS_BUILD_MODE 204488
COMMONAREA_MODE 214865
ELEVATORS_MODE 163891
ENTRANCES_MODE 154828
FLOORSMAX_MODE 153020
FLOORSMIN_MODE 208642
LANDAREA_MODE 182590
LIVINGAPARTMENTS_MODE 210199
LIVINGAREA_MODE 154350
NONLIVINGAPARTMENTS_MODE 213514
NONLIVINGAREA_MODE 169682
APARTMENTS_MEDI 156061
BASEMENTAREA_MEDI 179943
YEARS_BEGINEXPLUATATION_MEDI 150007
YEARS_BUILD_MEDI 204488
COMMONAREA_MEDI 214865
ELEVATORS_MEDI 163891
ENTRANCES_MEDI 154828
FLOORSMAX_MEDI 153020
FLOORSMIN_MEDI 208642
LANDAREA_MEDI 182590
LIVINGAPARTMENTS_MEDI 210199
LIVINGAREA_MEDI 154350
NONLIVINGAPARTMENTS_MEDI 213514
NONLIVINGAREA_MEDI 169682
FONDKAPREMONT_MODE 210295
HOUSETYPE_MODE 154297
TOTALAREA_MODE 148431
WALLSMATERIAL_MODE 156341
EMERGENCYSTATE_MODE 145755
OBS_30_CNT_SOCIAL_CIRCLE 1021
DEF_30_CNT_SOCIAL_CIRCLE 1021
OBS_60_CNT_SOCIAL_CIRCLE 1021
DEF_60_CNT_SOCIAL_CIRCLE 1021
DAYS_LAST_PHONE_CHANGE 1
FLAG_DOCUMENT_2 0
FLAG_DOCUMENT_3 0
FLAG_DOCUMENT_4 0
FLAG_DOCUMENT_5 0
FLAG_DOCUMENT_6 0
FLAG_DOCUMENT_7 0
FLAG_DOCUMENT_8 0
FLAG_DOCUMENT_9 0
FLAG_DOCUMENT_10 0
FLAG_DOCUMENT_11 0
FLAG_DOCUMENT_12 0
FLAG_DOCUMENT_13 0
FLAG_DOCUMENT_14 0
FLAG_DOCUMENT_15 0
FLAG_DOCUMENT_16 0
FLAG_DOCUMENT_17 0
FLAG_DOCUMENT_18 0
FLAG_DOCUMENT_19 0
FLAG_DOCUMENT_20 0
FLAG_DOCUMENT_21 0
AMT_REQ_CREDIT_BUREAU_HOUR 41519
AMT_REQ_CREDIT_BUREAU_DAY 41519
AMT_REQ_CREDIT_BUREAU_WEEK 41519
AMT_REQ_CREDIT_BUREAU_MON 41519
AMT_REQ_CREDIT_BUREAU_QRT 41519
AMT_REQ_CREDIT_BUREAU_YEAR 41519
dtype: int64
#Finding the % of missing values in each column
round(100*(app_train.isnull().sum()/len(app_train.index)),2)
SK_ID_CURR 0.000000
TARGET 0.000000
NAME_CONTRACT_TYPE 0.000000
CODE_GENDER 0.000000
FLAG_OWN_CAR 0.000000
FLAG_OWN_REALTY 0.000000
CNT_CHILDREN 0.000000
AMT_INCOME_TOTAL 0.000000
AMT_CREDIT 0.000000
AMT_ANNUITY 0.000000
AMT_GOODS_PRICE 0.090000
NAME_TYPE_SUITE 0.420000
NAME_INCOME_TYPE 0.000000
NAME_EDUCATION_TYPE 0.000000
NAME_FAMILY_STATUS 0.000000
NAME_HOUSING_TYPE 0.000000
REGION_POPULATION_RELATIVE 0.000000
DAYS_BIRTH 0.000000
DAYS_EMPLOYED 0.000000
DAYS_REGISTRATION 0.000000
DAYS_ID_PUBLISH 0.000000
OWN_CAR_AGE 65.990000
FLAG_MOBIL 0.000000
FLAG_EMP_PHONE 0.000000
FLAG_WORK_PHONE 0.000000
FLAG_CONT_MOBILE 0.000000
FLAG_PHONE 0.000000
FLAG_EMAIL 0.000000
OCCUPATION_TYPE 31.350000
CNT_FAM_MEMBERS 0.000000
REGION_RATING_CLIENT 0.000000
REGION_RATING_CLIENT_W_CITY 0.000000
WEEKDAY_APPR_PROCESS_START 0.000000
HOUR_APPR_PROCESS_START 0.000000
REG_REGION_NOT_LIVE_REGION 0.000000
REG_REGION_NOT_WORK_REGION 0.000000
LIVE_REGION_NOT_WORK_REGION 0.000000
REG_CITY_NOT_LIVE_CITY 0.000000
REG_CITY_NOT_WORK_CITY 0.000000
LIVE_CITY_NOT_WORK_CITY 0.000000
ORGANIZATION_TYPE 0.000000
EXT_SOURCE_1 56.380000
EXT_SOURCE_2 0.210000
EXT_SOURCE_3 19.830000
APARTMENTS_AVG 50.750000
BASEMENTAREA_AVG 58.520000
YEARS_BEGINEXPLUATATION_AVG 48.780000
YEARS_BUILD_AVG 66.500000
COMMONAREA_AVG 69.870000
ELEVATORS_AVG 53.300000
ENTRANCES_AVG 50.350000
FLOORSMAX_AVG 49.760000
FLOORSMIN_AVG 67.850000
LANDAREA_AVG 59.380000
LIVINGAPARTMENTS_AVG 68.350000
LIVINGAREA_AVG 50.190000
NONLIVINGAPARTMENTS_AVG 69.430000
NONLIVINGAREA_AVG 55.180000
APARTMENTS_MODE 50.750000
BASEMENTAREA_MODE 58.520000
YEARS_BEGINEXPLUATATION_MODE 48.780000
YEARS_BUILD_MODE 66.500000
COMMONAREA_MODE 69.870000
ELEVATORS_MODE 53.300000
ENTRANCES_MODE 50.350000
FLOORSMAX_MODE 49.760000
FLOORSMIN_MODE 67.850000
LANDAREA_MODE 59.380000
LIVINGAPARTMENTS_MODE 68.350000
LIVINGAREA_MODE 50.190000
NONLIVINGAPARTMENTS_MODE 69.430000
NONLIVINGAREA_MODE 55.180000
APARTMENTS_MEDI 50.750000
BASEMENTAREA_MEDI 58.520000
YEARS_BEGINEXPLUATATION_MEDI 48.780000
YEARS_BUILD_MEDI 66.500000
COMMONAREA_MEDI 69.870000
ELEVATORS_MEDI 53.300000
ENTRANCES_MEDI 50.350000
FLOORSMAX_MEDI 49.760000
FLOORSMIN_MEDI 67.850000
LANDAREA_MEDI 59.380000
LIVINGAPARTMENTS_MEDI 68.350000
LIVINGAREA_MEDI 50.190000
NONLIVINGAPARTMENTS_MEDI 69.430000
NONLIVINGAREA_MEDI 55.180000
FONDKAPREMONT_MODE 68.390000
HOUSETYPE_MODE 50.180000
TOTALAREA_MODE 48.270000
WALLSMATERIAL_MODE 50.840000
EMERGENCYSTATE_MODE 47.400000
OBS_30_CNT_SOCIAL_CIRCLE 0.330000
DEF_30_CNT_SOCIAL_CIRCLE 0.330000
OBS_60_CNT_SOCIAL_CIRCLE 0.330000
DEF_60_CNT_SOCIAL_CIRCLE 0.330000
DAYS_LAST_PHONE_CHANGE 0.000000
FLAG_DOCUMENT_2 0.000000
FLAG_DOCUMENT_3 0.000000
FLAG_DOCUMENT_4 0.000000
FLAG_DOCUMENT_5 0.000000
FLAG_DOCUMENT_6 0.000000
FLAG_DOCUMENT_7 0.000000
FLAG_DOCUMENT_8 0.000000
FLAG_DOCUMENT_9 0.000000
FLAG_DOCUMENT_10 0.000000
FLAG_DOCUMENT_11 0.000000
FLAG_DOCUMENT_12 0.000000
FLAG_DOCUMENT_13 0.000000
FLAG_DOCUMENT_14 0.000000
FLAG_DOCUMENT_15 0.000000
FLAG_DOCUMENT_16 0.000000
FLAG_DOCUMENT_17 0.000000
FLAG_DOCUMENT_18 0.000000
FLAG_DOCUMENT_19 0.000000
FLAG_DOCUMENT_20 0.000000
FLAG_DOCUMENT_21 0.000000
AMT_REQ_CREDIT_BUREAU_HOUR 13.500000
AMT_REQ_CREDIT_BUREAU_DAY 13.500000
AMT_REQ_CREDIT_BUREAU_WEEK 13.500000
AMT_REQ_CREDIT_BUREAU_MON 13.500000
AMT_REQ_CREDIT_BUREAU_QRT 13.500000
AMT_REQ_CREDIT_BUREAU_YEAR 13.500000
dtype: float64
#Assigning NULL percentage value to a variable
app_null = round(100*(app_train.isnull().sum()/len(app_train.index)),2)
# find columns with more than 50% missing values
column = app_null[app_null >= 50].index
# drop columns with high null percentage
app_train.drop(column,axis = 1,inplace = True)
#check null percentage after dropping
round(100*(app_train.isnull().sum()/len(app_train.index)),2)
SK_ID_CURR 0.000000
TARGET 0.000000
NAME_CONTRACT_TYPE 0.000000
CODE_GENDER 0.000000
FLAG_OWN_CAR 0.000000
FLAG_OWN_REALTY 0.000000
CNT_CHILDREN 0.000000
AMT_INCOME_TOTAL 0.000000
AMT_CREDIT 0.000000
AMT_ANNUITY 0.000000
AMT_GOODS_PRICE 0.090000
NAME_TYPE_SUITE 0.420000
NAME_INCOME_TYPE 0.000000
NAME_EDUCATION_TYPE 0.000000
NAME_FAMILY_STATUS 0.000000
NAME_HOUSING_TYPE 0.000000
REGION_POPULATION_RELATIVE 0.000000
DAYS_BIRTH 0.000000
DAYS_EMPLOYED 0.000000
DAYS_REGISTRATION 0.000000
DAYS_ID_PUBLISH 0.000000
FLAG_MOBIL 0.000000
FLAG_EMP_PHONE 0.000000
FLAG_WORK_PHONE 0.000000
FLAG_CONT_MOBILE 0.000000
FLAG_PHONE 0.000000
FLAG_EMAIL 0.000000
OCCUPATION_TYPE 31.350000
CNT_FAM_MEMBERS 0.000000
REGION_RATING_CLIENT 0.000000
REGION_RATING_CLIENT_W_CITY 0.000000
WEEKDAY_APPR_PROCESS_START 0.000000
HOUR_APPR_PROCESS_START 0.000000
REG_REGION_NOT_LIVE_REGION 0.000000
REG_REGION_NOT_WORK_REGION 0.000000
LIVE_REGION_NOT_WORK_REGION 0.000000
REG_CITY_NOT_LIVE_CITY 0.000000
REG_CITY_NOT_WORK_CITY 0.000000
LIVE_CITY_NOT_WORK_CITY 0.000000
ORGANIZATION_TYPE 0.000000
EXT_SOURCE_2 0.210000
EXT_SOURCE_3 19.830000
YEARS_BEGINEXPLUATATION_AVG 48.780000
FLOORSMAX_AVG 49.760000
YEARS_BEGINEXPLUATATION_MODE 48.780000
FLOORSMAX_MODE 49.760000
YEARS_BEGINEXPLUATATION_MEDI 48.780000
FLOORSMAX_MEDI 49.760000
TOTALAREA_MODE 48.270000
EMERGENCYSTATE_MODE 47.400000
OBS_30_CNT_SOCIAL_CIRCLE 0.330000
DEF_30_CNT_SOCIAL_CIRCLE 0.330000
OBS_60_CNT_SOCIAL_CIRCLE 0.330000
DEF_60_CNT_SOCIAL_CIRCLE 0.330000
DAYS_LAST_PHONE_CHANGE 0.000000
FLAG_DOCUMENT_2 0.000000
FLAG_DOCUMENT_3 0.000000
FLAG_DOCUMENT_4 0.000000
FLAG_DOCUMENT_5 0.000000
FLAG_DOCUMENT_6 0.000000
FLAG_DOCUMENT_7 0.000000
FLAG_DOCUMENT_8 0.000000
FLAG_DOCUMENT_9 0.000000
FLAG_DOCUMENT_10 0.000000
FLAG_DOCUMENT_11 0.000000
FLAG_DOCUMENT_12 0.000000
FLAG_DOCUMENT_13 0.000000
FLAG_DOCUMENT_14 0.000000
FLAG_DOCUMENT_15 0.000000
FLAG_DOCUMENT_16 0.000000
FLAG_DOCUMENT_17 0.000000
FLAG_DOCUMENT_18 0.000000
FLAG_DOCUMENT_19 0.000000
FLAG_DOCUMENT_20 0.000000
FLAG_DOCUMENT_21 0.000000
AMT_REQ_CREDIT_BUREAU_HOUR 13.500000
AMT_REQ_CREDIT_BUREAU_DAY 13.500000
AMT_REQ_CREDIT_BUREAU_WEEK 13.500000
AMT_REQ_CREDIT_BUREAU_MON 13.500000
AMT_REQ_CREDIT_BUREAU_QRT 13.500000
AMT_REQ_CREDIT_BUREAU_YEAR 13.500000
dtype: float64
# finding the shape of the dataset after dropping the columns with more than 50% missing values
app_train.shape
(307511, 81)
41 columns were dropped from the dataset (they had > 50% of missing values).
app_train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 81 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SK_ID_CURR 307511 non-null int64
1 TARGET 307511 non-null int64
2 NAME_CONTRACT_TYPE 307511 non-null object
3 CODE_GENDER 307511 non-null object
4 FLAG_OWN_CAR 307511 non-null object
5 FLAG_OWN_REALTY 307511 non-null object
6 CNT_CHILDREN 307511 non-null int64
7 AMT_INCOME_TOTAL 307511 non-null float64
8 AMT_CREDIT 307511 non-null float64
9 AMT_ANNUITY 307499 non-null float64
10 AMT_GOODS_PRICE 307233 non-null float64
11 NAME_TYPE_SUITE 306219 non-null object
12 NAME_INCOME_TYPE 307511 non-null object
13 NAME_EDUCATION_TYPE 307511 non-null object
14 NAME_FAMILY_STATUS 307511 non-null object
15 NAME_HOUSING_TYPE 307511 non-null object
16 REGION_POPULATION_RELATIVE 307511 non-null float64
17 DAYS_BIRTH 307511 non-null int64
18 DAYS_EMPLOYED 307511 non-null int64
19 DAYS_REGISTRATION 307511 non-null float64
20 DAYS_ID_PUBLISH 307511 non-null int64
21 FLAG_MOBIL 307511 non-null int64
22 FLAG_EMP_PHONE 307511 non-null int64
23 FLAG_WORK_PHONE 307511 non-null int64
24 FLAG_CONT_MOBILE 307511 non-null int64
25 FLAG_PHONE 307511 non-null int64
26 FLAG_EMAIL 307511 non-null int64
27 OCCUPATION_TYPE 211120 non-null object
28 CNT_FAM_MEMBERS 307509 non-null float64
29 REGION_RATING_CLIENT 307511 non-null int64
30 REGION_RATING_CLIENT_W_CITY 307511 non-null int64
31 WEEKDAY_APPR_PROCESS_START 307511 non-null object
32 HOUR_APPR_PROCESS_START 307511 non-null int64
33 REG_REGION_NOT_LIVE_REGION 307511 non-null int64
34 REG_REGION_NOT_WORK_REGION 307511 non-null int64
35 LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
36 REG_CITY_NOT_LIVE_CITY 307511 non-null int64
37 REG_CITY_NOT_WORK_CITY 307511 non-null int64
38 LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
39 ORGANIZATION_TYPE 307511 non-null object
40 EXT_SOURCE_2 306851 non-null float64
41 EXT_SOURCE_3 246546 non-null float64
42 YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
43 FLOORSMAX_AVG 154491 non-null float64
44 YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
45 FLOORSMAX_MODE 154491 non-null float64
46 YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
47 FLOORSMAX_MEDI 154491 non-null float64
48 TOTALAREA_MODE 159080 non-null float64
49 EMERGENCYSTATE_MODE 161756 non-null object
50 OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
51 DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
52 OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
53 DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
54 DAYS_LAST_PHONE_CHANGE 307510 non-null float64
55 FLAG_DOCUMENT_2 307511 non-null int64
56 FLAG_DOCUMENT_3 307511 non-null int64
57 FLAG_DOCUMENT_4 307511 non-null int64
58 FLAG_DOCUMENT_5 307511 non-null int64
59 FLAG_DOCUMENT_6 307511 non-null int64
60 FLAG_DOCUMENT_7 307511 non-null int64
61 FLAG_DOCUMENT_8 307511 non-null int64
62 FLAG_DOCUMENT_9 307511 non-null int64
63 FLAG_DOCUMENT_10 307511 non-null int64
64 FLAG_DOCUMENT_11 307511 non-null int64
65 FLAG_DOCUMENT_12 307511 non-null int64
66 FLAG_DOCUMENT_13 307511 non-null int64
67 FLAG_DOCUMENT_14 307511 non-null int64
68 FLAG_DOCUMENT_15 307511 non-null int64
69 FLAG_DOCUMENT_16 307511 non-null int64
70 FLAG_DOCUMENT_17 307511 non-null int64
71 FLAG_DOCUMENT_18 307511 non-null int64
72 FLAG_DOCUMENT_19 307511 non-null int64
73 FLAG_DOCUMENT_20 307511 non-null int64
74 FLAG_DOCUMENT_21 307511 non-null int64
75 AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
76 AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
77 AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
78 AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
79 AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
80 AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(27), int64(41), object(13)
memory usage: 190.0+ MB
#getting the list of columns that have missing values > 0
null_counts = app_train.isnull().sum()
null_app = null_counts[null_counts > 0]
null_app
AMT_ANNUITY 12
AMT_GOODS_PRICE 278
NAME_TYPE_SUITE 1292
OCCUPATION_TYPE 96391
CNT_FAM_MEMBERS 2
EXT_SOURCE_2 660
EXT_SOURCE_3 60965
YEARS_BEGINEXPLUATATION_AVG 150007
FLOORSMAX_AVG 153020
YEARS_BEGINEXPLUATATION_MODE 150007
FLOORSMAX_MODE 153020
YEARS_BEGINEXPLUATATION_MEDI 150007
FLOORSMAX_MEDI 153020
TOTALAREA_MODE 148431
EMERGENCYSTATE_MODE 145755
OBS_30_CNT_SOCIAL_CIRCLE 1021
DEF_30_CNT_SOCIAL_CIRCLE 1021
OBS_60_CNT_SOCIAL_CIRCLE 1021
DEF_60_CNT_SOCIAL_CIRCLE 1021
DAYS_LAST_PHONE_CHANGE 1
AMT_REQ_CREDIT_BUREAU_HOUR 41519
AMT_REQ_CREDIT_BUREAU_DAY 41519
AMT_REQ_CREDIT_BUREAU_WEEK 41519
AMT_REQ_CREDIT_BUREAU_MON 41519
AMT_REQ_CREDIT_BUREAU_QRT 41519
AMT_REQ_CREDIT_BUREAU_YEAR 41519
dtype: int64
# Replacing the missing values for the above columns
# For the numerical values, replacing the missing values with mean of their respective columns
app_train['AMT_ANNUITY'].fillna(app_train['AMT_ANNUITY'].mean(), inplace = True)
app_train['AMT_GOODS_PRICE'].fillna(app_train['AMT_GOODS_PRICE'].mean(), inplace = True)
app_train['EXT_SOURCE_2'].fillna(app_train['EXT_SOURCE_2'].mean(), inplace = True)
app_train['EXT_SOURCE_3'].fillna(app_train['EXT_SOURCE_3'].mean(), inplace = True)
app_train['YEARS_BEGINEXPLUATATION_AVG'].fillna(app_train['YEARS_BEGINEXPLUATATION_AVG'].mean(), inplace = True)
app_train['FLOORSMAX_AVG'].fillna(app_train['FLOORSMAX_AVG'].mean(), inplace = True)
app_train['YEARS_BEGINEXPLUATATION_MODE'].fillna(app_train['YEARS_BEGINEXPLUATATION_MODE'].mean(), inplace = True)
app_train['FLOORSMAX_MODE'].fillna(app_train['FLOORSMAX_MODE'].mean(), inplace = True)
app_train['YEARS_BEGINEXPLUATATION_MEDI'].fillna(app_train['YEARS_BEGINEXPLUATATION_MEDI'].mean(), inplace = True)
app_train['FLOORSMAX_MEDI'].fillna(app_train['FLOORSMAX_MEDI'].mean(), inplace = True)
app_train['TOTALAREA_MODE'].fillna(app_train['TOTALAREA_MODE'].mean(), inplace = True)
app_train['OBS_30_CNT_SOCIAL_CIRCLE'].fillna(app_train['OBS_30_CNT_SOCIAL_CIRCLE'].mean(), inplace = True)
app_train['DEF_30_CNT_SOCIAL_CIRCLE'].fillna(app_train['DEF_30_CNT_SOCIAL_CIRCLE'].mean(), inplace = True)
app_train['OBS_60_CNT_SOCIAL_CIRCLE'].fillna(app_train['OBS_60_CNT_SOCIAL_CIRCLE'].mean(), inplace = True)
app_train['DEF_60_CNT_SOCIAL_CIRCLE'].fillna(app_train['DEF_60_CNT_SOCIAL_CIRCLE'].mean(), inplace = True)
app_train['DAYS_LAST_PHONE_CHANGE'].fillna(app_train['DAYS_LAST_PHONE_CHANGE'].mean(), inplace = True)
app_train['AMT_REQ_CREDIT_BUREAU_HOUR'].fillna(app_train['AMT_REQ_CREDIT_BUREAU_HOUR'].mean(), inplace = True)
app_train['AMT_REQ_CREDIT_BUREAU_DAY'].fillna(app_train['AMT_REQ_CREDIT_BUREAU_DAY'].mean(), inplace = True)
app_train['AMT_REQ_CREDIT_BUREAU_WEEK'].fillna(app_train['AMT_REQ_CREDIT_BUREAU_WEEK'].mean(), inplace = True)
app_train['AMT_REQ_CREDIT_BUREAU_MON'].fillna(app_train['AMT_REQ_CREDIT_BUREAU_MON'].mean(), inplace = True)
app_train['AMT_REQ_CREDIT_BUREAU_QRT'].fillna(app_train['AMT_REQ_CREDIT_BUREAU_QRT'].mean(), inplace = True)
app_train['AMT_REQ_CREDIT_BUREAU_YEAR'].fillna(app_train['AMT_REQ_CREDIT_BUREAU_YEAR'].mean(), inplace = True)
# For the categorical values and the CNT_FAM_MEMBERS (no of family members), replacing the missing values with most frequently appearing values
# Getting the mode of the categorical columns and for no of family members
print(app_train['NAME_TYPE_SUITE'].mode())
print(app_train['OCCUPATION_TYPE'].mode())
print(app_train['EMERGENCYSTATE_MODE'].mode())
print(app_train['CNT_FAM_MEMBERS'].mode())
0 Unaccompanied
dtype: object
0 Laborers
dtype: object
0 No
dtype: object
0 2.000000
dtype: float64
# Replacing the missing values for the below with the most frequently appearing values from above
app_train.loc[pd.isnull(app_train['NAME_TYPE_SUITE']),'NAME_TYPE_SUITE'] = "Unaccompanied"
app_train.loc[pd.isnull(app_train['OCCUPATION_TYPE']),'OCCUPATION_TYPE'] = "Laborers"
app_train.loc[pd.isnull(app_train['EMERGENCYSTATE_MODE']),'EMERGENCYSTATE_MODE'] = 0
app_train.loc[pd.isnull(app_train['CNT_FAM_MEMBERS']),'CNT_FAM_MEMBERS'] = 2
# checking for the null values again to see if there are any more missing values
app_train.isnull().sum()
SK_ID_CURR 0
TARGET 0
NAME_CONTRACT_TYPE 0
CODE_GENDER 0
FLAG_OWN_CAR 0
FLAG_OWN_REALTY 0
CNT_CHILDREN 0
AMT_INCOME_TOTAL 0
AMT_CREDIT 0
AMT_ANNUITY 0
AMT_GOODS_PRICE 0
NAME_TYPE_SUITE 0
NAME_INCOME_TYPE 0
NAME_EDUCATION_TYPE 0
NAME_FAMILY_STATUS 0
NAME_HOUSING_TYPE 0
REGION_POPULATION_RELATIVE 0
DAYS_BIRTH 0
DAYS_EMPLOYED 0
DAYS_REGISTRATION 0
DAYS_ID_PUBLISH 0
FLAG_MOBIL 0
FLAG_EMP_PHONE 0
FLAG_WORK_PHONE 0
FLAG_CONT_MOBILE 0
FLAG_PHONE 0
FLAG_EMAIL 0
OCCUPATION_TYPE 0
CNT_FAM_MEMBERS 0
REGION_RATING_CLIENT 0
REGION_RATING_CLIENT_W_CITY 0
WEEKDAY_APPR_PROCESS_START 0
HOUR_APPR_PROCESS_START 0
REG_REGION_NOT_LIVE_REGION 0
REG_REGION_NOT_WORK_REGION 0
LIVE_REGION_NOT_WORK_REGION 0
REG_CITY_NOT_LIVE_CITY 0
REG_CITY_NOT_WORK_CITY 0
LIVE_CITY_NOT_WORK_CITY 0
ORGANIZATION_TYPE 0
EXT_SOURCE_2 0
EXT_SOURCE_3 0
YEARS_BEGINEXPLUATATION_AVG 0
FLOORSMAX_AVG 0
YEARS_BEGINEXPLUATATION_MODE 0
FLOORSMAX_MODE 0
YEARS_BEGINEXPLUATATION_MEDI 0
FLOORSMAX_MEDI 0
TOTALAREA_MODE 0
EMERGENCYSTATE_MODE 0
OBS_30_CNT_SOCIAL_CIRCLE 0
DEF_30_CNT_SOCIAL_CIRCLE 0
OBS_60_CNT_SOCIAL_CIRCLE 0
DEF_60_CNT_SOCIAL_CIRCLE 0
DAYS_LAST_PHONE_CHANGE 0
FLAG_DOCUMENT_2 0
FLAG_DOCUMENT_3 0
FLAG_DOCUMENT_4 0
FLAG_DOCUMENT_5 0
FLAG_DOCUMENT_6 0
FLAG_DOCUMENT_7 0
FLAG_DOCUMENT_8 0
FLAG_DOCUMENT_9 0
FLAG_DOCUMENT_10 0
FLAG_DOCUMENT_11 0
FLAG_DOCUMENT_12 0
FLAG_DOCUMENT_13 0
FLAG_DOCUMENT_14 0
FLAG_DOCUMENT_15 0
FLAG_DOCUMENT_16 0
FLAG_DOCUMENT_17 0
FLAG_DOCUMENT_18 0
FLAG_DOCUMENT_19 0
FLAG_DOCUMENT_20 0
FLAG_DOCUMENT_21 0
AMT_REQ_CREDIT_BUREAU_HOUR 0
AMT_REQ_CREDIT_BUREAU_DAY 0
AMT_REQ_CREDIT_BUREAU_WEEK 0
AMT_REQ_CREDIT_BUREAU_MON 0
AMT_REQ_CREDIT_BUREAU_QRT 0
AMT_REQ_CREDIT_BUREAU_YEAR 0
dtype: int64
Description of the columns in dataset for better understanding:
- SK_ID_CURR → ID of loan in our sample.
- TARGET → What the client actually paid on previous credit on this installment.
- NAME_CONTRACT_TYPE → Relative to application date of current. application when was the expected termination of the previous application
- CODE_GENDER → Gender of the client.
- FLAG_OWN_CAR → Flag if the client owns a car.
- FLAG_OWN_REALTY → Flag if client owns a house or flat.
- CNT_CHILDREN → Number of children the client has.
- AMT_INCOME_TOTAL → Income of the client.
- AMT_CREDIT → Credit amount of the loan.
- AMT_ANNUITY → Loan annuity.
- AMT_GOODS_PRICE → For consumer loans it is the price of the goods for which the loan is given.
- NAME_TYPE_SUITE → Who was accompanying client when he was applying for the loan.
- NAME_INCOME_TYPE → Clients income type (businessman, working, maternity leave,…).
- NAME_EDUCATION_TYPE → Level of highest education the client achieved.
- NAME_FAMILY_STATUS → Family status of the client.
- NAME_HOUSING_TYPE → What is the housing situation of the client (renting, living with parents, …).
- REGION_POPULATION_RELATIVE → Normalized population of region where client lives (higher number means the client lives in more populated region).
- DAYS_BIRTH → Client’s age in days at the time of application.
- DAYS_EMPLOYED → How many days before the application the person started current employment.
- DAYS_REGISTRATION → How many days before the application did client change his registration.
- DAYS_ID_PUBLISH → How many days before the application did client change the identity document with which he applied for the loan.
- FLAG_MOBIL → Did client provide mobile phone (1=YES, 0=NO).
- FLAG_EMP_PHONE → Did client provide work phone (1=YES, 0=NO).
- FLAG_WORK_PHONE → Did client provide home phone (1=YES, 0=NO).
- FLAG_CONT_MOBILE → Was mobile phone reachable (1=YES, 0=NO).
- FLAG_PHONE Did → client provide home phone (1=YES, 0=NO).
- FLAG_EMAIL Did → client provide email (1=YES, 0=NO).
- OCCUPATION_TYPE → What kind of occupation does the client have.
- CNT_FAM_MEMBERS → How many family members does client have.
- REGION_RATING_CLIENT → Our rating of the region where client lives (1,2,3).
- REGION_RATING_CLIENT_W_CITY → Our rating of the region where client lives with taking city into account (1,2,3).
- WEEKDAY_APPR_PROCESS_START → On which day of the week did the client apply for the loan.
- HOUR_APPR_PROCESS_START → Approximately at what hour did the client apply for the loan.
- REG_REGION_NOT_LIVE_REGION → Flag if client’s permanent address does not match contact address (1=different, 0=same, at region level).
- REG_REGION_NOT_WORK_REGION → Flag if client’s permanent address does not match work address (1=different, 0=same, at region level).
- LIVE_REGION_NOT_WORK_REGION → Flag if client’s contact address does not match work address (1=different, 0=same, at region level).
- REG_CITY_NOT_LIVE_CITY → Flag if client’s permanent address does not match contact address (1=different, 0=same, at city level).
- REG_CITY_NOT_WORK_CITY → Flag if client’s permanent address does not match work address (1=different, 0=same, at city level).
- LIVE_CITY_NOT_WORK_CITY → Flag if client’s contact address does not match work address (1=different, 0=same, at city level).
- ORGANIZATION_TYPE → Type of organization where client works.
- EXT_SOURCE_2 → Normalized score from external data source.
- EXT_SOURCE_3 → Normalized score from external data source.
- YEARS_BEGINEXPLUATATION_AVG → Normalized information about building where the client lives, years.
- FLOORSMAX_AVG → Normalized information about building where the client lives, number of floor.
- YEARS_BEGINEXPLUATATION_MODE → Normalized information about building where the client lives, years.
- FLOORSMAX_MODE → Normalized information about building where the client lives, number of floor.
- YEARS_BEGINEXPLUATATION_MEDI → Normalized information about building where the client lives, year.
- FLOORSMAX_MEDI → Normalized information about building where the client lives, number of floor.
- TOTALAREA_MODE → Normalized information about building where the client lives, total area.
- EMERGENCYSTATE_MODE → Normalized information about building where the client lives, Emergency exit Y/N.
- OBS_30_CNT_SOCIAL_CIRCLE → How many observation of client’s social surroundings with observable 30 DPD (days past due) default.
- DEF_30_CNT_SOCIAL_CIRCLE → How many observation of client’s social surroundings defaulted on 30 DPD (days past due).
- OBS_60_CNT_SOCIAL_CIRCLE → How many observation of client’s social surroundings with observable 60 DPD (days past due) default.
- DEF_60_CNT_SOCIAL_CIRCLE → How many observation of client’s social surroundings defaulted on 60 (days past due) DPD.
- DAYS_LAST_PHONE_CHANGE → How many days before application did client change phone.
- FLAG_DOCUMENT_2 → Did client provide document 2.
- FLAG_DOCUMENT_3 → Did client provide document 3.
- FLAG_DOCUMENT_4 → Did client provide document 4.
- FLAG_DOCUMENT_5 → Did client provide document 5.
- FLAG_DOCUMENT_6 → Did client provide document 6.
- FLAG_DOCUMENT_7 → Did client provide document 7.
- FLAG_DOCUMENT_8 → Did client provide document 8.
- FLAG_DOCUMENT_9 → Did client provide document 9.
- FLAG_DOCUMENT_10 → Did client provide document 10.
- FLAG_DOCUMENT_11 → Did client provide document 11.
- FLAG_DOCUMENT_12 → Did client provide document 12.
- FLAG_DOCUMENT_13 → Did client provide document 13.
- FLAG_DOCUMENT_14 → Did client provide document 14.
- FLAG_DOCUMENT_15 → Did client provide document 15.
- FLAG_DOCUMENT_16 → Did client provide document 16.
- FLAG_DOCUMENT_17 → Did client provide document 17.
- FLAG_DOCUMENT_18 → Did client provide document 18.
- FLAG_DOCUMENT_19 → Did client provide document 19.
- FLAG_DOCUMENT_20 → Did client provide document 20.
- FLAG_DOCUMENT_21 → Did client provide document 21.
- AMT_REQ_CREDIT_BUREAU_HOUR → Number of enquiries to Credit Bureau about the client one hour before application.
- AMT_REQ_CREDIT_BUREAU_DAY → Number of enquiries to Credit Bureau about the client one day before application (excluding one hour before application).
- AMT_REQ_CREDIT_BUREAU_WEEK → Number of enquiries to Credit Bureau about the client one week before application (excluding one day before application).
- AMT_REQ_CREDIT_BUREAU_MON → Number of enquiries to Credit Bureau about the client one month before application (excluding one week before application).
- AMT_REQ_CREDIT_BUREAU_QRT → Number of enquiries to Credit Bureau about the client 3 month before application (excluding one month before application).
- AMT_REQ_CREDIT_BUREAU_YEAR → Number of enquiries to Credit Bureau about the client one day year (excluding last 3 months before application).
# Decribe the data set
app_train.describe()
| SK_ID_CURR | TARGET | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | AMT_GOODS_PRICE | REGION_POPULATION_RELATIVE | DAYS_BIRTH | DAYS_EMPLOYED | DAYS_REGISTRATION | DAYS_ID_PUBLISH | FLAG_MOBIL | FLAG_EMP_PHONE | FLAG_WORK_PHONE | FLAG_CONT_MOBILE | FLAG_PHONE | FLAG_EMAIL | CNT_FAM_MEMBERS | REGION_RATING_CLIENT | REGION_RATING_CLIENT_W_CITY | HOUR_APPR_PROCESS_START | REG_REGION_NOT_LIVE_REGION | REG_REGION_NOT_WORK_REGION | LIVE_REGION_NOT_WORK_REGION | REG_CITY_NOT_LIVE_CITY | REG_CITY_NOT_WORK_CITY | LIVE_CITY_NOT_WORK_CITY | EXT_SOURCE_2 | EXT_SOURCE_3 | YEARS_BEGINEXPLUATATION_AVG | FLOORSMAX_AVG | YEARS_BEGINEXPLUATATION_MODE | FLOORSMAX_MODE | YEARS_BEGINEXPLUATATION_MEDI | FLOORSMAX_MEDI | TOTALAREA_MODE | OBS_30_CNT_SOCIAL_CIRCLE | DEF_30_CNT_SOCIAL_CIRCLE | OBS_60_CNT_SOCIAL_CIRCLE | DEF_60_CNT_SOCIAL_CIRCLE | DAYS_LAST_PHONE_CHANGE | FLAG_DOCUMENT_2 | FLAG_DOCUMENT_3 | FLAG_DOCUMENT_4 | FLAG_DOCUMENT_5 | FLAG_DOCUMENT_6 | FLAG_DOCUMENT_7 | FLAG_DOCUMENT_8 | FLAG_DOCUMENT_9 | FLAG_DOCUMENT_10 | FLAG_DOCUMENT_11 | FLAG_DOCUMENT_12 | FLAG_DOCUMENT_13 | FLAG_DOCUMENT_14 | FLAG_DOCUMENT_15 | FLAG_DOCUMENT_16 | FLAG_DOCUMENT_17 | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 | 307511.000000 |
| mean | 278180.518577 | 0.080729 | 0.417052 | 168797.919297 | 599025.999706 | 27108.573909 | 538396.207429 | 0.020868 | -16036.995067 | 63815.045904 | -4986.120328 | -2994.202373 | 0.999997 | 0.819889 | 0.199368 | 0.998133 | 0.281066 | 0.056720 | 2.152664 | 2.052463 | 2.031521 | 12.063419 | 0.015144 | 0.050769 | 0.040659 | 0.078173 | 0.230454 | 0.179555 | 0.514393 | 0.510853 | 0.977735 | 0.226282 | 0.977065 | 0.222315 | 0.977752 | 0.225897 | 0.102547 | 1.422245 | 0.143421 | 1.405292 | 0.100049 | -962.858788 | 0.000042 | 0.710023 | 0.000081 | 0.015115 | 0.088055 | 0.000192 | 0.081376 | 0.003896 | 0.000023 | 0.003912 | 0.000007 | 0.003525 | 0.002936 | 0.001210 | 0.009928 | 0.000267 | 0.008130 | 0.000595 | 0.000507 | 0.000335 | 0.006402 | 0.007000 | 0.034362 | 0.267395 | 0.265474 | 1.899974 |
| std | 102790.175348 | 0.272419 | 0.722121 | 237123.146279 | 402490.776996 | 14493.454517 | 369279.426396 | 0.013831 | 4363.988632 | 141275.766519 | 3522.886321 | 1509.450419 | 0.001803 | 0.384280 | 0.399526 | 0.043164 | 0.449521 | 0.231307 | 0.910679 | 0.509034 | 0.502737 | 3.265832 | 0.122126 | 0.219526 | 0.197499 | 0.268444 | 0.421124 | 0.383817 | 0.190855 | 0.174464 | 0.042385 | 0.102521 | 0.046215 | 0.101860 | 0.042867 | 0.102823 | 0.077292 | 2.397000 | 0.445956 | 2.375849 | 0.361689 | 826.807143 | 0.006502 | 0.453752 | 0.009016 | 0.122010 | 0.283376 | 0.013850 | 0.273412 | 0.062295 | 0.004771 | 0.062424 | 0.002550 | 0.059268 | 0.054110 | 0.034760 | 0.099144 | 0.016327 | 0.089798 | 0.024387 | 0.022518 | 0.018299 | 0.077983 | 0.103009 | 0.190366 | 0.851923 | 0.738507 | 1.738528 |
| min | 100002.000000 | 0.000000 | 0.000000 | 25650.000000 | 45000.000000 | 1615.500000 | 40500.000000 | 0.000290 | -25229.000000 | -17912.000000 | -24672.000000 | -7197.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000527 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -4292.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 189145.500000 | 0.000000 | 0.000000 | 112500.000000 | 270000.000000 | 16524.000000 | 238500.000000 | 0.010006 | -19682.000000 | -2760.000000 | -7479.500000 | -4299.000000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 2.000000 | 2.000000 | 2.000000 | 10.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.392974 | 0.417100 | 0.977735 | 0.166700 | 0.977065 | 0.166700 | 0.977752 | 0.166700 | 0.067000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -1570.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 50% | 278202.000000 | 0.000000 | 0.000000 | 147150.000000 | 513531.000000 | 24903.000000 | 450000.000000 | 0.018850 | -15750.000000 | -1213.000000 | -4504.000000 | -3254.000000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 2.000000 | 2.000000 | 2.000000 | 12.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.565467 | 0.510853 | 0.977735 | 0.226282 | 0.977065 | 0.222315 | 0.977752 | 0.225897 | 0.102547 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -757.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.899974 |
| 75% | 367142.500000 | 0.000000 | 1.000000 | 202500.000000 | 808650.000000 | 34596.000000 | 679500.000000 | 0.028663 | -12413.000000 | -289.000000 | -2010.000000 | -1720.000000 | 1.000000 | 1.000000 | 0.000000 | 1.000000 | 1.000000 | 0.000000 | 3.000000 | 2.000000 | 2.000000 | 14.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.663422 | 0.636376 | 0.982100 | 0.226282 | 0.981600 | 0.222315 | 0.982100 | 0.225897 | 0.102547 | 2.000000 | 0.000000 | 2.000000 | 0.000000 | -274.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.267395 | 0.265474 | 3.000000 |
| max | 456255.000000 | 1.000000 | 19.000000 | 117000000.000000 | 4050000.000000 | 258025.500000 | 4050000.000000 | 0.072508 | -7489.000000 | 365243.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 20.000000 | 3.000000 | 3.000000 | 23.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 0.855000 | 0.896010 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 348.000000 | 34.000000 | 344.000000 | 24.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 4.000000 | 9.000000 | 8.000000 | 27.000000 | 261.000000 | 25.000000 |
STEP 6: Loading the bureau_merged dataset
bureau_merged = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/bureau_merged.csv')
bureau_merged.head()
| SK_ID_CURR | SK_ID_CURR.1 | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | CNT_CREDIT_PROLONG | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_SUM_LIMIT | AMT_CREDIT_SUM_OVERDUE | CREDIT_TYPE | DAYS_CREDIT_UPDATE | MONTHS_BALANCE | STATUS | index | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100001 | 100001 | Active | currency 1 | -49 | 0 | 1778.000000 | -1017.437148 | 0 | 378000.000000 | 373239.000000 | 0.000000 | 0.000000 | Consumer credit | -16 | 0.000000 | 0 | 5896635.000000 |
| 1 | 100002 | 100002 | Active | currency 1 | -103 | 0 | 510.517362 | -1017.437148 | 0 | 31988.565000 | 0.000000 | 31988.565000 | 0.000000 | Credit card | -24 | 0.000000 | 0 | 6158909.000000 |
| 2 | 100003 | 100003 | Active | currency 1 | -606 | 0 | 1216.000000 | -1017.437148 | 0 | 810000.000000 | 0.000000 | 810000.000000 | 0.000000 | Credit card | -43 | nan | NaN | nan |
| 3 | 100004 | 100004 | Closed | currency 1 | -408 | 0 | -382.000000 | -382.000000 | 0 | 94537.800000 | 0.000000 | 0.000000 | 0.000000 | Consumer credit | -382 | nan | NaN | nan |
| 4 | 100005 | 100005 | Active | currency 1 | -62 | 0 | 122.000000 | -1017.437148 | 0 | 29826.000000 | 25321.500000 | 0.000000 | 0.000000 | Consumer credit | -31 | 0.000000 | X | 6735202.000000 |
bureau_merged.drop(['SK_ID_CURR.1'], axis = 1, inplace = True)
STEP 7: Merging all the datasets into final data set
# Merging Application Train with Bureau and Bureau Balance Merged data sets
# Left merge the two datasets
app_bureau = pd.merge(app_train, bureau_merged, on='SK_ID_CURR', how='left')
print(app_train.shape, bureau_merged.shape, app_bureau.shape)
(307511, 81) (305811, 17) (307511, 97)
# Merging the above with Pos_cash balance data set
# Left merge the two datasets
app_POS = pd.merge(app_bureau, POS_cashBal, on='SK_ID_CURR', how='left')
print(app_bureau.shape, POS_cashBal.shape, app_POS.shape)
(307511, 97) (337252, 7) (307511, 103)
# Merging the above with creditcard balance data set
# Left merge the two datasets
app_credit = pd.merge(app_POS, creditcard_bal, on='SK_ID_CURR', how='left')
print(app_POS.shape, creditcard_bal.shape, app_credit.shape)
(307511, 103) (103558, 22) (307511, 124)
# Merging the above with installment payments balance data set
# Left merge the two datasets
app_instal = pd.merge(app_credit, instal_paymt, on='SK_ID_CURR', how='left')
print(app_credit.shape, instal_paymt.shape, app_instal.shape)
(307511, 124) (339587, 7) (307511, 130)
# Merging the above with previous application data set
# Left merge the two datasets
finaldata = pd.merge(app_instal, prev_appln, on='SK_ID_CURR', how='left')
print(app_instal.shape, prev_appln.shape, finaldata.shape)
(307511, 130) (338857, 32) (307511, 161)
finaldata.isnull().sum()
SK_ID_CURR 0
TARGET 0
NAME_CONTRACT_TYPE_x 0
CODE_GENDER 0
FLAG_OWN_CAR 0
FLAG_OWN_REALTY 0
CNT_CHILDREN 0
AMT_INCOME_TOTAL 0
AMT_CREDIT_x 0
AMT_ANNUITY_x 0
AMT_GOODS_PRICE_x 0
NAME_TYPE_SUITE_x 0
NAME_INCOME_TYPE 0
NAME_EDUCATION_TYPE 0
NAME_FAMILY_STATUS 0
NAME_HOUSING_TYPE 0
REGION_POPULATION_RELATIVE 0
DAYS_BIRTH 0
DAYS_EMPLOYED 0
DAYS_REGISTRATION 0
DAYS_ID_PUBLISH 0
FLAG_MOBIL 0
FLAG_EMP_PHONE 0
FLAG_WORK_PHONE 0
FLAG_CONT_MOBILE 0
FLAG_PHONE 0
FLAG_EMAIL 0
OCCUPATION_TYPE 0
CNT_FAM_MEMBERS 0
REGION_RATING_CLIENT 0
REGION_RATING_CLIENT_W_CITY 0
WEEKDAY_APPR_PROCESS_START_x 0
HOUR_APPR_PROCESS_START_x 0
REG_REGION_NOT_LIVE_REGION 0
REG_REGION_NOT_WORK_REGION 0
LIVE_REGION_NOT_WORK_REGION 0
REG_CITY_NOT_LIVE_CITY 0
REG_CITY_NOT_WORK_CITY 0
LIVE_CITY_NOT_WORK_CITY 0
ORGANIZATION_TYPE 0
EXT_SOURCE_2 0
EXT_SOURCE_3 0
YEARS_BEGINEXPLUATATION_AVG 0
FLOORSMAX_AVG 0
YEARS_BEGINEXPLUATATION_MODE 0
FLOORSMAX_MODE 0
YEARS_BEGINEXPLUATATION_MEDI 0
FLOORSMAX_MEDI 0
TOTALAREA_MODE 0
EMERGENCYSTATE_MODE 0
OBS_30_CNT_SOCIAL_CIRCLE 0
DEF_30_CNT_SOCIAL_CIRCLE 0
OBS_60_CNT_SOCIAL_CIRCLE 0
DEF_60_CNT_SOCIAL_CIRCLE 0
DAYS_LAST_PHONE_CHANGE 0
FLAG_DOCUMENT_2 0
FLAG_DOCUMENT_3 0
FLAG_DOCUMENT_4 0
FLAG_DOCUMENT_5 0
FLAG_DOCUMENT_6 0
FLAG_DOCUMENT_7 0
FLAG_DOCUMENT_8 0
FLAG_DOCUMENT_9 0
FLAG_DOCUMENT_10 0
FLAG_DOCUMENT_11 0
FLAG_DOCUMENT_12 0
FLAG_DOCUMENT_13 0
FLAG_DOCUMENT_14 0
FLAG_DOCUMENT_15 0
FLAG_DOCUMENT_16 0
FLAG_DOCUMENT_17 0
FLAG_DOCUMENT_18 0
FLAG_DOCUMENT_19 0
FLAG_DOCUMENT_20 0
FLAG_DOCUMENT_21 0
AMT_REQ_CREDIT_BUREAU_HOUR 0
AMT_REQ_CREDIT_BUREAU_DAY 0
AMT_REQ_CREDIT_BUREAU_WEEK 0
AMT_REQ_CREDIT_BUREAU_MON 0
AMT_REQ_CREDIT_BUREAU_QRT 0
AMT_REQ_CREDIT_BUREAU_YEAR 0
CREDIT_ACTIVE 44020
CREDIT_CURRENCY 44020
DAYS_CREDIT 44020
CREDIT_DAY_OVERDUE 44020
DAYS_CREDIT_ENDDATE 44020
DAYS_ENDDATE_FACT 44020
CNT_CREDIT_PROLONG 44020
AMT_CREDIT_SUM 44020
AMT_CREDIT_SUM_DEBT 44020
AMT_CREDIT_SUM_LIMIT 44020
AMT_CREDIT_SUM_OVERDUE 44020
CREDIT_TYPE 44020
DAYS_CREDIT_UPDATE 44020
MONTHS_BALANCE_x 215396
STATUS 215396
index 215396
MONTHS_BALANCE_y 18067
CNT_INSTALMENT 18067
CNT_INSTALMENT_FUTURE 18067
NAME_CONTRACT_STATUS_x 18067
SK_DPD_x 18067
SK_DPD_DEF_x 18067
MONTHS_BALANCE 220606
AMT_BALANCE 220606
AMT_CREDIT_LIMIT_ACTUAL 220606
AMT_DRAWINGS_ATM_CURRENT 220606
AMT_DRAWINGS_CURRENT 220606
AMT_DRAWINGS_OTHER_CURRENT 220606
AMT_DRAWINGS_POS_CURRENT 220606
AMT_INST_MIN_REGULARITY 220606
AMT_PAYMENT_CURRENT 220606
AMT_PAYMENT_TOTAL_CURRENT 220606
AMT_RECEIVABLE_PRINCIPAL 220606
AMT_RECIVABLE 220606
AMT_TOTAL_RECEIVABLE 220606
CNT_DRAWINGS_ATM_CURRENT 220606
CNT_DRAWINGS_CURRENT 220606
CNT_DRAWINGS_OTHER_CURRENT 220606
CNT_DRAWINGS_POS_CURRENT 220606
CNT_INSTALMENT_MATURE_CUM 220606
NAME_CONTRACT_STATUS_y 220606
SK_DPD_y 220606
SK_DPD_DEF_y 220606
NUM_INSTALMENT_VERSION 15868
NUM_INSTALMENT_NUMBER 15868
DAYS_INSTALMENT 15868
DAYS_ENTRY_PAYMENT 15868
AMT_INSTALMENT 15868
AMT_PAYMENT 15868
NAME_CONTRACT_TYPE_y 16454
AMT_ANNUITY_y 16454
AMT_APPLICATION 16454
AMT_CREDIT_y 16454
AMT_GOODS_PRICE_y 16454
WEEKDAY_APPR_PROCESS_START_y 16454
HOUR_APPR_PROCESS_START_y 16454
FLAG_LAST_APPL_PER_CONTRACT 16454
NFLAG_LAST_APPL_IN_DAY 16454
NAME_CASH_LOAN_PURPOSE 16454
NAME_CONTRACT_STATUS 16454
DAYS_DECISION 16454
NAME_PAYMENT_TYPE 16454
CODE_REJECT_REASON 16454
NAME_TYPE_SUITE_y 16454
NAME_CLIENT_TYPE 16454
NAME_GOODS_CATEGORY 16454
NAME_PORTFOLIO 16454
NAME_PRODUCT_TYPE 16454
CHANNEL_TYPE 16454
SELLERPLACE_AREA 16454
NAME_SELLER_INDUSTRY 16454
CNT_PAYMENT 16454
NAME_YIELD_GROUP 16454
PRODUCT_COMBINATION 16454
DAYS_FIRST_DRAWING 16454
DAYS_FIRST_DUE 16454
DAYS_LAST_DUE_1ST_VERSION 16454
DAYS_LAST_DUE 16454
DAYS_TERMINATION 16454
NFLAG_INSURED_ON_APPROVAL 16454
dtype: int64
#Assigning NULL percentage value to a variable
app_data = round(100*(finaldata.isnull().sum()/len(finaldata.index)),2)
# find columns with more than 50% missing values
coldata = app_data[app_data >= 50].index
# drop columns with high null percentage
finaldata.drop(coldata, axis = 1,inplace = True)
#check null percentage after dropping
round(100*(finaldata.isnull().sum()/len(finaldata.index)),2)
SK_ID_CURR 0.000000
TARGET 0.000000
NAME_CONTRACT_TYPE_x 0.000000
CODE_GENDER 0.000000
FLAG_OWN_CAR 0.000000
FLAG_OWN_REALTY 0.000000
CNT_CHILDREN 0.000000
AMT_INCOME_TOTAL 0.000000
AMT_CREDIT_x 0.000000
AMT_ANNUITY_x 0.000000
AMT_GOODS_PRICE_x 0.000000
NAME_TYPE_SUITE_x 0.000000
NAME_INCOME_TYPE 0.000000
NAME_EDUCATION_TYPE 0.000000
NAME_FAMILY_STATUS 0.000000
NAME_HOUSING_TYPE 0.000000
REGION_POPULATION_RELATIVE 0.000000
DAYS_BIRTH 0.000000
DAYS_EMPLOYED 0.000000
DAYS_REGISTRATION 0.000000
DAYS_ID_PUBLISH 0.000000
FLAG_MOBIL 0.000000
FLAG_EMP_PHONE 0.000000
FLAG_WORK_PHONE 0.000000
FLAG_CONT_MOBILE 0.000000
FLAG_PHONE 0.000000
FLAG_EMAIL 0.000000
OCCUPATION_TYPE 0.000000
CNT_FAM_MEMBERS 0.000000
REGION_RATING_CLIENT 0.000000
REGION_RATING_CLIENT_W_CITY 0.000000
WEEKDAY_APPR_PROCESS_START_x 0.000000
HOUR_APPR_PROCESS_START_x 0.000000
REG_REGION_NOT_LIVE_REGION 0.000000
REG_REGION_NOT_WORK_REGION 0.000000
LIVE_REGION_NOT_WORK_REGION 0.000000
REG_CITY_NOT_LIVE_CITY 0.000000
REG_CITY_NOT_WORK_CITY 0.000000
LIVE_CITY_NOT_WORK_CITY 0.000000
ORGANIZATION_TYPE 0.000000
EXT_SOURCE_2 0.000000
EXT_SOURCE_3 0.000000
YEARS_BEGINEXPLUATATION_AVG 0.000000
FLOORSMAX_AVG 0.000000
YEARS_BEGINEXPLUATATION_MODE 0.000000
FLOORSMAX_MODE 0.000000
YEARS_BEGINEXPLUATATION_MEDI 0.000000
FLOORSMAX_MEDI 0.000000
TOTALAREA_MODE 0.000000
EMERGENCYSTATE_MODE 0.000000
OBS_30_CNT_SOCIAL_CIRCLE 0.000000
DEF_30_CNT_SOCIAL_CIRCLE 0.000000
OBS_60_CNT_SOCIAL_CIRCLE 0.000000
DEF_60_CNT_SOCIAL_CIRCLE 0.000000
DAYS_LAST_PHONE_CHANGE 0.000000
FLAG_DOCUMENT_2 0.000000
FLAG_DOCUMENT_3 0.000000
FLAG_DOCUMENT_4 0.000000
FLAG_DOCUMENT_5 0.000000
FLAG_DOCUMENT_6 0.000000
FLAG_DOCUMENT_7 0.000000
FLAG_DOCUMENT_8 0.000000
FLAG_DOCUMENT_9 0.000000
FLAG_DOCUMENT_10 0.000000
FLAG_DOCUMENT_11 0.000000
FLAG_DOCUMENT_12 0.000000
FLAG_DOCUMENT_13 0.000000
FLAG_DOCUMENT_14 0.000000
FLAG_DOCUMENT_15 0.000000
FLAG_DOCUMENT_16 0.000000
FLAG_DOCUMENT_17 0.000000
FLAG_DOCUMENT_18 0.000000
FLAG_DOCUMENT_19 0.000000
FLAG_DOCUMENT_20 0.000000
FLAG_DOCUMENT_21 0.000000
AMT_REQ_CREDIT_BUREAU_HOUR 0.000000
AMT_REQ_CREDIT_BUREAU_DAY 0.000000
AMT_REQ_CREDIT_BUREAU_WEEK 0.000000
AMT_REQ_CREDIT_BUREAU_MON 0.000000
AMT_REQ_CREDIT_BUREAU_QRT 0.000000
AMT_REQ_CREDIT_BUREAU_YEAR 0.000000
CREDIT_ACTIVE 14.310000
CREDIT_CURRENCY 14.310000
DAYS_CREDIT 14.310000
CREDIT_DAY_OVERDUE 14.310000
DAYS_CREDIT_ENDDATE 14.310000
DAYS_ENDDATE_FACT 14.310000
CNT_CREDIT_PROLONG 14.310000
AMT_CREDIT_SUM 14.310000
AMT_CREDIT_SUM_DEBT 14.310000
AMT_CREDIT_SUM_LIMIT 14.310000
AMT_CREDIT_SUM_OVERDUE 14.310000
CREDIT_TYPE 14.310000
DAYS_CREDIT_UPDATE 14.310000
MONTHS_BALANCE_y 5.880000
CNT_INSTALMENT 5.880000
CNT_INSTALMENT_FUTURE 5.880000
NAME_CONTRACT_STATUS_x 5.880000
SK_DPD_x 5.880000
SK_DPD_DEF_x 5.880000
NUM_INSTALMENT_VERSION 5.160000
NUM_INSTALMENT_NUMBER 5.160000
DAYS_INSTALMENT 5.160000
DAYS_ENTRY_PAYMENT 5.160000
AMT_INSTALMENT 5.160000
AMT_PAYMENT 5.160000
NAME_CONTRACT_TYPE_y 5.350000
AMT_ANNUITY_y 5.350000
AMT_APPLICATION 5.350000
AMT_CREDIT_y 5.350000
AMT_GOODS_PRICE_y 5.350000
WEEKDAY_APPR_PROCESS_START_y 5.350000
HOUR_APPR_PROCESS_START_y 5.350000
FLAG_LAST_APPL_PER_CONTRACT 5.350000
NFLAG_LAST_APPL_IN_DAY 5.350000
NAME_CASH_LOAN_PURPOSE 5.350000
NAME_CONTRACT_STATUS 5.350000
DAYS_DECISION 5.350000
NAME_PAYMENT_TYPE 5.350000
CODE_REJECT_REASON 5.350000
NAME_TYPE_SUITE_y 5.350000
NAME_CLIENT_TYPE 5.350000
NAME_GOODS_CATEGORY 5.350000
NAME_PORTFOLIO 5.350000
NAME_PRODUCT_TYPE 5.350000
CHANNEL_TYPE 5.350000
SELLERPLACE_AREA 5.350000
NAME_SELLER_INDUSTRY 5.350000
CNT_PAYMENT 5.350000
NAME_YIELD_GROUP 5.350000
PRODUCT_COMBINATION 5.350000
DAYS_FIRST_DRAWING 5.350000
DAYS_FIRST_DUE 5.350000
DAYS_LAST_DUE_1ST_VERSION 5.350000
DAYS_LAST_DUE 5.350000
DAYS_TERMINATION 5.350000
NFLAG_INSURED_ON_APPROVAL 5.350000
dtype: float64
finaldata.shape
(307511, 137)
null_count = finaldata.isnull().sum()
null_data = null_count[null_count > 0]
null_data
CREDIT_ACTIVE 44020
CREDIT_CURRENCY 44020
DAYS_CREDIT 44020
CREDIT_DAY_OVERDUE 44020
DAYS_CREDIT_ENDDATE 44020
DAYS_ENDDATE_FACT 44020
CNT_CREDIT_PROLONG 44020
AMT_CREDIT_SUM 44020
AMT_CREDIT_SUM_DEBT 44020
AMT_CREDIT_SUM_LIMIT 44020
AMT_CREDIT_SUM_OVERDUE 44020
CREDIT_TYPE 44020
DAYS_CREDIT_UPDATE 44020
MONTHS_BALANCE_y 18067
CNT_INSTALMENT 18067
CNT_INSTALMENT_FUTURE 18067
NAME_CONTRACT_STATUS_x 18067
SK_DPD_x 18067
SK_DPD_DEF_x 18067
NUM_INSTALMENT_VERSION 15868
NUM_INSTALMENT_NUMBER 15868
DAYS_INSTALMENT 15868
DAYS_ENTRY_PAYMENT 15868
AMT_INSTALMENT 15868
AMT_PAYMENT 15868
NAME_CONTRACT_TYPE_y 16454
AMT_ANNUITY_y 16454
AMT_APPLICATION 16454
AMT_CREDIT_y 16454
AMT_GOODS_PRICE_y 16454
WEEKDAY_APPR_PROCESS_START_y 16454
HOUR_APPR_PROCESS_START_y 16454
FLAG_LAST_APPL_PER_CONTRACT 16454
NFLAG_LAST_APPL_IN_DAY 16454
NAME_CASH_LOAN_PURPOSE 16454
NAME_CONTRACT_STATUS 16454
DAYS_DECISION 16454
NAME_PAYMENT_TYPE 16454
CODE_REJECT_REASON 16454
NAME_TYPE_SUITE_y 16454
NAME_CLIENT_TYPE 16454
NAME_GOODS_CATEGORY 16454
NAME_PORTFOLIO 16454
NAME_PRODUCT_TYPE 16454
CHANNEL_TYPE 16454
SELLERPLACE_AREA 16454
NAME_SELLER_INDUSTRY 16454
CNT_PAYMENT 16454
NAME_YIELD_GROUP 16454
PRODUCT_COMBINATION 16454
DAYS_FIRST_DRAWING 16454
DAYS_FIRST_DUE 16454
DAYS_LAST_DUE_1ST_VERSION 16454
DAYS_LAST_DUE 16454
DAYS_TERMINATION 16454
NFLAG_INSURED_ON_APPROVAL 16454
dtype: int64
finaldata.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 307511 entries, 0 to 307510
Columns: 137 entries, SK_ID_CURR to NFLAG_INSURED_ON_APPROVAL
dtypes: float64(63), int64(41), object(33)
memory usage: 323.8+ MB
finaldata.dtypes
SK_ID_CURR int64
TARGET int64
NAME_CONTRACT_TYPE_x object
CODE_GENDER object
FLAG_OWN_CAR object
FLAG_OWN_REALTY object
CNT_CHILDREN int64
AMT_INCOME_TOTAL float64
AMT_CREDIT_x float64
AMT_ANNUITY_x float64
AMT_GOODS_PRICE_x float64
NAME_TYPE_SUITE_x object
NAME_INCOME_TYPE object
NAME_EDUCATION_TYPE object
NAME_FAMILY_STATUS object
NAME_HOUSING_TYPE object
REGION_POPULATION_RELATIVE float64
DAYS_BIRTH int64
DAYS_EMPLOYED int64
DAYS_REGISTRATION float64
DAYS_ID_PUBLISH int64
FLAG_MOBIL int64
FLAG_EMP_PHONE int64
FLAG_WORK_PHONE int64
FLAG_CONT_MOBILE int64
FLAG_PHONE int64
FLAG_EMAIL int64
OCCUPATION_TYPE object
CNT_FAM_MEMBERS float64
REGION_RATING_CLIENT int64
REGION_RATING_CLIENT_W_CITY int64
WEEKDAY_APPR_PROCESS_START_x object
HOUR_APPR_PROCESS_START_x int64
REG_REGION_NOT_LIVE_REGION int64
REG_REGION_NOT_WORK_REGION int64
LIVE_REGION_NOT_WORK_REGION int64
REG_CITY_NOT_LIVE_CITY int64
REG_CITY_NOT_WORK_CITY int64
LIVE_CITY_NOT_WORK_CITY int64
ORGANIZATION_TYPE object
EXT_SOURCE_2 float64
EXT_SOURCE_3 float64
YEARS_BEGINEXPLUATATION_AVG float64
FLOORSMAX_AVG float64
YEARS_BEGINEXPLUATATION_MODE float64
FLOORSMAX_MODE float64
YEARS_BEGINEXPLUATATION_MEDI float64
FLOORSMAX_MEDI float64
TOTALAREA_MODE float64
EMERGENCYSTATE_MODE object
OBS_30_CNT_SOCIAL_CIRCLE float64
DEF_30_CNT_SOCIAL_CIRCLE float64
OBS_60_CNT_SOCIAL_CIRCLE float64
DEF_60_CNT_SOCIAL_CIRCLE float64
DAYS_LAST_PHONE_CHANGE float64
FLAG_DOCUMENT_2 int64
FLAG_DOCUMENT_3 int64
FLAG_DOCUMENT_4 int64
FLAG_DOCUMENT_5 int64
FLAG_DOCUMENT_6 int64
FLAG_DOCUMENT_7 int64
FLAG_DOCUMENT_8 int64
FLAG_DOCUMENT_9 int64
FLAG_DOCUMENT_10 int64
FLAG_DOCUMENT_11 int64
FLAG_DOCUMENT_12 int64
FLAG_DOCUMENT_13 int64
FLAG_DOCUMENT_14 int64
FLAG_DOCUMENT_15 int64
FLAG_DOCUMENT_16 int64
FLAG_DOCUMENT_17 int64
FLAG_DOCUMENT_18 int64
FLAG_DOCUMENT_19 int64
FLAG_DOCUMENT_20 int64
FLAG_DOCUMENT_21 int64
AMT_REQ_CREDIT_BUREAU_HOUR float64
AMT_REQ_CREDIT_BUREAU_DAY float64
AMT_REQ_CREDIT_BUREAU_WEEK float64
AMT_REQ_CREDIT_BUREAU_MON float64
AMT_REQ_CREDIT_BUREAU_QRT float64
AMT_REQ_CREDIT_BUREAU_YEAR float64
CREDIT_ACTIVE object
CREDIT_CURRENCY object
DAYS_CREDIT float64
CREDIT_DAY_OVERDUE float64
DAYS_CREDIT_ENDDATE float64
DAYS_ENDDATE_FACT float64
CNT_CREDIT_PROLONG float64
AMT_CREDIT_SUM float64
AMT_CREDIT_SUM_DEBT float64
AMT_CREDIT_SUM_LIMIT float64
AMT_CREDIT_SUM_OVERDUE float64
CREDIT_TYPE object
DAYS_CREDIT_UPDATE float64
MONTHS_BALANCE_y float64
CNT_INSTALMENT float64
CNT_INSTALMENT_FUTURE float64
NAME_CONTRACT_STATUS_x object
SK_DPD_x float64
SK_DPD_DEF_x float64
NUM_INSTALMENT_VERSION float64
NUM_INSTALMENT_NUMBER float64
DAYS_INSTALMENT float64
DAYS_ENTRY_PAYMENT float64
AMT_INSTALMENT float64
AMT_PAYMENT float64
NAME_CONTRACT_TYPE_y object
AMT_ANNUITY_y float64
AMT_APPLICATION float64
AMT_CREDIT_y float64
AMT_GOODS_PRICE_y float64
WEEKDAY_APPR_PROCESS_START_y object
HOUR_APPR_PROCESS_START_y float64
FLAG_LAST_APPL_PER_CONTRACT object
NFLAG_LAST_APPL_IN_DAY float64
NAME_CASH_LOAN_PURPOSE object
NAME_CONTRACT_STATUS object
DAYS_DECISION float64
NAME_PAYMENT_TYPE object
CODE_REJECT_REASON object
NAME_TYPE_SUITE_y object
NAME_CLIENT_TYPE object
NAME_GOODS_CATEGORY object
NAME_PORTFOLIO object
NAME_PRODUCT_TYPE object
CHANNEL_TYPE object
SELLERPLACE_AREA float64
NAME_SELLER_INDUSTRY object
CNT_PAYMENT float64
NAME_YIELD_GROUP object
PRODUCT_COMBINATION object
DAYS_FIRST_DRAWING float64
DAYS_FIRST_DUE float64
DAYS_LAST_DUE_1ST_VERSION float64
DAYS_LAST_DUE float64
DAYS_TERMINATION float64
NFLAG_INSURED_ON_APPROVAL float64
dtype: object
# Replacing the missing values for the columns
# For the numerical values, replacing the missing values with mean of their respective columns
finaldata['DAYS_CREDIT'].fillna(finaldata['DAYS_CREDIT'].mean(), inplace = True)
finaldata['CREDIT_DAY_OVERDUE'].fillna(finaldata['CREDIT_DAY_OVERDUE'].mean(), inplace = True)
finaldata['DAYS_CREDIT_ENDDATE'].fillna(finaldata['DAYS_CREDIT_ENDDATE'].mean(), inplace = True)
finaldata['DAYS_ENDDATE_FACT'].fillna(finaldata['DAYS_ENDDATE_FACT'].mean(), inplace = True)
finaldata['CNT_CREDIT_PROLONG'].fillna(finaldata['CNT_CREDIT_PROLONG'].mean(), inplace = True)
finaldata['AMT_CREDIT_SUM'].fillna(finaldata['AMT_CREDIT_SUM'].mean(), inplace = True)
finaldata['AMT_CREDIT_SUM_DEBT'].fillna(finaldata['AMT_CREDIT_SUM_DEBT'].mean(), inplace = True)
finaldata['AMT_CREDIT_SUM_LIMIT'].fillna(finaldata['AMT_CREDIT_SUM_LIMIT'].mean(), inplace = True)
finaldata['AMT_CREDIT_SUM_OVERDUE'].fillna(finaldata['AMT_CREDIT_SUM_OVERDUE'].mean(), inplace = True)
finaldata['DAYS_CREDIT_UPDATE'].fillna(finaldata['DAYS_CREDIT_UPDATE'].mean(), inplace = True)
finaldata['MONTHS_BALANCE_y'].fillna(finaldata['MONTHS_BALANCE_y'].mean(), inplace = True)
finaldata['CNT_INSTALMENT'].fillna(finaldata['CNT_INSTALMENT'].mean(), inplace = True)
finaldata['CNT_INSTALMENT_FUTURE'].fillna(finaldata['CNT_INSTALMENT_FUTURE'].mean(), inplace = True)
finaldata['SK_DPD_x'].fillna(finaldata['SK_DPD_x'].mean(), inplace = True)
finaldata['SK_DPD_DEF_x'].fillna(finaldata['SK_DPD_DEF_x'].mean(), inplace = True)
finaldata['NUM_INSTALMENT_VERSION'].fillna(finaldata['NUM_INSTALMENT_VERSION'].mean(), inplace = True)
finaldata['NUM_INSTALMENT_NUMBER'].fillna(finaldata['NUM_INSTALMENT_NUMBER'].mean(), inplace = True)
finaldata['DAYS_INSTALMENT'].fillna(finaldata['DAYS_INSTALMENT'].mean(), inplace = True)
finaldata['DAYS_ENTRY_PAYMENT'].fillna(finaldata['DAYS_ENTRY_PAYMENT'].mean(), inplace = True)
finaldata['AMT_INSTALMENT'].fillna(finaldata['AMT_INSTALMENT'].mean(), inplace = True)
finaldata['AMT_PAYMENT'].fillna(finaldata['AMT_PAYMENT'].mean(), inplace = True)
finaldata['AMT_ANNUITY_y'].fillna(finaldata['AMT_ANNUITY_y'].mean(), inplace = True)
finaldata['AMT_APPLICATION'].fillna(finaldata['AMT_APPLICATION'].mean(), inplace = True)
finaldata['AMT_CREDIT_y'].fillna(finaldata['AMT_CREDIT_y'].mean(), inplace = True)
finaldata['AMT_GOODS_PRICE_y'].fillna(finaldata['AMT_GOODS_PRICE_y'].mean(), inplace = True)
finaldata['HOUR_APPR_PROCESS_START_y'].fillna(finaldata['HOUR_APPR_PROCESS_START_y'].mean(), inplace = True)
finaldata['NFLAG_LAST_APPL_IN_DAY'].fillna(finaldata['NFLAG_LAST_APPL_IN_DAY'].mean(), inplace = True)
finaldata['DAYS_DECISION'].fillna(finaldata['DAYS_DECISION'].mean(), inplace = True)
finaldata['SELLERPLACE_AREA'].fillna(finaldata['SELLERPLACE_AREA'].mean(), inplace = True)
finaldata['CNT_PAYMENT'].fillna(finaldata['CNT_PAYMENT'].mean(), inplace = True)
finaldata['DAYS_FIRST_DRAWING'].fillna(finaldata['DAYS_FIRST_DRAWING'].mean(), inplace = True)
finaldata['DAYS_FIRST_DUE'].fillna(finaldata['DAYS_FIRST_DUE'].mean(), inplace = True)
finaldata['DAYS_LAST_DUE_1ST_VERSION'].fillna(finaldata['DAYS_LAST_DUE_1ST_VERSION'].mean(), inplace = True)
finaldata['DAYS_LAST_DUE'].fillna(finaldata['DAYS_LAST_DUE'].mean(), inplace = True)
finaldata['DAYS_TERMINATION'].fillna(finaldata['DAYS_TERMINATION'].mean(), inplace = True)
finaldata['NFLAG_INSURED_ON_APPROVAL'].fillna(finaldata['NFLAG_INSURED_ON_APPROVAL'].mean(), inplace = True)
# For the categorical values replacing the missing values with most frequently appearing values
# Getting the mode of the categorical columns
print(finaldata['CREDIT_ACTIVE'].mode())
print(finaldata['CREDIT_CURRENCY'].mode())
print(finaldata['CREDIT_TYPE'].mode())
print(finaldata['NAME_CONTRACT_STATUS_x'].mode())
print(finaldata['NAME_CONTRACT_TYPE_y'].mode())
print(finaldata['WEEKDAY_APPR_PROCESS_START_y'].mode())
print(finaldata['FLAG_LAST_APPL_PER_CONTRACT'].mode())
print(finaldata['NAME_CASH_LOAN_PURPOSE'].mode())
print(finaldata['NAME_CONTRACT_STATUS'].mode())
print(finaldata['NAME_PAYMENT_TYPE'].mode())
print(finaldata['CODE_REJECT_REASON'].mode())
print(finaldata['NAME_TYPE_SUITE_y'].mode())
print(finaldata['NAME_CLIENT_TYPE'].mode())
print(finaldata['NAME_GOODS_CATEGORY'].mode())
print(finaldata['NAME_PORTFOLIO'].mode())
print(finaldata['NAME_PRODUCT_TYPE'].mode())
print(finaldata['CHANNEL_TYPE'].mode())
print(finaldata['NAME_SELLER_INDUSTRY'].mode())
print(finaldata['NAME_YIELD_GROUP'].mode())
print(finaldata['PRODUCT_COMBINATION'].mode())
0 Active
dtype: object
0 currency 1
dtype: object
0 Consumer credit
dtype: object
0 Completed
dtype: object
0 Cash loans
dtype: object
0 MONDAY
dtype: object
0 Y
dtype: object
0 XAP
dtype: object
0 Approved
dtype: object
0 Cash through the bank
dtype: object
0 XAP
dtype: object
0 Unaccompanied
dtype: object
0 Repeater
dtype: object
0 XNA
dtype: object
0 POS
dtype: object
0 XNA
dtype: object
0 Credit and cash offices
dtype: object
0 XNA
dtype: object
0 XNA
dtype: object
0 Cash
dtype: object
# Replacing the missing values for the below with the most frequently appearing values from above
finaldata.loc[pd.isnull(finaldata['CREDIT_ACTIVE']),'CREDIT_ACTIVE'] = "Active"
finaldata.loc[pd.isnull(finaldata['CREDIT_CURRENCY']),'CREDIT_CURRENCY'] = "currency 1"
finaldata.loc[pd.isnull(finaldata['CREDIT_TYPE']),'CREDIT_TYPE'] = "Consumer credit"
finaldata.loc[pd.isnull(finaldata['NAME_CONTRACT_STATUS_x']),'NAME_CONTRACT_STATUS_x'] = "Completed"
finaldata.loc[pd.isnull(finaldata['NAME_CONTRACT_TYPE_y']),'NAME_CONTRACT_TYPE_y'] = "Cash loans"
finaldata.loc[pd.isnull(finaldata['WEEKDAY_APPR_PROCESS_START_y']),'WEEKDAY_APPR_PROCESS_START_y'] = "MONDAY"
finaldata.loc[pd.isnull(finaldata['FLAG_LAST_APPL_PER_CONTRACT']),'FLAG_LAST_APPL_PER_CONTRACT'] = "Y"
finaldata.loc[pd.isnull(finaldata['NAME_CASH_LOAN_PURPOSE']),'NAME_CASH_LOAN_PURPOSE'] = "XAP"
finaldata.loc[pd.isnull(finaldata['NAME_CONTRACT_STATUS']),'NAME_CONTRACT_STATUS'] = "Approved"
finaldata.loc[pd.isnull(finaldata['NAME_PAYMENT_TYPE']),'NAME_PAYMENT_TYPE'] = "Cash through the bank"
finaldata.loc[pd.isnull(finaldata['CODE_REJECT_REASON']),'CODE_REJECT_REASON'] = "XAP"
finaldata.loc[pd.isnull(finaldata['NAME_TYPE_SUITE_y']),'NAME_TYPE_SUITE_y'] = "Unaccompanied"
finaldata.loc[pd.isnull(finaldata['NAME_CLIENT_TYPE']),'NAME_CLIENT_TYPE'] = "Repeater"
finaldata.loc[pd.isnull(finaldata['NAME_GOODS_CATEGORY']),'NAME_GOODS_CATEGORY'] = "XNA"
finaldata.loc[pd.isnull(finaldata['NAME_PORTFOLIO']),'NAME_PORTFOLIO'] = "POS"
finaldata.loc[pd.isnull(finaldata['NAME_PRODUCT_TYPE']),'NAME_PRODUCT_TYPE'] = "XNA"
finaldata.loc[pd.isnull(finaldata['CHANNEL_TYPE']),'CHANNEL_TYPE'] = "Credit and cash offices"
finaldata.loc[pd.isnull(finaldata['NAME_SELLER_INDUSTRY']),'NAME_SELLER_INDUSTRY'] = "XNA"
finaldata.loc[pd.isnull(finaldata['NAME_YIELD_GROUP']),'NAME_YIELD_GROUP'] = "XNA"
finaldata.loc[pd.isnull(finaldata['PRODUCT_COMBINATION']),'PRODUCT_COMBINATION'] = "Cash"
finaldata.isnull().sum()
SK_ID_CURR 0
TARGET 0
NAME_CONTRACT_TYPE_x 0
CODE_GENDER 0
FLAG_OWN_CAR 0
FLAG_OWN_REALTY 0
CNT_CHILDREN 0
AMT_INCOME_TOTAL 0
AMT_CREDIT_x 0
AMT_ANNUITY_x 0
AMT_GOODS_PRICE_x 0
NAME_TYPE_SUITE_x 0
NAME_INCOME_TYPE 0
NAME_EDUCATION_TYPE 0
NAME_FAMILY_STATUS 0
NAME_HOUSING_TYPE 0
REGION_POPULATION_RELATIVE 0
DAYS_BIRTH 0
DAYS_EMPLOYED 0
DAYS_REGISTRATION 0
DAYS_ID_PUBLISH 0
FLAG_MOBIL 0
FLAG_EMP_PHONE 0
FLAG_WORK_PHONE 0
FLAG_CONT_MOBILE 0
FLAG_PHONE 0
FLAG_EMAIL 0
OCCUPATION_TYPE 0
CNT_FAM_MEMBERS 0
REGION_RATING_CLIENT 0
REGION_RATING_CLIENT_W_CITY 0
WEEKDAY_APPR_PROCESS_START_x 0
HOUR_APPR_PROCESS_START_x 0
REG_REGION_NOT_LIVE_REGION 0
REG_REGION_NOT_WORK_REGION 0
LIVE_REGION_NOT_WORK_REGION 0
REG_CITY_NOT_LIVE_CITY 0
REG_CITY_NOT_WORK_CITY 0
LIVE_CITY_NOT_WORK_CITY 0
ORGANIZATION_TYPE 0
EXT_SOURCE_2 0
EXT_SOURCE_3 0
YEARS_BEGINEXPLUATATION_AVG 0
FLOORSMAX_AVG 0
YEARS_BEGINEXPLUATATION_MODE 0
FLOORSMAX_MODE 0
YEARS_BEGINEXPLUATATION_MEDI 0
FLOORSMAX_MEDI 0
TOTALAREA_MODE 0
EMERGENCYSTATE_MODE 0
OBS_30_CNT_SOCIAL_CIRCLE 0
DEF_30_CNT_SOCIAL_CIRCLE 0
OBS_60_CNT_SOCIAL_CIRCLE 0
DEF_60_CNT_SOCIAL_CIRCLE 0
DAYS_LAST_PHONE_CHANGE 0
FLAG_DOCUMENT_2 0
FLAG_DOCUMENT_3 0
FLAG_DOCUMENT_4 0
FLAG_DOCUMENT_5 0
FLAG_DOCUMENT_6 0
FLAG_DOCUMENT_7 0
FLAG_DOCUMENT_8 0
FLAG_DOCUMENT_9 0
FLAG_DOCUMENT_10 0
FLAG_DOCUMENT_11 0
FLAG_DOCUMENT_12 0
FLAG_DOCUMENT_13 0
FLAG_DOCUMENT_14 0
FLAG_DOCUMENT_15 0
FLAG_DOCUMENT_16 0
FLAG_DOCUMENT_17 0
FLAG_DOCUMENT_18 0
FLAG_DOCUMENT_19 0
FLAG_DOCUMENT_20 0
FLAG_DOCUMENT_21 0
AMT_REQ_CREDIT_BUREAU_HOUR 0
AMT_REQ_CREDIT_BUREAU_DAY 0
AMT_REQ_CREDIT_BUREAU_WEEK 0
AMT_REQ_CREDIT_BUREAU_MON 0
AMT_REQ_CREDIT_BUREAU_QRT 0
AMT_REQ_CREDIT_BUREAU_YEAR 0
CREDIT_ACTIVE 0
CREDIT_CURRENCY 0
DAYS_CREDIT 0
CREDIT_DAY_OVERDUE 0
DAYS_CREDIT_ENDDATE 0
DAYS_ENDDATE_FACT 0
CNT_CREDIT_PROLONG 0
AMT_CREDIT_SUM 0
AMT_CREDIT_SUM_DEBT 0
AMT_CREDIT_SUM_LIMIT 0
AMT_CREDIT_SUM_OVERDUE 0
CREDIT_TYPE 0
DAYS_CREDIT_UPDATE 0
MONTHS_BALANCE_y 0
CNT_INSTALMENT 0
CNT_INSTALMENT_FUTURE 0
NAME_CONTRACT_STATUS_x 0
SK_DPD_x 0
SK_DPD_DEF_x 0
NUM_INSTALMENT_VERSION 0
NUM_INSTALMENT_NUMBER 0
DAYS_INSTALMENT 0
DAYS_ENTRY_PAYMENT 0
AMT_INSTALMENT 0
AMT_PAYMENT 0
NAME_CONTRACT_TYPE_y 0
AMT_ANNUITY_y 0
AMT_APPLICATION 0
AMT_CREDIT_y 0
AMT_GOODS_PRICE_y 0
WEEKDAY_APPR_PROCESS_START_y 0
HOUR_APPR_PROCESS_START_y 0
FLAG_LAST_APPL_PER_CONTRACT 0
NFLAG_LAST_APPL_IN_DAY 0
NAME_CASH_LOAN_PURPOSE 0
NAME_CONTRACT_STATUS 0
DAYS_DECISION 0
NAME_PAYMENT_TYPE 0
CODE_REJECT_REASON 0
NAME_TYPE_SUITE_y 0
NAME_CLIENT_TYPE 0
NAME_GOODS_CATEGORY 0
NAME_PORTFOLIO 0
NAME_PRODUCT_TYPE 0
CHANNEL_TYPE 0
SELLERPLACE_AREA 0
NAME_SELLER_INDUSTRY 0
CNT_PAYMENT 0
NAME_YIELD_GROUP 0
PRODUCT_COMBINATION 0
DAYS_FIRST_DRAWING 0
DAYS_FIRST_DUE 0
DAYS_LAST_DUE_1ST_VERSION 0
DAYS_LAST_DUE 0
DAYS_TERMINATION 0
NFLAG_INSURED_ON_APPROVAL 0
dtype: int64
#Export the file
finaldata.to_csv('final_homeloan_data.csv')
from google.colab import files
files.download("final_homeloan_data.csv")
<IPython.core.display.Javascript object>
<IPython.core.display.Javascript object>
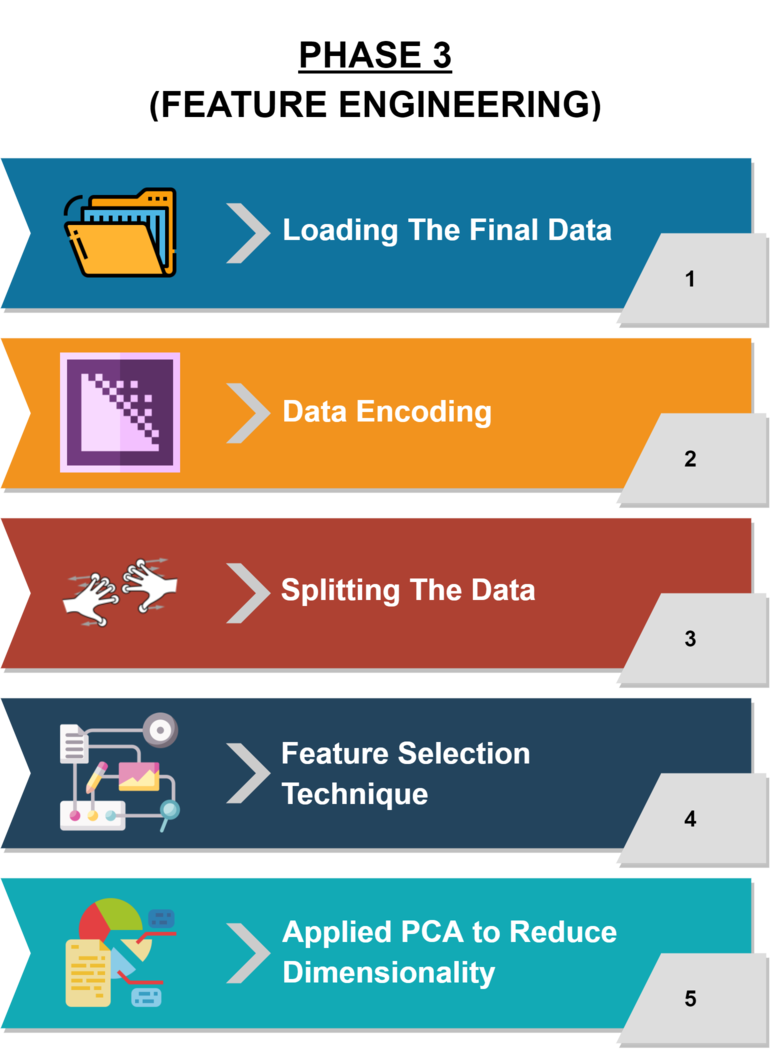
import numpy as np
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns',999) #set column display number
pd.set_option('display.max_rows',200) #set row display number
pd.set_option('float_format', '{:f}'.format) #set float format
from google.colab import drive
drive.mount('/content/grive')
Mounted at /content/grive
1. Loading The Final Data
#Loading the dataset
data = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/final_homeloan_data.csv')
data.drop(['Unnamed: 0', 'SK_ID_CURR'], axis = 1, inplace = True)
data.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| TARGET | 1 | 0 | 0 | 0 | 0 |
| NAME_CONTRACT_TYPE_x | Cash loans | Cash loans | Revolving loans | Cash loans | Cash loans |
| CODE_GENDER | M | F | M | F | M |
| FLAG_OWN_CAR | N | N | Y | N | N |
| FLAG_OWN_REALTY | Y | N | Y | Y | Y |
| CNT_CHILDREN | 0 | 0 | 0 | 0 | 0 |
| AMT_INCOME_TOTAL | 202500.000000 | 270000.000000 | 67500.000000 | 135000.000000 | 121500.000000 |
| AMT_CREDIT_x | 406597.500000 | 1293502.500000 | 135000.000000 | 312682.500000 | 513000.000000 |
| AMT_ANNUITY_x | 24700.500000 | 35698.500000 | 6750.000000 | 29686.500000 | 21865.500000 |
| AMT_GOODS_PRICE_x | 351000.000000 | 1129500.000000 | 135000.000000 | 297000.000000 | 513000.000000 |
| NAME_TYPE_SUITE_x | Unaccompanied | Family | Unaccompanied | Unaccompanied | Unaccompanied |
| NAME_INCOME_TYPE | Working | State servant | Working | Working | Working |
| NAME_EDUCATION_TYPE | Secondary / secondary special | Higher education | Secondary / secondary special | Secondary / secondary special | Secondary / secondary special |
| NAME_FAMILY_STATUS | Single / not married | Married | Single / not married | Civil marriage | Single / not married |
| NAME_HOUSING_TYPE | House / apartment | House / apartment | House / apartment | House / apartment | House / apartment |
| REGION_POPULATION_RELATIVE | 0.018801 | 0.003541 | 0.010032 | 0.008019 | 0.028663 |
| DAYS_BIRTH | -9461 | -16765 | -19046 | -19005 | -19932 |
| DAYS_EMPLOYED | -637 | -1188 | -225 | -3039 | -3038 |
| DAYS_REGISTRATION | -3648.000000 | -1186.000000 | -4260.000000 | -9833.000000 | -4311.000000 |
| DAYS_ID_PUBLISH | -2120 | -291 | -2531 | -2437 | -3458 |
| FLAG_MOBIL | 1 | 1 | 1 | 1 | 1 |
| FLAG_EMP_PHONE | 1 | 1 | 1 | 1 | 1 |
| FLAG_WORK_PHONE | 0 | 0 | 1 | 0 | 0 |
| FLAG_CONT_MOBILE | 1 | 1 | 1 | 1 | 1 |
| FLAG_PHONE | 1 | 1 | 1 | 0 | 0 |
| FLAG_EMAIL | 0 | 0 | 0 | 0 | 0 |
| OCCUPATION_TYPE | Laborers | Core staff | Laborers | Laborers | Core staff |
| CNT_FAM_MEMBERS | 1.000000 | 2.000000 | 1.000000 | 2.000000 | 1.000000 |
| REGION_RATING_CLIENT | 2 | 1 | 2 | 2 | 2 |
| REGION_RATING_CLIENT_W_CITY | 2 | 1 | 2 | 2 | 2 |
| WEEKDAY_APPR_PROCESS_START_x | WEDNESDAY | MONDAY | MONDAY | WEDNESDAY | THURSDAY |
| HOUR_APPR_PROCESS_START_x | 10 | 11 | 9 | 17 | 11 |
| REG_REGION_NOT_LIVE_REGION | 0 | 0 | 0 | 0 | 0 |
| REG_REGION_NOT_WORK_REGION | 0 | 0 | 0 | 0 | 0 |
| LIVE_REGION_NOT_WORK_REGION | 0 | 0 | 0 | 0 | 0 |
| REG_CITY_NOT_LIVE_CITY | 0 | 0 | 0 | 0 | 0 |
| REG_CITY_NOT_WORK_CITY | 0 | 0 | 0 | 0 | 1 |
| LIVE_CITY_NOT_WORK_CITY | 0 | 0 | 0 | 0 | 1 |
| ORGANIZATION_TYPE | Business Entity Type 3 | School | Government | Business Entity Type 3 | Religion |
| EXT_SOURCE_2 | 0.262949 | 0.622246 | 0.555912 | 0.650442 | 0.322738 |
| EXT_SOURCE_3 | 0.139376 | 0.510853 | 0.729567 | 0.510853 | 0.510853 |
| YEARS_BEGINEXPLUATATION_AVG | 0.972200 | 0.985100 | 0.977735 | 0.977735 | 0.977735 |
| FLOORSMAX_AVG | 0.083300 | 0.291700 | 0.226282 | 0.226282 | 0.226282 |
| YEARS_BEGINEXPLUATATION_MODE | 0.972200 | 0.985100 | 0.977065 | 0.977065 | 0.977065 |
| FLOORSMAX_MODE | 0.083300 | 0.291700 | 0.222315 | 0.222315 | 0.222315 |
| YEARS_BEGINEXPLUATATION_MEDI | 0.972200 | 0.985100 | 0.977752 | 0.977752 | 0.977752 |
| FLOORSMAX_MEDI | 0.083300 | 0.291700 | 0.225897 | 0.225897 | 0.225897 |
| TOTALAREA_MODE | 0.014900 | 0.071400 | 0.102547 | 0.102547 | 0.102547 |
| EMERGENCYSTATE_MODE | No | No | 0 | 0 | 0 |
| OBS_30_CNT_SOCIAL_CIRCLE | 2.000000 | 1.000000 | 0.000000 | 2.000000 | 0.000000 |
| DEF_30_CNT_SOCIAL_CIRCLE | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| OBS_60_CNT_SOCIAL_CIRCLE | 2.000000 | 1.000000 | 0.000000 | 2.000000 | 0.000000 |
| DEF_60_CNT_SOCIAL_CIRCLE | 2.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| DAYS_LAST_PHONE_CHANGE | -1134.000000 | -828.000000 | -815.000000 | -617.000000 | -1106.000000 |
| FLAG_DOCUMENT_2 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_3 | 1 | 1 | 0 | 1 | 0 |
| FLAG_DOCUMENT_4 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_5 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_6 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_7 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_8 | 0 | 0 | 0 | 0 | 1 |
| FLAG_DOCUMENT_9 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_10 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_11 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_12 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_13 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_14 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_15 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_16 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_17 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_18 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_19 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_20 | 0 | 0 | 0 | 0 | 0 |
| FLAG_DOCUMENT_21 | 0 | 0 | 0 | 0 | 0 |
| AMT_REQ_CREDIT_BUREAU_HOUR | 0.000000 | 0.000000 | 0.000000 | 0.006402 | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_DAY | 0.000000 | 0.000000 | 0.000000 | 0.007000 | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_WEEK | 0.000000 | 0.000000 | 0.000000 | 0.034362 | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_MON | 0.000000 | 0.000000 | 0.000000 | 0.267395 | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_QRT | 0.000000 | 0.000000 | 0.000000 | 0.265474 | 0.000000 |
| AMT_REQ_CREDIT_BUREAU_YEAR | 1.000000 | 0.000000 | 0.000000 | 1.899974 | 0.000000 |
| CREDIT_ACTIVE | Active | Active | Closed | Active | Closed |
| CREDIT_CURRENCY | currency 1 | currency 1 | currency 1 | currency 1 | currency 1 |
| DAYS_CREDIT | -103.000000 | -606.000000 | -408.000000 | -489.297817 | -1149.000000 |
| CREDIT_DAY_OVERDUE | 0.000000 | 0.000000 | 0.000000 | 0.473963 | 0.000000 |
| DAYS_CREDIT_ENDDATE | 510.517362 | 1216.000000 | -382.000000 | 1548.603740 | -783.000000 |
| DAYS_ENDDATE_FACT | -1017.437148 | -1017.437148 | -382.000000 | -888.088117 | -783.000000 |
| CNT_CREDIT_PROLONG | 0.000000 | 0.000000 | 0.000000 | 0.004554 | 0.000000 |
| AMT_CREDIT_SUM | 31988.565000 | 810000.000000 | 94537.800000 | 474764.762905 | 146250.000000 |
| AMT_CREDIT_SUM_DEBT | 0.000000 | 0.000000 | 0.000000 | 278160.418613 | 0.000000 |
| AMT_CREDIT_SUM_LIMIT | 31988.565000 | 810000.000000 | 0.000000 | 6933.561227 | 0.000000 |
| AMT_CREDIT_SUM_OVERDUE | 0.000000 | 0.000000 | 0.000000 | 59.186136 | 0.000000 |
| CREDIT_TYPE | Credit card | Credit card | Consumer credit | Consumer credit | Consumer credit |
| DAYS_CREDIT_UPDATE | -24.000000 | -43.000000 | -382.000000 | -188.029212 | -783.000000 |
| MONTHS_BALANCE_y | -1.000000 | -18.000000 | -24.000000 | -1.000000 | -1.000000 |
| CNT_INSTALMENT | 24.000000 | 7.000000 | 3.000000 | 12.000000 | 24.000000 |
| CNT_INSTALMENT_FUTURE | 6.000000 | 0.000000 | 0.000000 | 3.000000 | 13.000000 |
| NAME_CONTRACT_STATUS_x | Active | Completed | Completed | Active | Active |
| SK_DPD_x | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| SK_DPD_DEF_x | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| NUM_INSTALMENT_VERSION | 2.000000 | 2.000000 | 2.000000 | 1.000000 | 1.000000 |
| NUM_INSTALMENT_NUMBER | 19.000000 | 7.000000 | 3.000000 | 10.000000 | 12.000000 |
| DAYS_INSTALMENT | -25.000000 | -536.000000 | -724.000000 | -11.000000 | -14.000000 |
| DAYS_ENTRY_PAYMENT | -49.000000 | -544.000000 | -727.000000 | -12.000000 | -14.000000 |
| AMT_INSTALMENT | 53093.745000 | 560835.360000 | 10573.965000 | 29027.520000 | 16037.640000 |
| AMT_PAYMENT | 53093.745000 | 560835.360000 | 10573.965000 | 29027.520000 | 16037.640000 |
| NAME_CONTRACT_TYPE_y | Consumer loans | Cash loans | Consumer loans | Cash loans | Cash loans |
| AMT_ANNUITY_y | 9251.775000 | 98356.995000 | 5357.250000 | 24246.000000 | 16037.640000 |
| AMT_APPLICATION | 179055.000000 | 900000.000000 | 24282.000000 | 675000.000000 | 247500.000000 |
| AMT_CREDIT_y | 179055.000000 | 1035882.000000 | 20106.000000 | 675000.000000 | 274288.500000 |
| AMT_GOODS_PRICE_y | 179055.000000 | 900000.000000 | 24282.000000 | 675000.000000 | 247500.000000 |
| WEEKDAY_APPR_PROCESS_START_y | SATURDAY | FRIDAY | FRIDAY | THURSDAY | MONDAY |
| HOUR_APPR_PROCESS_START_y | 9.000000 | 12.000000 | 5.000000 | 15.000000 | 11.000000 |
| FLAG_LAST_APPL_PER_CONTRACT | Y | Y | Y | Y | Y |
| NFLAG_LAST_APPL_IN_DAY | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| NAME_CASH_LOAN_PURPOSE | XAP | XNA | XAP | XNA | XNA |
| NAME_CONTRACT_STATUS | Approved | Approved | Approved | Approved | Approved |
| DAYS_DECISION | -606.000000 | -746.000000 | -815.000000 | -181.000000 | -374.000000 |
| NAME_PAYMENT_TYPE | XNA | XNA | Cash through the bank | Cash through the bank | Cash through the bank |
| CODE_REJECT_REASON | XAP | XAP | XAP | XAP | XAP |
| NAME_TYPE_SUITE_y | Unaccompanied | Unaccompanied | Unaccompanied | Unaccompanied | Unaccompanied |
| NAME_CLIENT_TYPE | New | Repeater | New | Repeater | Repeater |
| NAME_GOODS_CATEGORY | Vehicles | XNA | Mobile | XNA | XNA |
| NAME_PORTFOLIO | POS | Cash | POS | Cash | Cash |
| NAME_PRODUCT_TYPE | XNA | x-sell | XNA | x-sell | x-sell |
| CHANNEL_TYPE | Stone | Credit and cash offices | Regional / Local | Credit and cash offices | Credit and cash offices |
| SELLERPLACE_AREA | 500.000000 | -1.000000 | 30.000000 | -1.000000 | -1.000000 |
| NAME_SELLER_INDUSTRY | Auto technology | XNA | Connectivity | XNA | XNA |
| CNT_PAYMENT | 24.000000 | 12.000000 | 4.000000 | 48.000000 | 24.000000 |
| NAME_YIELD_GROUP | low_normal | low_normal | middle | low_normal | middle |
| PRODUCT_COMBINATION | POS other with interest | Cash X-Sell: low | POS mobile without interest | Cash X-Sell: low | Cash X-Sell: middle |
| DAYS_FIRST_DRAWING | 365243.000000 | 365243.000000 | 365243.000000 | 365243.000000 | 365243.000000 |
| DAYS_FIRST_DUE | -565.000000 | -716.000000 | -784.000000 | -151.000000 | -344.000000 |
| DAYS_LAST_DUE_1ST_VERSION | 125.000000 | -386.000000 | -694.000000 | 1259.000000 | 346.000000 |
| DAYS_LAST_DUE | -25.000000 | -536.000000 | -724.000000 | -151.000000 | 365243.000000 |
| DAYS_TERMINATION | -17.000000 | -527.000000 | -714.000000 | -143.000000 | 365243.000000 |
| NFLAG_INSURED_ON_APPROVAL | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
2. Data Encoding
from sklearn.preprocessing import LabelEncoder
# ENCODING THE ENTIRE DATA SET
label = LabelEncoder()
data1 = data.apply(label.fit_transform)
data1.head()
| TARGET | NAME_CONTRACT_TYPE_x | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT_x | AMT_ANNUITY_x | AMT_GOODS_PRICE_x | NAME_TYPE_SUITE_x | NAME_INCOME_TYPE | NAME_EDUCATION_TYPE | NAME_FAMILY_STATUS | NAME_HOUSING_TYPE | REGION_POPULATION_RELATIVE | DAYS_BIRTH | DAYS_EMPLOYED | DAYS_REGISTRATION | DAYS_ID_PUBLISH | FLAG_MOBIL | FLAG_EMP_PHONE | FLAG_WORK_PHONE | FLAG_CONT_MOBILE | FLAG_PHONE | FLAG_EMAIL | OCCUPATION_TYPE | CNT_FAM_MEMBERS | REGION_RATING_CLIENT | REGION_RATING_CLIENT_W_CITY | WEEKDAY_APPR_PROCESS_START_x | HOUR_APPR_PROCESS_START_x | REG_REGION_NOT_LIVE_REGION | REG_REGION_NOT_WORK_REGION | LIVE_REGION_NOT_WORK_REGION | REG_CITY_NOT_LIVE_CITY | REG_CITY_NOT_WORK_CITY | LIVE_CITY_NOT_WORK_CITY | ORGANIZATION_TYPE | EXT_SOURCE_2 | EXT_SOURCE_3 | YEARS_BEGINEXPLUATATION_AVG | FLOORSMAX_AVG | YEARS_BEGINEXPLUATATION_MODE | FLOORSMAX_MODE | YEARS_BEGINEXPLUATATION_MEDI | FLOORSMAX_MEDI | TOTALAREA_MODE | EMERGENCYSTATE_MODE | OBS_30_CNT_SOCIAL_CIRCLE | DEF_30_CNT_SOCIAL_CIRCLE | OBS_60_CNT_SOCIAL_CIRCLE | DEF_60_CNT_SOCIAL_CIRCLE | DAYS_LAST_PHONE_CHANGE | FLAG_DOCUMENT_2 | FLAG_DOCUMENT_3 | FLAG_DOCUMENT_4 | FLAG_DOCUMENT_5 | FLAG_DOCUMENT_6 | FLAG_DOCUMENT_7 | FLAG_DOCUMENT_8 | FLAG_DOCUMENT_9 | FLAG_DOCUMENT_10 | FLAG_DOCUMENT_11 | FLAG_DOCUMENT_12 | FLAG_DOCUMENT_13 | FLAG_DOCUMENT_14 | FLAG_DOCUMENT_15 | FLAG_DOCUMENT_16 | FLAG_DOCUMENT_17 | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | CREDIT_ACTIVE | CREDIT_CURRENCY | DAYS_CREDIT | CREDIT_DAY_OVERDUE | DAYS_CREDIT_ENDDATE | DAYS_ENDDATE_FACT | CNT_CREDIT_PROLONG | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_SUM_LIMIT | AMT_CREDIT_SUM_OVERDUE | CREDIT_TYPE | DAYS_CREDIT_UPDATE | MONTHS_BALANCE_y | CNT_INSTALMENT | CNT_INSTALMENT_FUTURE | NAME_CONTRACT_STATUS_x | SK_DPD_x | SK_DPD_DEF_x | NUM_INSTALMENT_VERSION | NUM_INSTALMENT_NUMBER | DAYS_INSTALMENT | DAYS_ENTRY_PAYMENT | AMT_INSTALMENT | AMT_PAYMENT | NAME_CONTRACT_TYPE_y | AMT_ANNUITY_y | AMT_APPLICATION | AMT_CREDIT_y | AMT_GOODS_PRICE_y | WEEKDAY_APPR_PROCESS_START_y | HOUR_APPR_PROCESS_START_y | FLAG_LAST_APPL_PER_CONTRACT | NFLAG_LAST_APPL_IN_DAY | NAME_CASH_LOAN_PURPOSE | NAME_CONTRACT_STATUS | DAYS_DECISION | NAME_PAYMENT_TYPE | CODE_REJECT_REASON | NAME_TYPE_SUITE_y | NAME_CLIENT_TYPE | NAME_GOODS_CATEGORY | NAME_PORTFOLIO | NAME_PRODUCT_TYPE | CHANNEL_TYPE | SELLERPLACE_AREA | NAME_SELLER_INDUSTRY | CNT_PAYMENT | NAME_YIELD_GROUP | PRODUCT_COMBINATION | DAYS_FIRST_DRAWING | DAYS_FIRST_DUE | DAYS_LAST_DUE_1ST_VERSION | DAYS_LAST_DUE | DAYS_TERMINATION | NFLAG_INSURED_ON_APPROVAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1754 | 1191 | 4588 | 189 | 6 | 7 | 4 | 3 | 1 | 63 | 15684 | 11935 | 12039 | 4047 | 1 | 1 | 0 | 1 | 1 | 0 | 8 | 0 | 1 | 1 | 6 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 28075 | 287 | 228 | 38 | 164 | 2 | 188 | 4 | 149 | 1 | 3 | 3 | 3 | 3 | 2638 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 2820 | 0 | 3253 | 1727 | 0 | 5846 | 335 | 6658 | 0 | 3 | 2674 | 96 | 25 | 7 | 0 | 0 | 0 | 3 | 19 | 2894 | 2894 | 174043 | 173172 | 1 | 50021 | 32029 | 33525 | 32028 | 2 | 9 | 1 | 2 | 23 | 0 | 2316 | 3 | 7 | 6 | 0 | 23 | 3 | 0 | 7 | 492 | 0 | 22 | 3 | 15 | 1966 | 2326 | 2867 | 2735 | 2665 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2064 | 4338 | 6986 | 705 | 1 | 4 | 1 | 1 | 1 | 11 | 8382 | 11384 | 14501 | 5876 | 1 | 1 | 0 | 1 | 1 | 0 | 3 | 1 | 0 | 0 | 1 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 39 | 85082 | 546 | 255 | 192 | 191 | 8 | 215 | 15 | 714 | 1 | 1 | 0 | 1 | 0 | 2945 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2316 | 0 | 3959 | 1727 | 0 | 55263 | 335 | 12069 | 0 | 3 | 2655 | 78 | 6 | 0 | 3 | 0 | 0 | 3 | 6 | 2382 | 2398 | 209485 | 208544 | 0 | 119118 | 41465 | 48414 | 41466 | 0 | 12 | 1 | 2 | 24 | 0 | 2176 | 3 | 7 | 6 | 2 | 25 | 2 | 2 | 5 | 0 | 10 | 10 | 3 | 7 | 1966 | 2175 | 2356 | 2224 | 2155 | 3 |
| 2 | 0 | 1 | 1 | 1 | 1 | 0 | 338 | 228 | 662 | 30 | 6 | 7 | 4 | 3 | 1 | 47 | 6101 | 12347 | 11427 | 3636 | 1 | 1 | 1 | 1 | 1 | 0 | 8 | 0 | 1 | 1 | 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 72834 | 678 | 240 | 148 | 174 | 6 | 200 | 11 | 1026 | 0 | 0 | 0 | 0 | 0 | 2958 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 2515 | 0 | 2360 | 2364 | 0 | 25147 | 335 | 40 | 0 | 2 | 2315 | 72 | 2 | 0 | 3 | 0 | 0 | 3 | 2 | 2194 | 2215 | 76769 | 77753 | 1 | 21104 | 2135 | 1606 | 2135 | 0 | 5 | 1 | 2 | 23 | 0 | 2107 | 0 | 7 | 6 | 0 | 17 | 3 | 0 | 6 | 31 | 2 | 2 | 4 | 14 | 1966 | 2107 | 2048 | 2036 | 1968 | 0 |
| 3 | 0 | 0 | 0 | 0 | 1 | 0 | 1170 | 836 | 5681 | 145 | 6 | 7 | 4 | 0 | 1 | 34 | 6142 | 9533 | 5854 | 3730 | 1 | 1 | 0 | 1 | 0 | 0 | 8 | 1 | 1 | 1 | 6 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 90562 | 546 | 240 | 148 | 174 | 6 | 200 | 11 | 1026 | 0 | 3 | 0 | 3 | 0 | 3156 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 2 | 0 | 0 | 2433 | 1 | 4292 | 1857 | 1 | 51526 | 54916 | 3138 | 61 | 2 | 2509 | 96 | 11 | 3 | 0 | 0 | 0 | 1 | 9 | 2908 | 2931 | 148025 | 147472 | 0 | 100734 | 41142 | 46879 | 41143 | 4 | 16 | 1 | 2 | 24 | 0 | 2742 | 0 | 7 | 6 | 2 | 25 | 2 | 2 | 5 | 0 | 10 | 34 | 3 | 7 | 1966 | 2740 | 4001 | 2609 | 2539 | 0 |
| 4 | 0 | 0 | 1 | 0 | 1 | 0 | 1019 | 1635 | 3960 | 352 | 6 | 7 | 4 | 3 | 1 | 74 | 5215 | 9534 | 11376 | 2709 | 1 | 1 | 0 | 1 | 0 | 0 | 3 | 0 | 1 | 1 | 4 | 11 | 0 | 0 | 0 | 0 | 1 | 1 | 37 | 36023 | 546 | 240 | 148 | 174 | 6 | 200 | 11 | 1026 | 0 | 0 | 0 | 0 | 0 | 2666 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 1773 | 0 | 1959 | 1963 | 0 | 36288 | 335 | 40 | 0 | 2 | 1914 | 96 | 25 | 15 | 0 | 0 | 0 | 1 | 11 | 2905 | 2929 | 109122 | 109331 | 0 | 83873 | 36206 | 40167 | 36207 | 1 | 11 | 1 | 2 | 24 | 0 | 2549 | 0 | 7 | 6 | 2 | 25 | 2 | 2 | 5 | 0 | 10 | 22 | 4 | 8 | 1966 | 2547 | 3088 | 2761 | 2683 | 3 |
3. Splitting The Data
# splitting the data into X and Y so we can do PCA
x = data1.drop('TARGET', axis=1)
y = data1['TARGET']
print(x.head())
y.head()
NAME_CONTRACT_TYPE_x CODE_GENDER FLAG_OWN_CAR FLAG_OWN_REALTY \
0 0 1 0 1
1 0 0 0 0
2 1 1 1 1
3 0 0 0 1
4 0 1 0 1
CNT_CHILDREN AMT_INCOME_TOTAL AMT_CREDIT_x AMT_ANNUITY_x \
0 0 1754 1191 4588
1 0 2064 4338 6986
2 0 338 228 662
3 0 1170 836 5681
4 0 1019 1635 3960
AMT_GOODS_PRICE_x NAME_TYPE_SUITE_x NAME_INCOME_TYPE \
0 189 6 7
1 705 1 4
2 30 6 7
3 145 6 7
4 352 6 7
NAME_EDUCATION_TYPE NAME_FAMILY_STATUS NAME_HOUSING_TYPE \
0 4 3 1
1 1 1 1
2 4 3 1
3 4 0 1
4 4 3 1
REGION_POPULATION_RELATIVE DAYS_BIRTH DAYS_EMPLOYED DAYS_REGISTRATION \
0 63 15684 11935 12039
1 11 8382 11384 14501
2 47 6101 12347 11427
3 34 6142 9533 5854
4 74 5215 9534 11376
DAYS_ID_PUBLISH FLAG_MOBIL FLAG_EMP_PHONE FLAG_WORK_PHONE \
0 4047 1 1 0
1 5876 1 1 0
2 3636 1 1 1
3 3730 1 1 0
4 2709 1 1 0
FLAG_CONT_MOBILE FLAG_PHONE FLAG_EMAIL OCCUPATION_TYPE CNT_FAM_MEMBERS \
0 1 1 0 8 0
1 1 1 0 3 1
2 1 1 0 8 0
3 1 0 0 8 1
4 1 0 0 3 0
REGION_RATING_CLIENT REGION_RATING_CLIENT_W_CITY \
0 1 1
1 0 0
2 1 1
3 1 1
4 1 1
WEEKDAY_APPR_PROCESS_START_x HOUR_APPR_PROCESS_START_x \
0 6 10
1 1 11
2 1 9
3 6 17
4 4 11
REG_REGION_NOT_LIVE_REGION REG_REGION_NOT_WORK_REGION \
0 0 0
1 0 0
2 0 0
3 0 0
4 0 0
LIVE_REGION_NOT_WORK_REGION REG_CITY_NOT_LIVE_CITY \
0 0 0
1 0 0
2 0 0
3 0 0
4 0 0
REG_CITY_NOT_WORK_CITY LIVE_CITY_NOT_WORK_CITY ORGANIZATION_TYPE \
0 0 0 5
1 0 0 39
2 0 0 11
3 0 0 5
4 1 1 37
EXT_SOURCE_2 EXT_SOURCE_3 YEARS_BEGINEXPLUATATION_AVG FLOORSMAX_AVG \
0 28075 287 228 38
1 85082 546 255 192
2 72834 678 240 148
3 90562 546 240 148
4 36023 546 240 148
YEARS_BEGINEXPLUATATION_MODE FLOORSMAX_MODE YEARS_BEGINEXPLUATATION_MEDI \
0 164 2 188
1 191 8 215
2 174 6 200
3 174 6 200
4 174 6 200
FLOORSMAX_MEDI TOTALAREA_MODE EMERGENCYSTATE_MODE \
0 4 149 1
1 15 714 1
2 11 1026 0
3 11 1026 0
4 11 1026 0
OBS_30_CNT_SOCIAL_CIRCLE DEF_30_CNT_SOCIAL_CIRCLE \
0 3 3
1 1 0
2 0 0
3 3 0
4 0 0
OBS_60_CNT_SOCIAL_CIRCLE DEF_60_CNT_SOCIAL_CIRCLE DAYS_LAST_PHONE_CHANGE \
0 3 3 2638
1 1 0 2945
2 0 0 2958
3 3 0 3156
4 0 0 2666
FLAG_DOCUMENT_2 FLAG_DOCUMENT_3 FLAG_DOCUMENT_4 FLAG_DOCUMENT_5 \
0 0 1 0 0
1 0 1 0 0
2 0 0 0 0
3 0 1 0 0
4 0 0 0 0
FLAG_DOCUMENT_6 FLAG_DOCUMENT_7 FLAG_DOCUMENT_8 FLAG_DOCUMENT_9 \
0 0 0 0 0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 1 0
FLAG_DOCUMENT_10 FLAG_DOCUMENT_11 FLAG_DOCUMENT_12 FLAG_DOCUMENT_13 \
0 0 0 0 0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
FLAG_DOCUMENT_14 FLAG_DOCUMENT_15 FLAG_DOCUMENT_16 FLAG_DOCUMENT_17 \
0 0 0 0 0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
FLAG_DOCUMENT_18 FLAG_DOCUMENT_19 FLAG_DOCUMENT_20 FLAG_DOCUMENT_21 \
0 0 0 0 0
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
AMT_REQ_CREDIT_BUREAU_HOUR AMT_REQ_CREDIT_BUREAU_DAY \
0 0 0
1 0 0
2 0 0
3 1 1
4 0 0
AMT_REQ_CREDIT_BUREAU_WEEK AMT_REQ_CREDIT_BUREAU_MON \
0 0 0
1 0 0
2 0 0
3 1 1
4 0 0
AMT_REQ_CREDIT_BUREAU_QRT AMT_REQ_CREDIT_BUREAU_YEAR CREDIT_ACTIVE \
0 0 1 0
1 0 0 0
2 0 0 2
3 1 2 0
4 0 0 2
CREDIT_CURRENCY DAYS_CREDIT CREDIT_DAY_OVERDUE DAYS_CREDIT_ENDDATE \
0 0 2820 0 3253
1 0 2316 0 3959
2 0 2515 0 2360
3 0 2433 1 4292
4 0 1773 0 1959
DAYS_ENDDATE_FACT CNT_CREDIT_PROLONG AMT_CREDIT_SUM AMT_CREDIT_SUM_DEBT \
0 1727 0 5846 335
1 1727 0 55263 335
2 2364 0 25147 335
3 1857 1 51526 54916
4 1963 0 36288 335
AMT_CREDIT_SUM_LIMIT AMT_CREDIT_SUM_OVERDUE CREDIT_TYPE \
0 6658 0 3
1 12069 0 3
2 40 0 2
3 3138 61 2
4 40 0 2
DAYS_CREDIT_UPDATE MONTHS_BALANCE_y CNT_INSTALMENT \
0 2674 96 25
1 2655 78 6
2 2315 72 2
3 2509 96 11
4 1914 96 25
CNT_INSTALMENT_FUTURE NAME_CONTRACT_STATUS_x SK_DPD_x SK_DPD_DEF_x \
0 7 0 0 0
1 0 3 0 0
2 0 3 0 0
3 3 0 0 0
4 15 0 0 0
NUM_INSTALMENT_VERSION NUM_INSTALMENT_NUMBER DAYS_INSTALMENT \
0 3 19 2894
1 3 6 2382
2 3 2 2194
3 1 9 2908
4 1 11 2905
DAYS_ENTRY_PAYMENT AMT_INSTALMENT AMT_PAYMENT NAME_CONTRACT_TYPE_y \
0 2894 174043 173172 1
1 2398 209485 208544 0
2 2215 76769 77753 1
3 2931 148025 147472 0
4 2929 109122 109331 0
AMT_ANNUITY_y AMT_APPLICATION AMT_CREDIT_y AMT_GOODS_PRICE_y \
0 50021 32029 33525 32028
1 119118 41465 48414 41466
2 21104 2135 1606 2135
3 100734 41142 46879 41143
4 83873 36206 40167 36207
WEEKDAY_APPR_PROCESS_START_y HOUR_APPR_PROCESS_START_y \
0 2 9
1 0 12
2 0 5
3 4 16
4 1 11
FLAG_LAST_APPL_PER_CONTRACT NFLAG_LAST_APPL_IN_DAY \
0 1 2
1 1 2
2 1 2
3 1 2
4 1 2
NAME_CASH_LOAN_PURPOSE NAME_CONTRACT_STATUS DAYS_DECISION \
0 23 0 2316
1 24 0 2176
2 23 0 2107
3 24 0 2742
4 24 0 2549
NAME_PAYMENT_TYPE CODE_REJECT_REASON NAME_TYPE_SUITE_y NAME_CLIENT_TYPE \
0 3 7 6 0
1 3 7 6 2
2 0 7 6 0
3 0 7 6 2
4 0 7 6 2
NAME_GOODS_CATEGORY NAME_PORTFOLIO NAME_PRODUCT_TYPE CHANNEL_TYPE \
0 23 3 0 7
1 25 2 2 5
2 17 3 0 6
3 25 2 2 5
4 25 2 2 5
SELLERPLACE_AREA NAME_SELLER_INDUSTRY CNT_PAYMENT NAME_YIELD_GROUP \
0 492 0 22 3
1 0 10 10 3
2 31 2 2 4
3 0 10 34 3
4 0 10 22 4
PRODUCT_COMBINATION DAYS_FIRST_DRAWING DAYS_FIRST_DUE \
0 15 1966 2326
1 7 1966 2175
2 14 1966 2107
3 7 1966 2740
4 8 1966 2547
DAYS_LAST_DUE_1ST_VERSION DAYS_LAST_DUE DAYS_TERMINATION \
0 2867 2735 2665
1 2356 2224 2155
2 2048 2036 1968
3 4001 2609 2539
4 3088 2761 2683
NFLAG_INSURED_ON_APPROVAL
0 0
1 3
2 0
3 0
4 3
0 1
1 0
2 0
3 0
4 0
Name: TARGET, dtype: int64
Doing the PCA would be perplexed for so many predictor variables so to reduce the dimensionality a little we are utilizing the feature selection technique first (which is more expeditious in computation) then we will do the PCA on those features that are selected from the feature selection technique.
4. Feature Selection Technique
# FEATURE SELECTION TECHNIQUE
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#apply SelectKBest class to extract top 40 best features
bestfeatures = SelectKBest(score_func=chi2, k=40)
fit = bestfeatures.fit(x,y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(x.columns)
#concat two dataframes for better visualization
featurescores = pd.concat([dfcolumns,dfscores], axis=1)
featurescores.columns = ['Specs', 'Score'] #naming the data
print(featurescores.nlargest(40, 'Score'))
Specs Score
38 EXT_SOURCE_2 100224179.217385
103 AMT_PAYMENT 24582287.818576
102 AMT_INSTALMENT 19253788.791688
87 AMT_CREDIT_SUM_DEBT 6670131.458588
15 DAYS_BIRTH 3933841.476373
106 AMT_APPLICATION 3633694.899670
107 AMT_CREDIT_y 3234515.650998
105 AMT_ANNUITY_y 2470279.732460
17 DAYS_REGISTRATION 622384.917048
18 DAYS_ID_PUBLISH 584562.794782
86 AMT_CREDIT_SUM 509090.058195
108 AMT_GOODS_PRICE_y 507360.660787
16 DAYS_EMPLOYED 310593.334671
6 AMT_CREDIT_x 237855.517778
52 DAYS_LAST_PHONE_CHANGE 228263.426009
39 EXT_SOURCE_3 198319.207224
83 DAYS_CREDIT_ENDDATE 174184.245046
124 SELLERPLACE_AREA 109388.167625
131 DAYS_LAST_DUE_1ST_VERSION 93480.784246
88 AMT_CREDIT_SUM_LIMIT 86949.824150
46 TOTALAREA_MODE 73998.725567
8 AMT_GOODS_PRICE_x 70714.389735
81 DAYS_CREDIT 63958.716458
7 AMT_ANNUITY_x 40779.977902
89 AMT_CREDIT_SUM_OVERDUE 36228.615578
5 AMT_INCOME_TOTAL 24916.054869
91 DAYS_CREDIT_UPDATE 14377.574226
130 DAYS_FIRST_DUE 12690.319997
84 DAYS_ENDDATE_FACT 9269.646448
115 DAYS_DECISION 8989.479098
41 FLOORSMAX_AVG 6035.404444
82 CREDIT_DAY_OVERDUE 5539.281446
37 ORGANIZATION_TYPE 4138.607485
132 DAYS_LAST_DUE 3864.559637
133 DAYS_TERMINATION 3799.499980
97 SK_DPD_DEF_x 3780.593456
96 SK_DPD_x 2835.307242
14 REGION_POPULATION_RELATIVE 1121.944777
79 CREDIT_ACTIVE 1087.711924
10 NAME_INCOME_TYPE 934.903558
# Using only the above 40 variables and creating an 'x' dataframe
x = x[['EXT_SOURCE_2', 'AMT_PAYMENT', 'AMT_INSTALMENT', 'AMT_CREDIT_SUM_DEBT', 'DAYS_BIRTH', 'AMT_APPLICATION', 'AMT_CREDIT_y', 'AMT_ANNUITY_y', 'DAYS_REGISTRATION', 'DAYS_ID_PUBLISH', 'AMT_CREDIT_SUM', 'AMT_GOODS_PRICE_y', 'DAYS_EMPLOYED', 'AMT_CREDIT_x', 'DAYS_LAST_PHONE_CHANGE', 'EXT_SOURCE_3','DAYS_CREDIT_ENDDATE', 'SELLERPLACE_AREA', 'DAYS_LAST_DUE_1ST_VERSION', 'AMT_CREDIT_SUM_LIMIT', 'TOTALAREA_MODE', 'AMT_GOODS_PRICE_x', 'DAYS_CREDIT', 'AMT_ANNUITY_x', 'AMT_CREDIT_SUM_OVERDUE', 'AMT_INCOME_TOTAL', 'DAYS_CREDIT_UPDATE', 'DAYS_FIRST_DUE', 'DAYS_ENDDATE_FACT', 'DAYS_DECISION', 'FLOORSMAX_AVG', 'CREDIT_DAY_OVERDUE', 'ORGANIZATION_TYPE', 'DAYS_LAST_DUE', 'DAYS_TERMINATION', 'SK_DPD_DEF_x', 'SK_DPD_x', 'REGION_POPULATION_RELATIVE', 'CREDIT_ACTIVE', 'NAME_INCOME_TYPE']]
5. Applied PCA to Reduce Dimensionality
First using Eigen vectors and Eigen values determine how many variables are contributing to the most amount of variance in the target variable
# Creating the covariance matrix
#feature scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_std = sc.fit_transform(x)
transpose = x_std.T #transpose
transpose_df = pd.DataFrame(data=transpose) #transpose dataframe
cov_mat = np.cov(transpose)
cov_mat
array([[ 1.00000325, 0.06379426, 0.06307348, ..., 0.12451804,
0.02445705, -0.08164812],
[ 0.06379426, 1.00000325, 0.97198103, ..., 0.00571141,
0.02781775, -0.05953216],
[ 0.06307348, 0.97198103, 1.00000325, ..., 0.00503074,
0.02643028, -0.06218962],
...,
[ 0.12451804, 0.00571141, 0.00503074, ..., 1.00000325,
0.00329329, -0.05371119],
[ 0.02445705, 0.02781775, 0.02643028, ..., 0.00329329,
1.00000325, -0.00970957],
[-0.08164812, -0.05953216, -0.06218962, ..., -0.05371119,
-0.00970957, 1.00000325]])
#calculating the Eigen values
eig_vals, eig_vecs = np.linalg.eig(cov_mat) #get eigen_values and eigen_vectors - linalg = linear algebra
print('Eigenvectors \n' , eig_vecs)
print('\nEigenvalues \n' ,eig_vals)
Eigenvectors
[[ 0.01553212 0.13344578 -0.0418386 ... -0.55900353 -0.26265831
-0.02705812]
[ 0.15789101 0.21137104 -0.06551048 ... 0.03975586 -0.04316571
0.02492131]
[ 0.15971109 0.21531479 -0.06544491 ... 0.04107885 -0.03978387
0.0165351 ]
...
[ 0.00301354 0.0493794 -0.00813963 ... 0.16577232 0.02187107
0.07645623]
[-0.00583673 -0.04524418 -0.44258456 ... 0.07258575 0.0651931
-0.00415331]
[-0.02177895 -0.0781661 0.04511367 ... -0.05308926 -0.37682247
0.06166666]]
Eigenvalues
[4.93365792 3.7590906 3.23606235 2.49229891 1.93042299 1.78952175
1.69505518 1.52344275 1.40103044 1.28999851 1.17124424 1.15675951
0.0159238 0.01801557 0.02768513 0.0323801 0.05639713 0.0663065
0.13819157 0.14597186 0.19769289 0.23310516 0.28518739 0.33683817
0.36132562 1.07005438 1.04524028 0.48444007 0.52063897 0.98044004
0.60376634 0.62827746 0.92043868 0.8913933 0.69500623 0.71195036
0.74112459 0.75850497 0.82377368 0.83147467]
In order to decide which eigenvector(s) can dropped without losing too much information for the construction of lower-dimensional subspace, we need to inspect the corresponding eigenvalues: The eigenvectors with the lowest eigenvalues bear the least information about the distribution of the data; those are the ones can be dropped.
In order to do so, the common approach is to rank the eigenvalues from highest to lowest in order choose the top-k eigenvectors.
eig_pairs1 = dict(zip(eig_vals , eig_vecs)) # zipping two variables and converting to dictionary
eigen_array = list(eig_pairs1.items()) #converting to list
eigen_array = np.array(eigen_array) #converting to array
print(eigen_array)
[[4.933657915561582
array([ 1.55321170e-02, 1.33445775e-01, -4.18385993e-02, 4.96910866e-02,
1.14786224e-01, 7.32410906e-02, -1.27439774e-01, -7.82964068e-02,
2.53251876e-01, 2.01110375e-01, -2.06684231e-02, 1.24692180e-01,
-3.32443463e-03, -1.75788673e-03, -1.18575373e-03, -3.05933711e-04,
3.00397479e-03, 1.64112171e-04, -4.28729615e-03, 1.54052222e-03,
3.10798128e-03, -1.16130199e-02, 1.32676785e-02, 1.46235590e-02,
-3.91823435e-03, 6.75355669e-02, -4.69220616e-01, 7.39040578e-02,
2.69839308e-02, 1.51927806e-01, -2.10453802e-01, -5.26100932e-02,
1.28201154e-01, -1.69456332e-01, -6.61669971e-02, 2.13082369e-01,
-1.93567149e-01, -5.59003526e-01, -2.62658308e-01, -2.70581154e-02])]
[3.759090602936672
array([ 1.57891008e-01, 2.11371039e-01, -6.55104776e-02, -2.03275885e-01,
-1.46243851e-01, -1.85853449e-02, 3.12953115e-02, 5.53326742e-01,
1.83737040e-01, 7.62172434e-03, 7.05842907e-03, 1.87312969e-02,
-4.59382080e-03, -1.62647873e-02, 7.02864429e-01, 1.62239400e-02,
4.23344967e-02, -4.99703544e-04, -2.62988550e-02, -4.41158910e-03,
9.20699908e-03, 6.93324248e-03, 1.90650226e-03, 1.07749061e-03,
-6.06386442e-02, -8.74918613e-02, -4.89184548e-02, -5.82804128e-03,
4.76764634e-03, -2.35776347e-02, -5.75033215e-03, 1.71078419e-02,
3.83954414e-02, 1.46109185e-02, 5.60058363e-02, -2.70458563e-02,
1.36742941e-02, 3.97558597e-02, -4.31657093e-02, 2.49213141e-02])]
[3.236062345473301
array([ 1.59711092e-01, 2.15314788e-01, -6.54449058e-02, -2.07154973e-01,
-1.47819684e-01, -1.93345030e-02, 3.11863786e-02, 5.47014520e-01,
1.81099896e-01, 5.46630414e-03, 1.39163799e-02, 1.42246293e-02,
3.37420497e-03, 1.11710239e-02, -7.09198484e-01, -9.85319609e-03,
-1.50959396e-02, -2.38578927e-03, -1.29199555e-02, -2.24018790e-02,
1.54709004e-02, -4.02450949e-03, -3.01618500e-03, 4.55284171e-04,
-4.43361289e-02, -8.49696074e-02, -4.69907598e-02, -6.13929188e-03,
5.42605784e-04, -2.36509489e-02, -5.61661765e-03, 1.86067975e-02,
3.62433592e-02, 1.14132724e-02, 5.45501696e-02, -2.27244096e-02,
8.90795239e-03, 4.10788484e-02, -3.97838722e-02, 1.65350960e-02])]
[2.492298912187957
array([ 1.04531252e-02, 1.17547027e-01, 3.69405188e-01, -1.08857733e-01,
2.35747193e-01, -1.25990322e-01, 5.15546186e-02, 1.36375522e-02,
1.01377998e-01, -1.33662795e-02, -7.30343977e-02, 1.38054573e-01,
7.51105616e-04, 1.30813318e-03, 5.65821564e-04, 5.63780507e-04,
-3.25542085e-04, 1.37645054e-02, 1.50321392e-02, 1.63479744e-02,
3.55883544e-01, -8.11064956e-02, 6.58936915e-01, 2.17585365e-02,
3.88159709e-02, 1.39896624e-01, 1.20215958e-01, 5.20658123e-02,
9.15017447e-02, 2.07647294e-01, -4.30402826e-02, 3.86210441e-02,
-1.73674868e-01, 7.98050465e-02, 7.36843486e-02, 6.49332967e-02,
-1.14726775e-01, 8.66682724e-02, 9.82851961e-03, 3.03897727e-03])]
[1.930422994249986
array([-8.12113730e-03, -4.90229014e-02, 1.36508569e-01, 1.17700511e-01,
-3.73142941e-01, -3.71856106e-01, -2.60609189e-02, -1.91141267e-02,
6.96264591e-03, -1.66583577e-02, 1.82105457e-02, -6.37119327e-02,
-6.14886585e-04, -1.43387345e-03, -3.91196284e-04, 3.19585762e-04,
-4.06676918e-03, -8.15677536e-04, -2.66620921e-02, 9.73217704e-03,
-8.60024081e-03, 5.69349856e-02, -1.28554901e-02, -9.87820455e-03,
-2.29773600e-02, 1.65778434e-01, -8.30516877e-02, 7.22261483e-01,
-1.89754040e-01, 7.59574758e-02, -3.93505229e-03, -4.21775364e-02,
6.87117775e-02, 2.35921717e-02, 5.17752330e-02, -2.41603739e-01,
-1.03765153e-01, -1.24271439e-03, 5.62514723e-03, -9.66418136e-03])]
[1.7895217451553862
array([ 8.66153520e-02, 2.52905115e-01, -7.87770155e-02, -3.63003494e-01,
-1.71779927e-01, -5.22498528e-02, 1.90457762e-03, -2.83710812e-01,
-2.09785660e-01, -8.04465613e-02, -9.28709335e-02, 1.33271162e-01,
-2.98319490e-03, -3.83409786e-02, 3.73239980e-03, 5.62721272e-01,
-3.76827243e-01, 1.12246465e-02, 8.97254741e-02, 2.23749426e-01,
-1.96915673e-02, -5.79503197e-03, 5.49418858e-03, 4.47583119e-04,
-3.18483615e-02, -8.30911287e-02, -7.61494474e-02, -2.49275792e-02,
6.31735805e-03, 7.52935294e-04, 4.67512415e-02, 7.33614438e-02,
1.33769144e-02, 5.94304935e-02, 2.21279096e-01, -1.57754229e-02,
1.32743964e-02, -5.59370684e-02, -6.15899652e-02, 1.22190314e-02])]
[1.6950551780425966
array([ 9.70618076e-02, 2.51562296e-01, -7.83367835e-02, -3.63157142e-01,
-1.61072160e-01, -4.78356945e-02, 8.71971484e-04, -3.15918962e-01,
-1.96980823e-01, -7.12550547e-02, -7.65767860e-02, 1.06907237e-01,
1.46825973e-03, 4.35733731e-02, -6.12158912e-03, -5.53328161e-01,
4.38024475e-01, -1.46816857e-02, 4.60525843e-02, -2.98442973e-04,
-8.80213283e-03, -1.87420125e-02, 1.15229475e-02, 3.33738171e-03,
-1.92808827e-01, -6.48786337e-02, -5.95877767e-02, -1.67287584e-02,
1.84004928e-02, 2.01818470e-03, 3.24847395e-02, 6.16299161e-02,
1.05024624e-02, 5.40519350e-02, 1.94579166e-01, -2.08639864e-02,
1.71242120e-02, -4.54845519e-02, -5.43169839e-02, 1.13551002e-02])]
[1.5234427494364413
array([ 0.26786199, 0.19757443, -0.06958678, -0.21343637, -0.0394052 ,
0.03320563, 0.00470479, -0.14910987, 0.06532743, 0.05006372,
0.08945263, -0.23677149, 0.0050435 , -0.04117747, 0.00895127,
0.11809789, 0.15731806, -0.00699062, 0.47596522, -0.31494621,
0.00488991, 0.01433041, -0.0073627 , -0.00362171, 0.46121831,
0.11265528, 0.13107265, 0.06689903, -0.05788206, -0.02069075,
-0.0661716 , -0.12918385, -0.01736481, -0.06087424, -0.30446256,
0.02907219, -0.04685647, 0.03129265, 0.06160531, -0.00760825])]
[1.4010304434964538
array([ 1.39844966e-02, -6.96912692e-03, 8.19949913e-02, 7.85933361e-02,
-2.53381500e-01, -2.24479968e-01, -3.24447271e-02, 4.11385685e-02,
-7.47250318e-02, -1.08795969e-01, -1.49430730e-03, -1.25046390e-01,
-9.22223274e-04, -1.07896271e-03, -1.32045341e-04, 9.40502063e-04,
-1.44562927e-03, -2.09392393e-03, -1.80995517e-03, -5.02262584e-03,
9.08418159e-03, -1.86087240e-03, -4.97860875e-03, 2.75480003e-02,
4.79219791e-03, 3.58313934e-01, 5.93108829e-03, -2.51834772e-01,
5.52262779e-02, 3.29815862e-01, -8.16367179e-02, -2.57184589e-02,
3.87390227e-01, 2.43982019e-01, -4.30443013e-02, 3.56056030e-01,
4.29325792e-01, -2.62231438e-02, -3.44006906e-02, -1.04633325e-02])]
[1.2899985146323911
array([ 1.03299738e-02, -1.96996269e-02, 1.00199951e-01, 6.10120757e-02,
-2.16444353e-01, -2.55760700e-01, 1.43004716e-02, -1.61466416e-03,
-5.06928583e-02, 3.69265971e-02, 2.63222635e-02, -5.58307184e-02,
1.80042160e-03, 6.64656136e-04, 2.74064164e-04, -6.24539105e-04,
-1.68761639e-03, 4.19403666e-03, 3.00195430e-03, 3.91234160e-03,
2.09108618e-03, -3.32142014e-03, 7.53218523e-04, 1.26438493e-03,
-5.77759632e-03, 1.15582467e-01, -4.58029666e-02, -1.38606529e-01,
8.04408823e-02, -1.45422241e-01, 1.22496973e-01, -8.90102095e-03,
-4.86935231e-01, -4.42809484e-01, -7.42635122e-02, 9.73195118e-02,
2.07486129e-01, 8.57797757e-02, -5.32479051e-01, 7.70958848e-02])]
[1.171244239414246
array([ 1.70533910e-02, 1.70641183e-01, 2.78233602e-01, -9.03538458e-02,
2.46907629e-01, -1.34568741e-01, 3.96591037e-02, 4.01840799e-02,
6.07757884e-02, 1.42059801e-01, -1.08024928e-01, 2.10182921e-01,
-3.51725005e-04, -5.00984142e-03, -8.68297556e-04, 4.32336984e-03,
7.86988473e-03, -1.93233227e-03, -9.69415003e-03, -1.91156908e-02,
-4.21003950e-01, 4.53728716e-02, -4.67272912e-01, -2.03700415e-02,
1.44925252e-02, 2.59875604e-01, 1.55858531e-01, 8.03548930e-02,
2.73657968e-01, 2.09205532e-01, 2.36088385e-02, 6.56060614e-02,
-1.91434263e-01, 8.00827629e-02, 7.60496903e-02, 1.17219146e-01,
-1.58277507e-01, 1.05125047e-01, 6.06837829e-02, 4.42692838e-03])]
[1.1567595127146777
array([ 0.29438723, 0.16515453, -0.06501401, -0.20420622, 0.01205647,
0.04682095, 0.00373449, -0.18212218, 0.05995136, 0.04935084,
0.10314375, -0.22227462, -0.00716427, 0.07675688, 0.011355 ,
-0.16557134, -0.2727719 , 0.01464596, -0.62444531, 0.1733501 ,
0.02215928, 0.02902577, 0.00475595, -0.00254554, -0.04272918,
0.12174919, 0.13253231, 0.05263456, 0.00205457, -0.01844988,
-0.10333117, -0.12514191, -0.02539228, -0.06383591, -0.35826926,
0.03499142, -0.03167292, 0.06397034, 0.07622336, -0.01471442])]
[0.015923800698430766
array([ 7.88375588e-03, -8.89152843e-02, -9.02136645e-03, -7.60773013e-02,
8.41005440e-02, 7.90147410e-02, -2.69127724e-02, 1.82255112e-01,
-3.81339071e-01, -2.43006744e-01, -2.31392949e-03, -2.03664311e-01,
1.47417672e-03, -8.11041944e-04, -4.18927604e-04, -3.86956422e-04,
4.12474900e-04, 1.89744263e-03, 1.47835855e-03, -5.54056496e-03,
-1.22623513e-03, 1.38622759e-02, 3.74206761e-03, -3.86287605e-04,
-8.46860697e-03, 3.34875930e-01, -1.62834008e-01, -1.94342031e-01,
1.26724738e-01, 1.01464108e-01, 9.01957016e-02, -1.55606618e-01,
6.25513114e-02, 1.46431789e-01, -9.02199535e-02, -3.63745557e-01,
-4.50507023e-01, -2.42908496e-02, -2.94419917e-01, 3.82904036e-02])]
[0.01801557257875873
array([ 5.61465882e-02, 3.69529649e-01, -1.80449191e-02, 3.54374726e-01,
5.09114073e-02, 5.38002962e-02, 1.25727634e-01, -4.60636103e-03,
-1.35399667e-01, -5.48724584e-02, -4.96434682e-03, -3.90334973e-03,
-6.95984792e-01, -7.53639947e-02, -8.85582658e-03, -3.50921946e-03,
-4.71082379e-04, 2.05253605e-03, 1.32589714e-02, -2.17220267e-02,
1.85588253e-02, 3.58891154e-01, 3.93052721e-02, 4.25891061e-03,
-2.91575228e-02, -7.87442905e-02, 6.43100479e-02, 4.01819945e-02,
8.03491264e-02, -5.06091823e-02, -1.55072765e-01, -4.25784863e-02,
-1.13770442e-02, 8.09745500e-02, 2.28132316e-02, -4.53343763e-02,
5.34018758e-02, 4.49446929e-03, -1.01465136e-01, 7.31571614e-03])]
[0.027685132124770848
array([ 4.57129553e-02, -9.20570613e-02, 3.15062202e-02, -2.81089736e-02,
-9.32442456e-02, -1.25787047e-01, 2.48013753e-02, 2.20219571e-01,
-3.47946791e-01, -2.09414945e-01, -4.21179781e-02, 8.81293089e-02,
3.80604393e-03, -1.66949059e-03, 7.85113668e-04, -3.30085830e-03,
4.83606952e-03, -2.13953498e-05, -3.76306862e-03, -1.19307676e-02,
-1.24682429e-03, -1.61835403e-03, 1.36934070e-02, 8.64437253e-03,
-1.71021222e-02, -2.15496350e-02, 1.29878137e-01, 5.01561926e-02,
2.28624807e-02, -1.81061117e-01, -5.82460218e-02, -6.81181624e-02,
-3.56543822e-01, 1.00629850e-01, -1.82572191e-01, 2.35079646e-01,
-2.32253460e-02, -5.83305528e-01, 3.33081836e-01, 5.87666235e-03])]
[0.032380102973250065
array([-4.36279718e-02, 5.11072405e-02, -2.28133526e-01, -4.06990992e-02,
1.76556272e-01, -3.98259729e-02, 2.99088259e-02, 2.41803949e-02,
5.84552667e-02, 2.16106022e-01, -1.57286324e-01, 3.47677587e-01,
-2.79585450e-04, -9.98366209e-04, -6.10304695e-03, 3.07418608e-03,
4.62186480e-03, 1.54488009e-02, 1.41103077e-02, 2.31834480e-02,
-3.92684225e-02, -2.43192992e-03, 8.10403222e-02, 3.15362340e-03,
-3.08165062e-02, 1.82555455e-01, 1.87925697e-01, 2.84567488e-02,
-1.16091851e-01, 4.55312814e-02, 3.27240909e-01, -3.71520016e-01,
2.42374929e-02, 9.24558401e-02, -1.73942414e-01, -3.67833174e-01,
3.79615564e-01, -2.08838889e-01, -9.38072976e-02, 1.89263202e-02])]
[0.056397126917951394
array([ 1.21933935e-02, 5.04431468e-02, 3.40175602e-01, -4.95546222e-02,
-1.00274907e-03, 4.31578401e-02, -1.12221384e-02, -5.01768245e-03,
-1.34715321e-02, 5.07182331e-02, -1.12045463e-02, 4.07586840e-02,
4.32034191e-04, -5.55700324e-04, -1.33766820e-03, 2.26888613e-03,
3.70878256e-03, 1.97050272e-02, 7.27271946e-03, -4.74000311e-03,
-3.20003026e-02, -7.30741461e-03, -1.36735585e-03, -4.20551622e-03,
2.06997575e-02, 5.61456116e-02, -4.09174306e-02, -5.58540804e-02,
7.26818821e-02, -1.97306169e-01, -6.03279820e-02, 6.58917482e-01,
1.57133133e-01, 8.66183113e-03, -3.51254104e-01, -3.92164164e-01,
2.11277929e-01, -1.83848957e-01, -1.47930204e-02, -2.61451331e-04])]
[0.0663065027644859
array([-1.21632859e-01, 5.06538671e-02, 1.03694283e-03, 2.61246091e-04,
-6.82917133e-02, -8.27839357e-02, -3.00352377e-02, 4.99148047e-02,
-2.14473789e-01, -1.12410471e-01, -1.88431263e-01, 4.56140122e-01,
-8.82643983e-04, -5.23641369e-03, -1.53827110e-03, 7.10211831e-04,
2.35238746e-02, -1.14755613e-03, 1.75373806e-02, 1.42721285e-02,
3.19709306e-03, 1.40402251e-03, 7.39875764e-03, -4.94738254e-03,
2.95146607e-02, -1.62197879e-01, -3.26250014e-01, 9.14901544e-03,
-3.02252446e-03, 7.91142812e-02, -9.91116357e-02, -1.21434291e-01,
9.53808217e-02, -1.44552531e-01, -5.23463116e-01, 9.68762786e-02,
-6.27084710e-02, 4.07222069e-01, 1.27886815e-01, -1.69060867e-02])]
[0.13819156685843903
array([ 0.36058836, -0.12131488, 0.01691596, 0.08916666, 0.08455848,
0.03611901, -0.00572279, -0.03674059, 0.07275661, 0.03220334,
0.0982922 , -0.08220649, 0.01714248, -0.14962649, -0.0243978 ,
0.21745937, 0.25305788, -0.01370445, 0.2956968 , 0.29923102,
-0.04478629, -0.06278296, 0.03072248, 0.00875242, -0.65204805,
0.06277768, 0.04087322, 0.04150354, 0.05525942, 0.00683549,
-0.08651473, -0.06183858, -0.01514163, -0.03133145, -0.1950223 ,
0.01266554, -0.00264655, 0.0763352 , 0.05683048, -0.01789496])]
[0.14597185537749427
array([ 7.77218184e-03, 2.64977453e-02, 1.11099732e-01, -4.00777777e-02,
1.45976508e-01, -1.87585137e-01, 2.24787818e-02, 4.01754609e-02,
-1.63259261e-01, 2.45973425e-01, -5.44083698e-03, -2.77695653e-02,
-6.54655255e-04, -3.29799325e-04, -6.74503776e-04, 2.45867048e-04,
8.28331898e-04, 1.60703731e-02, 4.10151977e-03, 2.12129355e-03,
2.63415026e-02, 1.26782965e-03, 8.98590610e-02, -1.41135490e-03,
7.03361285e-03, 1.51045710e-01, -6.77125043e-02, 7.33935769e-02,
2.84031004e-01, -6.34205681e-01, 1.62706290e-01, -1.77317376e-01,
4.21632148e-01, -1.27275586e-01, 1.26969899e-01, 1.83291670e-01,
-4.96581016e-02, 4.80017454e-02, 8.52274144e-02, 1.71995451e-02])]
[0.19769289215763097
array([ 1.79052295e-02, 8.09236474e-02, 1.41785788e-03, 3.97411846e-02,
6.45368992e-02, -7.16434693e-02, -6.50806967e-01, 4.19046340e-02,
-5.74967312e-02, -4.04529615e-02, -1.51224126e-02, 5.29466365e-03,
-5.78849065e-04, -1.27726267e-05, -2.04688013e-04, 2.39689560e-04,
8.25378167e-05, 7.15403151e-04, -2.60173763e-03, 2.78818087e-03,
1.49424973e-03, -5.75494791e-03, -2.21602695e-02, 7.02158852e-01,
8.46397848e-03, -1.00783967e-01, 1.96920625e-01, 2.06562276e-02,
2.19008518e-02, -2.51190394e-03, -1.80458524e-02, 2.46630583e-03,
3.59864553e-02, -5.16464265e-02, 1.40382718e-02, -3.08785057e-02,
-1.30215154e-02, 1.82904927e-02, -4.79851938e-02, 2.66580875e-03])]
[0.23310516335588086
array([ 0.05667657, 0.37197137, -0.01872887, 0.35544532, 0.0505963 ,
0.05488679, 0.12149119, -0.00412505, -0.13234608, -0.05120253,
-0.00424143, -0.00162313, 0.70922981, 0.08036825, 0.00238319,
0.00661624, -0.00797149, 0.00160694, 0.01355751, -0.01816179,
0.01448042, 0.33561585, 0.03749618, 0.00442814, -0.02520141,
-0.07754483, 0.05589767, 0.0424171 , 0.07576494, -0.05026206,
-0.1491725 , -0.04075642, -0.00880725, 0.08602141, 0.02357009,
-0.04176006, 0.05279451, 0.00677865, -0.10220961, 0.00693295])]
[0.28518739487368533
array([ 1.76988904e-02, -1.02763810e-02, 3.63063983e-01, 7.69974974e-05,
-2.52333403e-01, 3.84020083e-01, -5.87927539e-02, 6.10311185e-03,
-4.20430353e-02, 3.91012066e-02, 1.16617157e-02, -6.68423120e-03,
-1.60375970e-03, -4.13432360e-03, -3.82804429e-03, -4.08486771e-03,
-4.91729557e-03, 7.26940833e-02, -4.26790893e-02, -4.25125666e-02,
-6.47127692e-01, -1.46353750e-02, 3.86635567e-01, 1.43951980e-02,
1.58576850e-02, -7.93280463e-02, -1.19213238e-02, -1.40127026e-02,
-9.70412798e-02, -2.00005440e-02, 3.10147441e-02, -2.22592660e-01,
2.53531032e-02, -8.35097614e-03, 3.90483717e-02, 2.45315068e-02,
3.57273737e-02, -9.25581592e-03, -2.35937930e-02, 3.56785448e-03])]
[0.33683817261388976
array([ 0.05880457, 0.35585093, -0.01537906, 0.34027061, 0.01735832,
0.00386342, 0.09481831, 0.01581351, -0.12817496, -0.02981531,
-0.01619229, -0.03462871, -0.01379719, -0.00676081, 0.00604379,
-0.00491994, 0.01312887, -0.00104754, -0.03969831, 0.05495147,
-0.02672271, -0.83470574, -0.06914282, -0.01305555, 0.07737263,
-0.01860564, 0.03597715, 0.02659956, -0.06874513, -0.03234697,
-0.00963793, -0.00674172, 0.01135906, 0.02916994, 0.01741128,
-0.0306962 , -0.02052855, 0.001784 , -0.03107187, 0.01517342])]
[0.36132561613724073
array([-5.26431762e-03, 8.33632389e-03, 1.81680679e-01, -1.08129349e-01,
2.22527130e-01, -2.47971668e-01, 6.36546346e-02, 9.39178689e-02,
-2.97068539e-01, 3.96241478e-01, 1.14777418e-02, -1.07859587e-01,
6.03248431e-04, 1.21446977e-03, 5.56569573e-04, -2.11260444e-03,
2.92712213e-03, 1.41756687e-01, 9.93932745e-03, 8.03390467e-03,
-1.28733542e-02, 6.01626440e-02, -7.39706916e-02, 1.17438498e-02,
-6.06575551e-02, -8.83724771e-02, -2.06545593e-03, -1.95188900e-01,
-6.42175931e-01, 2.26000856e-02, -2.71666861e-01, -3.26495405e-02,
1.33553722e-02, 5.61198602e-03, 5.26688597e-02, -3.08027526e-03,
-3.83091953e-02, 2.08105207e-02, -4.84826415e-02, 5.02722406e-03])]
[1.0700543796589408
array([ 9.35438120e-02, 2.64506649e-01, 5.50453658e-02, 2.16286799e-01,
-5.24706066e-02, -3.66252023e-02, -3.84498823e-02, -3.02748710e-02,
6.96002435e-02, -3.52862552e-02, -2.82213026e-03, -5.57226299e-02,
-1.75766433e-03, -4.27167232e-04, 2.24813557e-03, -1.92120144e-03,
-6.45670905e-03, -4.94442113e-03, -1.37387682e-03, -1.31997384e-02,
2.61063369e-02, 1.63362854e-01, 2.43021186e-02, 2.73509038e-02,
-8.21244275e-02, 1.22792224e-01, -1.31338437e-01, -2.05832165e-01,
-3.12522889e-01, 8.87242045e-02, 6.62540520e-01, 1.70150706e-01,
2.82210819e-03, -1.59427360e-01, -4.08810454e-02, 1.06252149e-01,
-2.09488473e-01, -4.65597854e-02, 2.95504694e-01, -1.29324670e-02])]
[1.0452402798214713
array([ 1.41584012e-02, 2.11257942e-02, 3.93840343e-01, -1.57536813e-02,
-2.06075640e-01, 3.76184333e-01, -5.57929159e-02, -7.00308132e-03,
-2.86727207e-02, 9.00819955e-02, -1.58969146e-02, 6.35821387e-02,
5.29266924e-04, 1.18952611e-03, 7.34660398e-04, 2.88078019e-04,
1.64152334e-02, 4.88310608e-01, 2.48013896e-02, 2.87668439e-02,
4.63910846e-01, -4.08392271e-03, -3.39830907e-01, -1.39040406e-02,
-2.39157327e-02, -2.53530052e-02, 2.51387024e-02, 3.47223150e-02,
5.25570765e-02, 2.64830522e-02, 9.44824707e-02, -2.31009981e-01,
-1.14370280e-02, 1.76871392e-02, 1.86654510e-02, -3.33866585e-03,
4.70307317e-02, -2.64913482e-02, -2.54088162e-03, 4.12955401e-03])]
[0.48444007027242614
array([ 0.3959035 , -0.17361409, 0.02238617, 0.11113603, 0.03765096,
-0.01858093, -0.00100524, 0.03051075, -0.01546241, -0.00349698,
-0.04289171, 0.10687158, -0.04266696, 0.37130426, 0.03651231,
-0.41086635, -0.51416218, 0.01326739, 0.40791678, 0.16873406,
-0.03062236, -0.01030892, -0.00515652, -0.00061111, 0.06193322,
-0.03948067, -0.05519555, -0.00097453, 0.00496999, 0.02032697,
0.01235825, 0.01699024, 0.01740467, 0.01445219, 0.05260305,
-0.01459554, 0.01392229, 0.02133044, -0.01696112, 0.0007924 ])]
[0.5206389662874614
array([ 0.00604016, -0.02970696, -0.07725239, 0.07071466, -0.32133921,
0.30806685, -0.07893353, 0.06354193, -0.23447709, 0.53297637,
-0.05780595, 0.11413801, -0.00108934, 0.0018824 , 0.00180329,
0.00066802, -0.0169731 , -0.53948761, 0.00184527, 0.00711211,
0.18443004, 0.00626668, 0.01418978, 0.00112605, -0.00729624,
0.20401514, 0.09811241, -0.00528525, 0.02935354, 0.05397268,
-0.05528054, 0.1056786 , -0.08760288, 0.03636192, 0.02871916,
0.03912704, -0.10578212, 0.06433838, 0.05102008, 0.00135883])]
[0.9804400382825518
array([ 0.36252543, -0.17684103, 0.02286329, 0.10648253, 0.02606297,
-0.01868932, 0.00592638, 0.03758524, -0.02757984, -0.00862505,
-0.09583143, 0.10276574, 0.00735865, -0.06804231, -0.02402141,
0.09684626, 0.39384167, -0.01155136, -0.17646215, 0.5440585 ,
-0.00950297, 0.10133207, -0.01142229, -0.00690536, 0.51928939,
-0.0570475 , -0.04640219, -0.02926741, -0.0352192 , 0.01165272,
0.04973226, 0.03378096, 0.02330753, 0.01914508, 0.10472584,
-0.00953171, 0.00871523, -0.01036465, -0.04120995, -0.00770785])]
[0.603766343550455
array([ 2.15788781e-02, 9.04359510e-02, 2.04854332e-03, 4.51881114e-02,
6.47143551e-02, -7.27710065e-02, -6.51363563e-01, 4.59063559e-02,
-5.99169828e-02, -4.35350486e-02, -1.23952485e-02, -2.19258661e-03,
-1.52617886e-04, -1.70354639e-04, 9.35225257e-05, 2.86930242e-05,
1.18465687e-03, -2.08703827e-04, 3.12288961e-03, 3.98169082e-04,
3.04264926e-03, 1.42682855e-02, 3.02841628e-02, -7.09174022e-01,
-1.18617692e-02, -7.44739048e-02, 1.77235796e-01, -7.47377263e-03,
-3.91816279e-03, 1.30078504e-02, -1.35722936e-02, 3.62841429e-03,
3.99113739e-02, -5.32413032e-02, 1.85399742e-02, -4.29022298e-03,
2.51866879e-03, -1.48145796e-03, -3.73513386e-02, -6.06148026e-04])]
[0.6282774649685522
array([-2.40567986e-03, -3.54464814e-03, 4.13215604e-02, -3.45261692e-02,
9.23497156e-02, -1.33820247e-01, 3.77004036e-02, 4.92645544e-02,
-2.48166939e-01, 3.17221475e-01, 9.50783476e-02, -3.41116933e-01,
9.31969687e-06, -8.92146463e-04, -1.18226287e-03, 1.09330128e-03,
7.26919489e-04, -2.70607486e-02, -3.36508435e-03, -9.69103983e-04,
-1.47164077e-02, -2.00307000e-02, 5.19746368e-02, -5.83314636e-03,
2.61788200e-02, -4.74306128e-01, -1.57310484e-01, 1.14398501e-01,
3.74371769e-01, 3.93718018e-01, 2.67675005e-01, -2.80470419e-02,
-1.20233282e-02, -8.46638791e-03, -9.38523393e-02, -6.04365360e-02,
1.41487166e-01, -7.67952551e-02, 7.30399832e-02, 7.80673708e-03])]
[0.9204386841094124
array([-1.49916129e-03, -4.19463500e-02, -8.12283430e-02, -1.28559807e-01,
2.90010238e-01, 3.29780961e-01, 4.15774626e-02, 1.29468154e-01,
-2.43646324e-01, -1.35328695e-01, -4.33603374e-02, -4.13964307e-02,
-2.31722073e-03, -7.98686200e-04, 1.23552927e-04, -1.13781533e-03,
1.25007815e-03, -1.75416721e-03, 4.47965586e-03, -6.18840871e-03,
6.89450293e-03, 1.08445345e-02, -6.18447849e-03, 1.81113718e-03,
-2.71641017e-02, 4.79788675e-02, 7.04330910e-02, 4.60305073e-01,
-2.11260091e-01, 3.23651977e-02, 2.31043283e-01, 2.52583965e-01,
8.01312687e-02, 1.31860639e-02, -8.72393021e-02, 3.93209315e-01,
1.38685394e-01, 6.47024715e-02, -3.23878431e-01, 4.83368697e-02])]
[0.8913933001321473
array([ 4.00001312e-01, -1.58821833e-01, 1.21777014e-02, 6.87160653e-02,
3.06720830e-02, -3.38949431e-02, 4.30854870e-04, -4.74655601e-02,
-6.36174188e-02, -1.21350773e-02, -7.89986281e-02, 1.51637013e-01,
8.05075911e-02, -7.26206710e-01, -4.98501921e-04, -1.25277755e-01,
-2.02188614e-01, 6.19371867e-03, -1.19231601e-01, -3.74375299e-01,
2.99133486e-02, -2.25152438e-02, -9.66494042e-03, -1.17402896e-03,
-2.98471685e-03, -6.01568552e-02, -6.76052550e-02, -1.60528424e-02,
4.33539882e-03, 2.10952776e-02, 2.24457243e-02, 2.93994404e-02,
2.22251212e-02, 2.18291744e-02, 1.05458937e-01, -3.02073040e-02,
2.87791505e-02, 1.53482026e-02, -3.74519931e-02, 5.75460356e-03])]
[0.6950062323909713
array([ 3.93956775e-01, -1.58302226e-01, 1.29753225e-02, 7.06593800e-02,
3.71087925e-02, -3.16226695e-02, 2.30402936e-04, -6.48397545e-02,
-6.65164566e-02, -1.06208129e-02, -4.19086939e-02, 1.55675140e-01,
-5.94184012e-02, 5.32084415e-01, -1.68346310e-03, 3.06373696e-01,
1.96117687e-01, -5.27349591e-04, -2.58617937e-01, -5.05810563e-01,
3.22606453e-02, -3.93005020e-02, -4.99621489e-03, -2.11625892e-04,
-1.05989937e-01, -5.01751051e-02, -6.01136816e-02, -1.29362255e-02,
1.02190119e-02, 2.66221179e-02, 1.47061791e-02, 2.35687116e-02,
2.42764276e-02, 1.41317931e-02, 8.92189956e-02, -2.96647265e-02,
2.74178628e-02, 1.86833759e-02, -2.86275838e-02, 4.98863868e-02])]
[0.7119503633803751
array([ 1.21120912e-02, 1.77088316e-02, 5.19034506e-03, -1.99417137e-02,
1.29675028e-02, -2.41944109e-02, 3.20520879e-03, 2.50264775e-02,
-1.05665336e-01, -7.56615468e-03, 6.39926561e-01, 2.58657493e-01,
-1.98380159e-03, 4.70373977e-03, 6.88961596e-03, 1.20059303e-03,
4.66624114e-03, 4.76288449e-04, -1.34189026e-02, -1.17638596e-02,
-1.67060321e-04, -1.18016618e-02, 1.59119322e-03, 1.12410006e-03,
4.00547698e-02, 2.06629364e-02, 6.72095677e-03, -3.77552255e-03,
1.09710852e-03, 5.99165119e-03, 6.94692136e-02, 8.93391529e-03,
-7.77689197e-03, 3.39968970e-02, 2.03627647e-02, 4.40165541e-03,
4.31698248e-03, 1.14141145e-02, -8.39989495e-02, -7.02599200e-01])]
[0.7411245925725353
array([-1.25135741e-02, 1.34461819e-02, -4.05431239e-03, -4.88293490e-03,
1.56734666e-02, -2.56967585e-03, 4.56246231e-03, -9.99080668e-03,
-6.50247200e-02, -1.81617408e-02, 6.49674323e-01, 2.63344412e-01,
3.23856429e-03, -3.10640077e-02, -1.54714697e-03, -1.59152140e-02,
-1.89911317e-03, -3.31420226e-05, 2.01054997e-03, 3.77907257e-02,
-1.70409326e-03, 6.55050470e-03, 1.51747982e-03, -3.06902940e-04,
4.96714803e-02, 3.12108780e-02, 1.96051464e-02, -6.21383444e-04,
-7.00618003e-03, 7.68358388e-02, -5.82867330e-03, 7.18889099e-03,
6.63723304e-02, -4.94999899e-02, 2.29343083e-02, -1.10126817e-02,
-1.12887758e-02, -1.71615265e-02, 5.22427954e-02, 6.92842371e-01])]
[0.7585049659246732
array([ 3.01353836e-03, 4.93793969e-02, -8.13962633e-03, 1.30043171e-02,
8.17502676e-02, 5.11936838e-03, -2.34656695e-01, -5.19114605e-02,
1.01672294e-01, 1.00472605e-01, 9.63727937e-02, -8.69984157e-02,
-6.62633042e-03, -4.48950505e-04, -1.00382601e-03, 1.28111272e-03,
3.64816426e-03, 2.52247055e-06, -7.43020582e-03, -2.72148167e-03,
-1.18155313e-03, -1.16171999e-02, 6.70175085e-04, 4.53624416e-03,
2.78648945e-02, 7.37123338e-02, -4.86340921e-01, 3.21655299e-02,
-4.83511926e-02, -2.53238092e-01, 6.98657486e-02, -2.01092581e-02,
-3.56676590e-01, 6.22081180e-01, -5.02078403e-02, 5.91062726e-02,
1.60417818e-01, 1.65772317e-01, 2.18710656e-02, 7.64562254e-02])]
[0.8237736771654408
array([-5.83672677e-03, -4.52441818e-02, -4.42584558e-01, 9.64364929e-02,
-1.38563448e-01, -1.41991345e-02, -3.06961631e-02, 3.84442358e-02,
-1.07540238e-01, 2.78291886e-01, -3.02666334e-02, 4.47811921e-02,
-2.06203610e-05, -4.15621590e-03, -2.61928743e-03, 2.44446147e-05,
2.19668080e-02, 6.64909123e-01, -1.44705839e-03, -8.86425716e-03,
-1.26407707e-01, -3.79352310e-03, 2.18112308e-01, 5.77360767e-03,
1.88321176e-02, 1.80727391e-01, 5.23767462e-02, 1.73268720e-02,
1.36209159e-01, 5.67161676e-02, -5.22855274e-02, 2.81018232e-01,
-7.62298981e-02, 1.74153661e-02, 3.54461362e-04, 4.80355190e-02,
-1.23284930e-01, 7.25857482e-02, 6.51931039e-02, -4.15331318e-03])]
[0.8314746658196924
array([-2.17789492e-02, -7.81660973e-02, 4.51136709e-02, 4.80566632e-02,
-2.01801965e-01, -1.87828236e-01, 8.28465894e-02, -1.01164011e-01,
1.75714736e-01, 1.16404034e-01, -6.67622466e-03, 9.79602839e-02,
-1.08780360e-03, 4.49205267e-05, -1.05642964e-03, -1.36440102e-03,
-3.06691867e-03, -1.04642282e-03, 2.08219206e-03, -2.34396560e-03,
-2.98307017e-03, -3.33317100e-03, -5.09820345e-03, -1.44543136e-02,
-3.35134366e-02, -3.25617229e-01, 3.17967309e-01, -8.57407116e-02,
-4.01260623e-03, -1.00445837e-01, 1.83724620e-01, 3.32432146e-02,
1.39891524e-01, 4.11871555e-01, -2.74466760e-01, 1.80968228e-01,
-3.67625648e-01, -5.30892619e-02, -3.76822471e-01, 6.16666580e-02])]]
Finding the Explained Variance which tells us how much information (variance) can be attributed to each of the principal components.
tot = sum(eig_vals)
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)] #reverse is true means arranging in the descending order
var_exp
[12.334104679298799,
9.39769594672268,
8.090129555174402,
6.230727018601921,
4.826041791690482,
4.473789814451616,
4.237624164663041,
3.8085944883207405,
3.5025647186571716,
3.224985799163333,
2.9281010765653464,
2.891889377574219,
2.6751272498294423,
2.613092201969201,
2.451092124934289,
2.3010892272998786,
2.2284760034896025,
2.0786799048344076,
2.059427495806203,
1.8962562483252312,
1.8528054562436804,
1.7798701204436507,
1.7375099307223758,
1.5706885546572265,
1.509410950382265,
1.3015931830329415,
1.2110962372847933,
0.9033111028415473,
0.8420926931109551,
0.7129661686704452,
0.582761013293564,
0.4942306231922846,
0.36492845172313537,
0.3454777936776128,
0.16576571785323976,
0.14099235879805294,
0.08094999418967223,
0.0692126052376035,
0.04503878498406637,
0.039809372288913576]
The above analysis shows that 20 vectors contribute to more than 80% of the variance in the target variable.
Now we run the PCA and safely reduce the no of features/dimensions to 20 to predict the target accurately.
from sklearn.decomposition import PCA
pca = PCA(n_components=20)
principalComponents = pca.fit_transform(x)
principalDataframe = pd.DataFrame(data = principalComponents, columns = ['P1', 'P2', 'P3', 'P4', 'P5', 'P6', 'P7', 'P8', 'P9', 'P10', 'P11', 'P12', 'P13', 'P14', 'P15', 'P16', 'P17', 'P18', 'P19', 'P20'])
#adding y to the data set to visualize the new dataset
newDataframe = pd.concat([principalDataframe, y],axis = 1)
newDataframe.head()
| P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 | P9 | P10 | P11 | P12 | P13 | PC14 | PC15 | PC16 | PC17 | PC18 | PC19 | PC20 | TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 94122.776248 | 52304.458810 | -30146.069153 | 26872.095471 | 26028.013005 | 11370.193814 | -269.376116 | -10172.943546 | -7091.067376 | -2096.361030 | -2135.484860 | 553.538415 | -1396.553955 | 5275.722060 | -438.450880 | -864.471824 | 1003.374012 | 501.458436 | 356.295278 | -762.244892 | 1 |
| 1 | 157570.123734 | -27603.606177 | -35036.664855 | -5093.597179 | 13299.195912 | -28388.882639 | 556.964637 | 3620.467723 | -2675.566481 | 1223.944431 | 3099.313722 | 12.195776 | -1658.227590 | 10205.225005 | 1683.661339 | -1968.930859 | 1566.654714 | 195.948463 | -1699.142697 | -348.785889 | 0 |
| 2 | -47360.102395 | 54833.801953 | -5812.852889 | -25391.217592 | 1704.616795 | -6231.968897 | -14.254537 | 6643.075356 | 3629.756951 | 913.976416 | 1506.121501 | -4635.405325 | -697.143683 | -1272.741348 | 740.285959 | -654.381196 | 631.116803 | -78.029918 | -133.899244 | 77.631763 | 0 |
| 3 | 70278.095896 | -47394.308735 | 9028.833009 | -4039.910399 | 18376.064771 | 819.374059 | 1238.005840 | -2830.001432 | 3895.114161 | 137.757458 | -3240.824605 | 280.092806 | 466.304602 | 1590.897918 | 779.001577 | -234.180274 | -484.885590 | -661.129066 | 1241.387027 | -143.679691 | 0 |
| 4 | 10876.398448 | 300.286964 | -36628.683000 | 33354.702124 | 19651.453155 | -14948.267342 | 1605.295543 | -3749.012785 | 2663.839564 | -770.305451 | 1928.898790 | -1271.611400 | 1713.035802 | -1483.304570 | -357.619905 | -702.305990 | 197.181188 | 147.686558 | -17.656688 | 54.850285 | 0 |
#checking the % of variance in price explained by the 2 components
percent_variance = np.round(pca.explained_variance_ratio_* 100, decimals =2)
columns = ['P1', 'P2', 'P3', 'P4', 'P5', 'P6', 'P7', 'P8', 'P9', 'P10', 'P11', 'P12', 'P13', 'P14', 'P15', 'P16', 'P17', 'P18', 'P19', 'P20']
plt.bar(x= range(1,21), height=percent_variance, tick_label=columns)
plt.ylabel('Percentage of Variance Explained')
plt.xlabel('Principal Component')
plt.title('PCA Scree Plot')
plt.show()
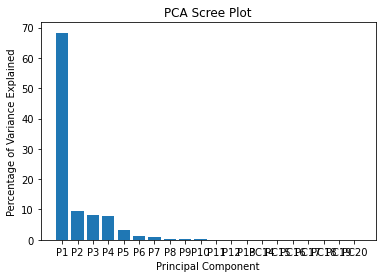
pca.explained_variance_ratio_
array([6.83220228e-01, 9.39943940e-02, 8.32332438e-02, 7.72405338e-02,
3.12079958e-02, 1.20509445e-02, 9.41246896e-03, 3.68363363e-03,
1.82584832e-03, 1.08811937e-03, 8.29263745e-04, 7.59264451e-04,
4.22835482e-04, 3.42936650e-04, 1.80453291e-04, 1.73149542e-04,
1.05528659e-04, 5.27860969e-05, 4.89732876e-05, 4.01763133e-05])
These values show that the first three principal components P1, P2 and P3 explain most of the variance in the target.
Building and visualizing the PCA model further. We will first separate the train and test data and do the prediction.
#Creating a table with the explained variance ratio for the train data set
names_pcas = [f"PCA Component {i}" for i in range(1, 21, 1)]
scree = pd.DataFrame(list(zip(names_pcas, pca_train.explained_variance_ratio_)), columns=["Component", "Explained Variance Ratio"])
print(scree)
Component Explained Variance Ratio
0 PCA Component 1 0.683307
1 PCA Component 2 0.093744
2 PCA Component 3 0.083305
3 PCA Component 4 0.077366
4 PCA Component 5 0.031143
5 PCA Component 6 0.012042
6 PCA Component 7 0.009481
7 PCA Component 8 0.003672
8 PCA Component 9 0.001820
9 PCA Component 10 0.001081
10 PCA Component 11 0.000828
11 PCA Component 12 0.000759
12 PCA Component 13 0.000424
13 PCA Component 14 0.000341
14 PCA Component 15 0.000181
15 PCA Component 16 0.000172
16 PCA Component 17 0.000106
17 PCA Component 18 0.000053
18 PCA Component 19 0.000049
19 PCA Component 20 0.000040
#creating train and test data set
from sklearn.model_selection import train_test_split
X_trn_new, X_tst_new, y_trn_new, y_tst_new = train_test_split(x, y, test_size=0.33, random_state=42)
X_trn_new.shape, X_tst_new.shape, y_trn_new.shape, y_tst_new.shape
((206032, 40), (101479, 40), (206032,), (101479,))
def pca_dec(datas, n):
pca = PCA(n)
princi_components = pca.fit_transform(datas)
return princi_components, pca
#Decomposing the train set:
X_trn_pca, pca_train = pca_dec(X_trn_new, 20)
#Decomposing the test set:
X_tst_pca, pca_test = pca_dec(X_tst_new, 20)
X_trn_df = pd.DataFrame(data = X_trn_pca, columns = ['X_trn_P1', 'X_trn_P2', 'X_trn_P3', 'X_trn_P4', 'X_trn_P5', 'X_trn_P6', 'X_trn_P7', 'X_trn_P8', 'X_trn_P9', 'X_trn_P10', 'X_trn_P11', 'X_trn_P12', 'X_trn_P13', 'X_trn_P14', 'X_trn_P15', 'X_trn_P16', 'X_trn_P17', 'X_trn_P18', 'X_trn_P19', 'X_trn_P20' ])
print(X_trn_df.head())
X_tst_df = pd.DataFrame(data = X_tst_pca, columns = ['X_tst_P1', 'X_tst_P2', 'X_tst_P3', 'X_tst_P4', 'X_tst_P5', 'X_tst_P6', 'X_tst_P7', 'X_tst_P8', 'X_tst_P9', 'X_tst_P10', 'X_tst_P11', 'X_tst_P12', 'X_tst_P13', 'X_tst_P14', 'X_tst_P15', 'X_tst_P16', 'X_tst_P17', 'X_tst_P18', 'X_tst_P19', 'X_tst_P20'])
print(X_tst_df.head())
X_trn_P1 X_trn_P2 X_trn_P3 X_trn_P4 X_trn_P5 \
0 105822.592175 5360.854523 33453.672910 20035.097954 -31296.331953
1 96460.546315 12071.931666 -34475.321799 -121.161213 7732.237596
2 -62574.121014 43683.663525 8246.417644 -53095.357159 11672.119355
3 7006.281321 -12845.096354 -34651.227360 -27794.866288 12116.180104
4 -39374.613681 14853.713250 -20222.355023 50216.232659 -29884.214134
X_trn_P6 X_trn_P7 X_trn_P8 X_trn_P9 X_trn_P10 X_trn_P11 \
0 2401.760554 -28.570046 -4106.561753 850.345134 -222.779685 223.857023
1 -2388.134448 -8.255468 3225.309669 3839.128890 -1221.011505 2098.792975
2 3004.977108 245.234221 -1195.384550 -4312.201212 -1553.452321 2334.307319
3 -7733.065872 1190.475939 908.174550 2199.326517 -1693.199448 1131.984825
4 6284.471008 2188.342028 -4767.137934 3672.663817 -851.879374 5160.198817
X_trn_P12 X_trn_P13 X_trn_P14 X_trn_P15 X_trn_P16 \
0 1812.933939 2415.931313 -1532.208761 1821.192651 -1274.183396
1 3999.341263 6696.850844 -1124.442442 -1401.173422 -2299.379534
2 290.791729 -1032.861097 1557.730517 1282.159270 -1410.883241
3 1218.973683 5324.745292 -1096.829676 -185.856836 -1357.965791
4 -3414.312777 -681.409370 -1195.465967 -385.375696 319.163287
X_trn_P17 X_trn_P18 X_trn_P19 X_trn_P20
0 127.896308 775.746554 -115.823486 63.355865
1 -17.742192 -59.718423 -906.277437 -744.020658
2 -840.661095 122.964251 1056.444823 525.996693
3 1608.005036 -780.774445 1127.472652 84.645813
4 68.039922 -395.309458 -21.190945 125.579686
X_tst_P1 X_tst_P2 X_tst_P3 X_tst_P4 X_tst_P5 \
0 -125985.183152 -17965.925839 27022.436155 -9729.490681 -6462.427122
1 -6032.883572 -12945.609001 -35912.390658 22121.881649 21532.332631
2 8151.048617 -60206.766517 15513.915946 23710.830944 13330.890651
3 -31818.979330 5987.036009 -35069.926826 -36415.018456 7353.965914
4 143813.387120 -30415.880492 27665.670653 11157.214153 9273.871383
X_tst_P6 X_tst_P7 X_tst_P8 X_tst_P9 X_tst_P10 \
0 -1397.924860 20956.238339 14670.476958 -2570.571807 1619.937085
1 -19395.166504 -2146.890618 -4210.249221 -3763.855803 -1798.771859
2 4589.362048 -2379.698205 1409.179208 271.572593 -428.781651
3 10628.604764 -877.988262 2954.279060 6252.337644 -1114.463245
4 4366.996338 -421.539270 2789.836192 5019.328055 451.757399
X_tst_P11 X_tst_P12 X_tst_P13 X_tst_P14 X_tst_P15 \
0 -3963.000107 3592.095002 -1776.119801 -2089.757772 -1478.619709
1 -3130.319663 4140.213814 -1126.697624 -1924.467100 -1373.987051
2 -3248.917688 984.864655 -1288.388438 -1819.730057 1550.095544
3 3726.723856 1229.230450 4885.162554 -909.461643 -773.024935
4 869.264510 -3477.538227 -335.227236 -1382.854561 3044.427856
X_tst_P16 X_tst_P17 X_tst_P18 X_tst_P19 X_tst_P20
0 -132.773275 -2180.208533 -1200.597472 2043.291103 -175.564903
1 634.915073 -622.944924 378.949261 -444.092138 -280.961252
2 -970.677582 -816.864618 374.564623 1519.189261 -29.463563
3 -2068.462874 3169.834265 -316.791278 1199.875989 396.155344
4 -448.101537 180.918733 -649.801134 82.016231 -296.373231
#Sorting the values of the first principal component P1 by how large each one is
dfPC1 = pd.DataFrame({'PCA':pca_train.components_[0], 'Variable Names':list(X_trn_new.columns)})
dfPC1 = dfPC1.sort_values('PCA', ascending=False)
#Sorting the absolute values of the first principal component by magnitude
dfPC1_1 = pd.DataFrame(dfPC1)
dfPC1_1['PCA']=dfPC1_1['PCA'].apply(np.absolute)
dfPC1_1 = dfPC1_1.sort_values('PCA', ascending=False)
#print(dfPC1_1['Variable Names'][0:11])
dfPC1.head()
| PCA | Variable Names | |
|---|---|---|
| 1 | 0.697494 | AMT_PAYMENT |
| 2 | 0.695544 | AMT_INSTALMENT |
| 7 | 0.143118 | AMT_ANNUITY_y |
| 6 | 0.053634 | AMT_CREDIT_y |
| 5 | 0.050587 | AMT_APPLICATION |
#Sorting the values of the second principal component P2 by how large each one is
dfPC2 = pd.DataFrame({'PCA':pca_train.components_[1], 'Variable Names':list(X_trn_new.columns)})
dfPC2 = dfPC2.sort_values('PCA', ascending=False)
dfPC2.head()
| PCA | Variable Names | |
|---|---|---|
| 1 | 0.129220 | AMT_PAYMENT |
| 2 | 0.098205 | AMT_INSTALMENT |
| 4 | 0.012231 | DAYS_BIRTH |
| 12 | 0.004680 | DAYS_EMPLOYED |
| 8 | 0.003424 | DAYS_REGISTRATION |
#Sorting the values of the third principal component P3 by how large each one is
dfPC3 = pd.DataFrame({'PCA':pca_train.components_[2], 'Variable Names':list(X_trn_new.columns)})
dfPC3 = dfPC3.sort_values('PCA', ascending=False)
dfPC3.head()
| PCA | Variable Names | |
|---|---|---|
| 3 | 0.783289 | AMT_CREDIT_SUM_DEBT |
| 10 | 0.428582 | AMT_CREDIT_SUM |
| 1 | 0.046137 | AMT_PAYMENT |
| 0 | 0.033620 | EXT_SOURCE_2 |
| 2 | 0.031973 | AMT_INSTALMENT |
#Sorting the values of the fourth principal component P4 by how large each one is
dfPC4 = pd.DataFrame({'PCA':pca_train.components_[3], 'Variable Names':list(X_trn_new.columns)})
dfPC4 = dfPC4.sort_values('PCA', ascending=False)
dfPC4.head()
| PCA | Variable Names | |
|---|---|---|
| 7 | 0.236100 | AMT_ANNUITY_y |
| 3 | 0.164931 | AMT_CREDIT_SUM_DEBT |
| 6 | 0.091056 | AMT_CREDIT_y |
| 11 | 0.083960 | AMT_GOODS_PRICE_y |
| 5 | 0.075451 | AMT_APPLICATION |
# creating a data set to include only the unique components of the four principal components from the above PCA analysis to form the final dataset
finaldf = data[['AMT_ANNUITY_y', 'AMT_APPLICATION','AMT_CREDIT_SUM','AMT_CREDIT_SUM_DEBT', 'AMT_CREDIT_y', 'AMT_GOODS_PRICE_y', 'AMT_INSTALMENT', 'AMT_PAYMENT', 'DAYS_BIRTH', 'EXT_SOURCE_2', 'TARGET']]
finaldf.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AMT_ANNUITY_y 307511 non-null float64
1 AMT_APPLICATION 307511 non-null float64
2 AMT_CREDIT_SUM 307511 non-null float64
3 AMT_CREDIT_SUM_DEBT 307511 non-null float64
4 AMT_CREDIT_y 307511 non-null float64
5 AMT_GOODS_PRICE_y 307511 non-null float64
6 AMT_INSTALMENT 307511 non-null float64
7 AMT_PAYMENT 307511 non-null float64
8 DAYS_BIRTH 307511 non-null int64
9 EXT_SOURCE_2 307511 non-null float64
10 TARGET 307511 non-null int64
dtypes: float64(9), int64(2)
memory usage: 25.8 MB
#Export the file
finaldf.to_csv('lean_homeloan_data.csv')
from google.colab import files
files.download("lean_homeloan_data.csv")
<IPython.core.display.Javascript object>
<IPython.core.display.Javascript object>
from google.colab import drive
drive.mount('/content/grive')
Mounted at /content/grive
# Loading the dataset
data = pd.read_csv('/content/grive/MyDrive/HomeLoanDefault/lean_homeloan_data.csv')
data.drop(['Unnamed: 0'], axis = 1, inplace = True)
data.head()
| AMT_ANNUITY_y | AMT_APPLICATION | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_y | AMT_GOODS_PRICE_y | AMT_INSTALMENT | AMT_PAYMENT | DAYS_BIRTH | EXT_SOURCE_2 | TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9251.775000 | 179055.000000 | 31988.565000 | 0.000000 | 179055.000000 | 179055.000000 | 53093.745000 | 53093.745000 | -9461 | 0.262949 | 1 |
| 1 | 98356.995000 | 900000.000000 | 810000.000000 | 0.000000 | 1035882.000000 | 900000.000000 | 560835.360000 | 560835.360000 | -16765 | 0.622246 | 0 |
| 2 | 5357.250000 | 24282.000000 | 94537.800000 | 0.000000 | 20106.000000 | 24282.000000 | 10573.965000 | 10573.965000 | -19046 | 0.555912 | 0 |
| 3 | 24246.000000 | 675000.000000 | 474764.762905 | 278160.418613 | 675000.000000 | 675000.000000 | 29027.520000 | 29027.520000 | -19005 | 0.650442 | 0 |
| 4 | 16037.640000 | 247500.000000 | 146250.000000 | 0.000000 | 274288.500000 | 247500.000000 | 16037.640000 | 16037.640000 | -19932 | 0.322738 | 0 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AMT_ANNUITY_y 307511 non-null float64
1 AMT_APPLICATION 307511 non-null float64
2 AMT_CREDIT_SUM 307511 non-null float64
3 AMT_CREDIT_SUM_DEBT 307511 non-null float64
4 AMT_CREDIT_y 307511 non-null float64
5 AMT_GOODS_PRICE_y 307511 non-null float64
6 AMT_INSTALMENT 307511 non-null float64
7 AMT_PAYMENT 307511 non-null float64
8 DAYS_BIRTH 307511 non-null int64
9 EXT_SOURCE_2 307511 non-null float64
10 TARGET 307511 non-null int64
dtypes: float64(9), int64(2)
memory usage: 25.8 MB
# checking for the null values in the columns
data.isnull().sum()
AMT_ANNUITY_y 0
AMT_APPLICATION 0
AMT_CREDIT_SUM 0
AMT_CREDIT_SUM_DEBT 0
AMT_CREDIT_y 0
AMT_GOODS_PRICE_y 0
AMT_INSTALMENT 0
AMT_PAYMENT 0
DAYS_BIRTH 0
EXT_SOURCE_2 0
TARGET 0
dtype: int64
# checking to see if there are any negative values
data.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| AMT_ANNUITY_y | 307511.000000 | 16141.841927 | 11990.326619 | 0.000000 | 8962.605000 | 15955.120659 | 16141.841927 | 290358.000000 |
| AMT_APPLICATION | 307511.000000 | 166766.186872 | 277950.474835 | 0.000000 | 0.000000 | 75748.725000 | 166766.186871 | 4050000.000000 |
| AMT_CREDIT_SUM | 307511.000000 | 474764.762905 | 1150545.949468 | 0.000000 | 80145.000000 | 204453.000000 | 474764.762905 | 142290000.000000 |
| AMT_CREDIT_SUM_DEBT | 307511.000000 | 278160.418613 | 860119.763856 | -2167229.340000 | 0.000000 | 127453.500000 | 278160.418613 | 64570243.500000 |
| AMT_CREDIT_y | 307511.000000 | 183979.842982 | 302589.688861 | 0.000000 | 0.000000 | 80955.000000 | 183979.842982 | 4085550.000000 |
| AMT_GOODS_PRICE_y | 307511.000000 | 231192.849295 | 258618.129194 | 0.000000 | 81447.750000 | 227847.279283 | 227847.279283 | 4050000.000000 |
| AMT_INSTALMENT | 307511.000000 | 53862.175118 | 152022.936773 | 0.000000 | 7108.087500 | 15208.965000 | 38285.865000 | 3771487.845000 |
| AMT_PAYMENT | 307511.000000 | 53766.804766 | 152322.322360 | 0.000000 | 6750.000000 | 14935.500000 | 38225.002500 | 3771487.845000 |
| DAYS_BIRTH | 307511.000000 | -16036.995067 | 4363.988632 | -25229.000000 | -19682.000000 | -15750.000000 | -12413.000000 | -7489.000000 |
| EXT_SOURCE_2 | 307511.000000 | 0.514393 | 0.190855 | 0.000000 | 0.392974 | 0.565467 | 0.663422 | 0.855000 |
| TARGET | 307511.000000 | 0.080729 | 0.272419 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
# checking if Target data is balanced
data['TARGET'].value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64
# Dropping any outliers in the data set
# defining a function to drop the outliers
def drop_outliers(df, field_name):
distance = 1.5 * (np.percentile(df[field_name], 75) - np.percentile(df[field_name], 25))
df.drop(df[df[field_name] > distance + np.percentile(df[field_name], 75)].index, inplace=True)
df.drop(df[df[field_name] < np.percentile(df[field_name], 25) - distance].index, inplace=True)
# dropping the outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
# Checking the value counts to see if the Target values are in the same proportion so that we dont drop all the outliers and rows belonging to one class
data['TARGET'].value_counts()
0 173575
1 16213
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
# this exercise is continued till there are no more outliers to be dropped in the box plots and also until there are no more reduction in the target value counts
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 155453
1 14852
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 151759
1 14556
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150775
1 14485
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150448
1 14461
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150317
1 14453
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150261
1 14447
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150249
1 14445
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150232
1 14444
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150224
1 14443
Name: TARGET, dtype: int64
# checking if there are outliers after dropping the previous outliers
drop_outliers(data, 'AMT_ANNUITY_y')
drop_outliers(data, 'AMT_APPLICATION')
drop_outliers(data, 'AMT_CREDIT_SUM')
drop_outliers(data, 'AMT_CREDIT_SUM_DEBT')
drop_outliers(data, 'AMT_CREDIT_y')
drop_outliers(data, 'AMT_GOODS_PRICE_y')
drop_outliers(data, 'AMT_INSTALMENT')
drop_outliers(data, 'AMT_PAYMENT')
drop_outliers(data, 'DAYS_BIRTH')
drop_outliers(data, 'EXT_SOURCE_2')
data['TARGET'].value_counts()
0 150221
1 14443
Name: TARGET, dtype: int64
As the value counts of the target did not change subsequently, we are sure that all the outliers have been dropped.
#Boxplot analysis
figure, ax = plt.subplots(2,5, figsize=(20,10))
plt.suptitle('Boxplot of 10 Selected Features', size = 20)
sns.boxplot(data['AMT_ANNUITY_y'],ax=ax[0,0])
sns.boxplot(data['AMT_APPLICATION'], ax=ax[0,1])
sns.boxplot(data['AMT_CREDIT_SUM'], ax=ax[0,2])
sns.boxplot(data['AMT_CREDIT_SUM_DEBT'], ax=ax[0,3])
sns.boxplot(data['AMT_CREDIT_y'], ax=ax[0,4])
sns.boxplot(data['AMT_GOODS_PRICE_y'], ax=ax[1,0])
sns.boxplot(data['AMT_INSTALMENT'], ax=ax[1,1])
sns.boxplot(data['AMT_PAYMENT'], ax=ax[1,2])
sns.boxplot(data['DAYS_BIRTH'], ax=ax[1,3])
sns.boxplot(data['EXT_SOURCE_2'], ax=ax[1,4])
<matplotlib.axes._subplots.AxesSubplot at 0x7efdce308b90>
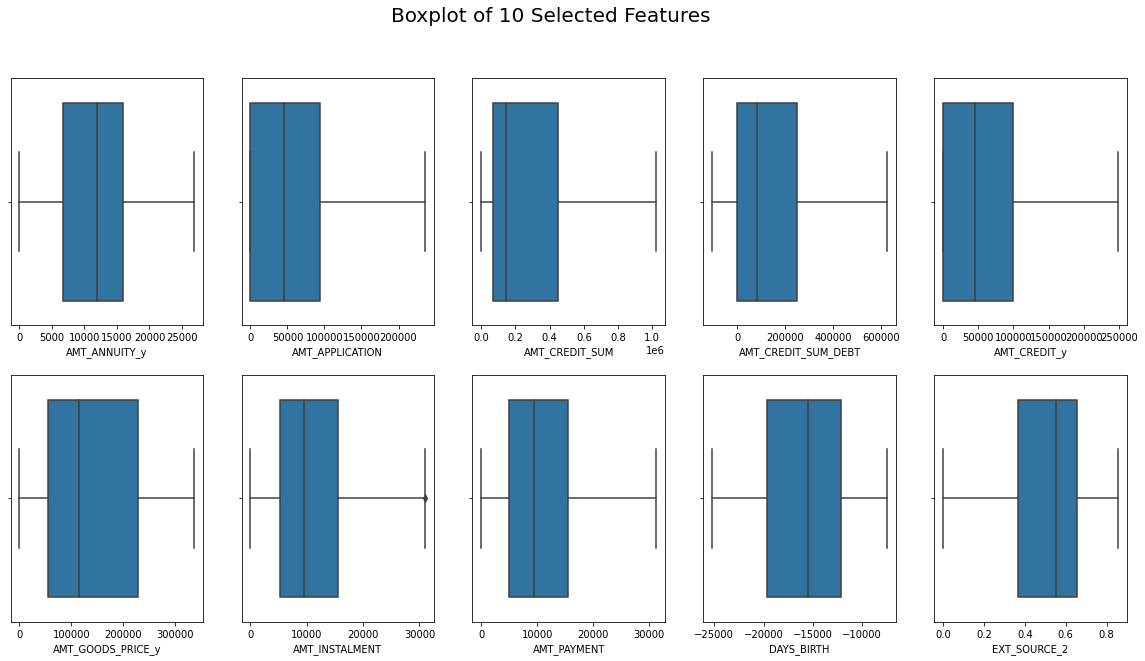
figure, ax = plt.subplots(2,5, figsize=(20,10))
#See the distrubution of the data
plt.suptitle('Distrubution of 10 Selected Features', size = 20)
sns.distplot(data['AMT_ANNUITY_y'],ax=ax[0,0])
sns.distplot(data['AMT_APPLICATION'], ax=ax[0,1])
sns.distplot(data['AMT_CREDIT_SUM'], ax=ax[0,2])
sns.distplot(data['AMT_CREDIT_SUM_DEBT'], ax=ax[0,3])
sns.distplot(data['AMT_CREDIT_y'], ax=ax[0,4])
sns.distplot(data['AMT_GOODS_PRICE_y'], ax=ax[1,0])
sns.distplot(data['AMT_INSTALMENT'], ax=ax[1,1])
sns.distplot(data['AMT_PAYMENT'], ax=ax[1,2])
sns.distplot(data['DAYS_BIRTH'], ax=ax[1,3])
sns.distplot(data['EXT_SOURCE_2'], ax=ax[1,4])
<matplotlib.axes._subplots.AxesSubplot at 0x7fb521aef950>
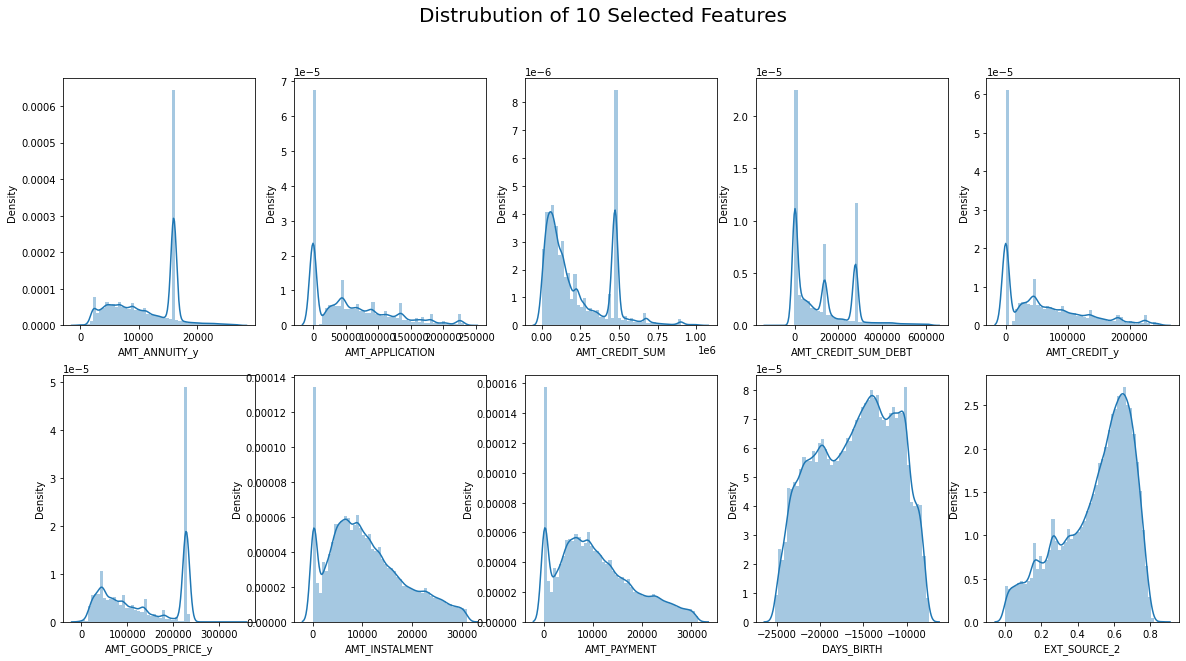
#Heatmap to shows the correlation
plt.figure(figsize=(20,15))
sns.heatmap(data.corr(),cmap='nipy_spectral',annot=True)
plt.title('Heatmap Shows The Relationship (correlation) Between Selected Features',
fontsize=25)
plt.show()
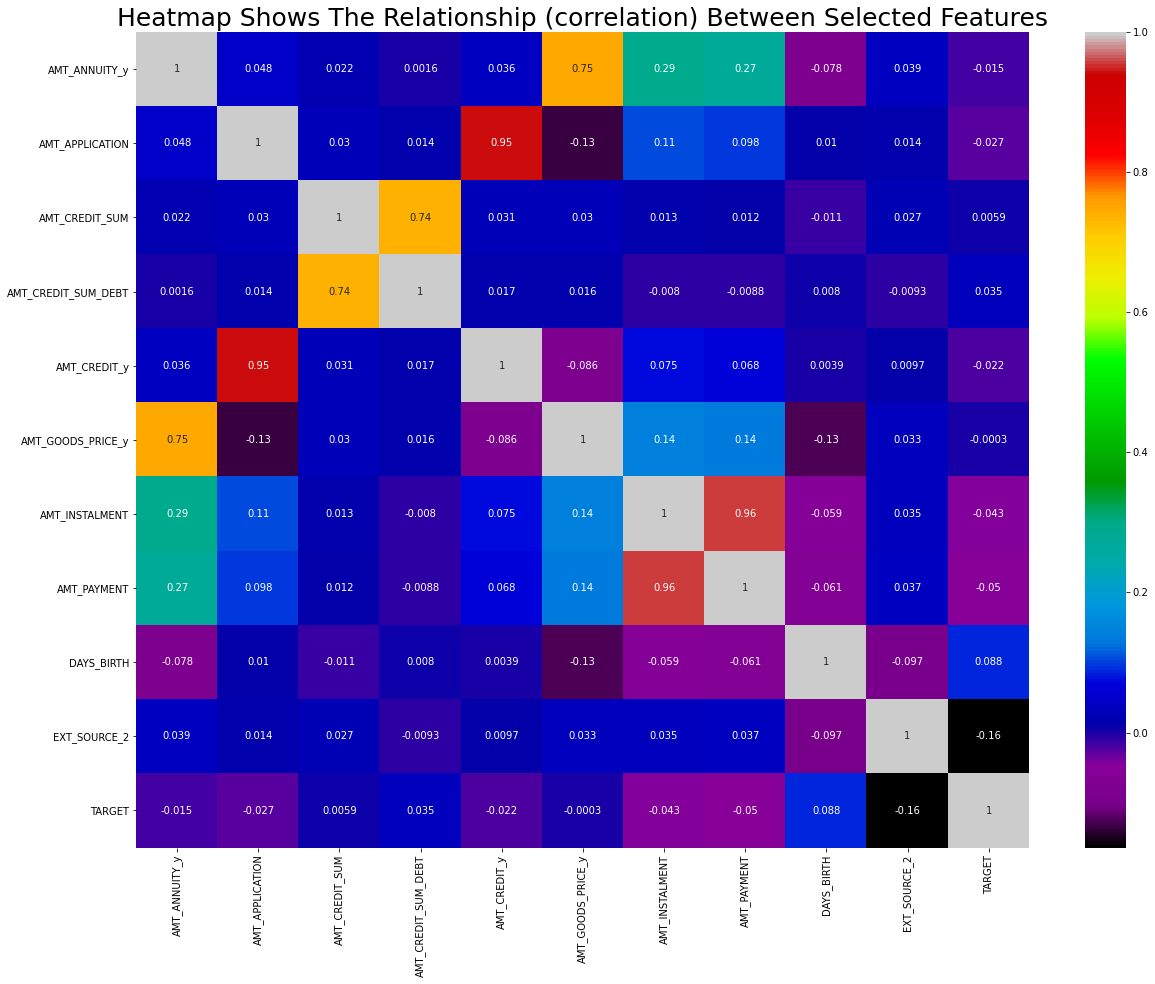
There seems to be poor correlation between the predictor variables and the Target. There seems to be high correlation between some of the predictor variables some of these variables may be dropped for further model improvement, but for now we are running the analysis with all the 10 features so that we dont miss out on any interaction effects between the variables.
#pairplot analysis
sns.pairplot(data, hue = 'TARGET', corner=True, palette='gnuplot')
<seaborn.axisgrid.PairGrid at 0x7efdcdd66a10>
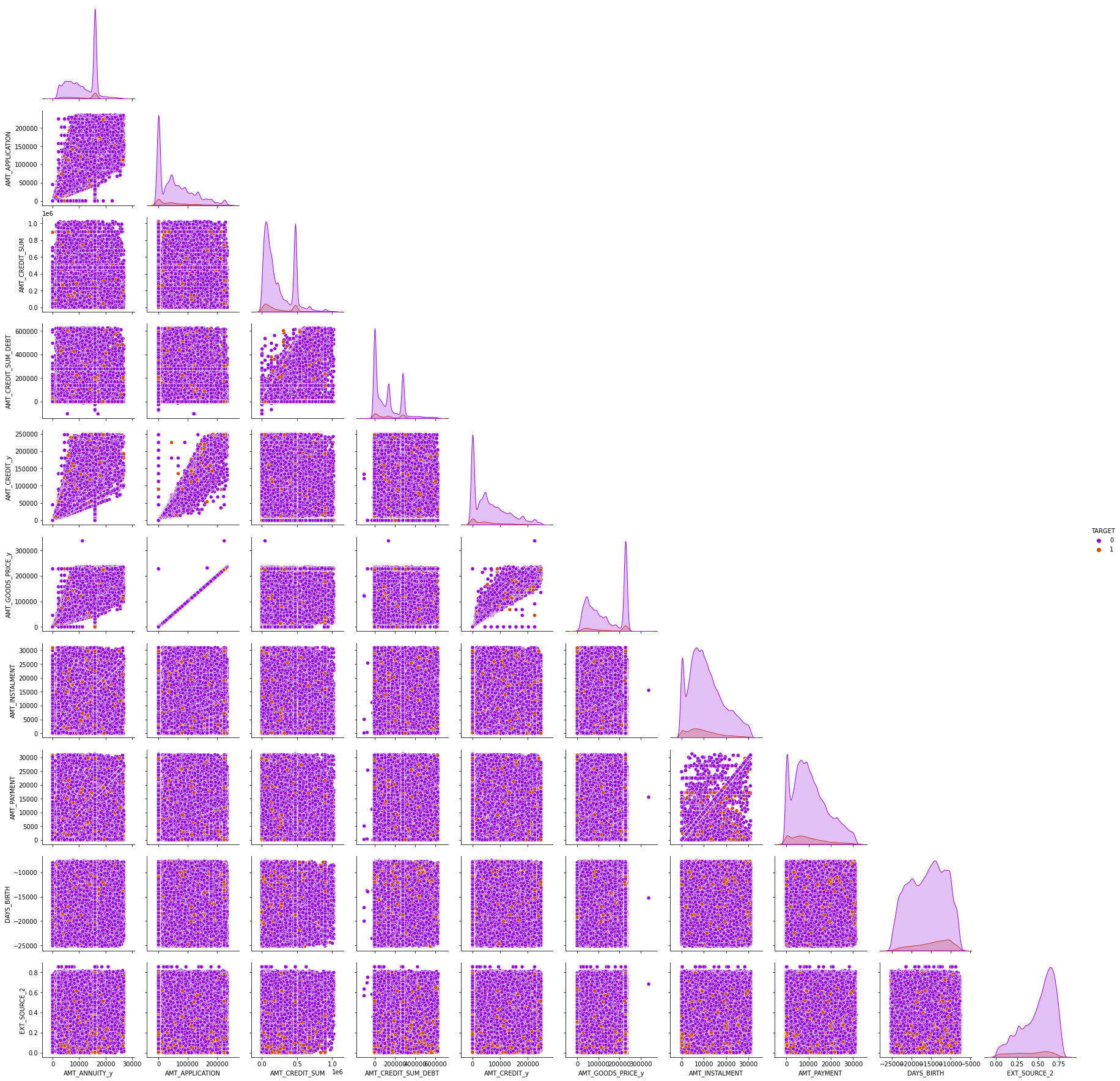
From the pairplot analysis above it is evident that the data is quite complex and the target values are quite mixed up with no clear boundaries for classification. It would be a challenging task for the models to accurately classify the dataset.
# separating the predictor and target variables for further analysis
x = data.drop('TARGET', axis=1)
y = data['TARGET']
print(x.head())
y.head()
AMT_ANNUITY_y AMT_APPLICATION AMT_CREDIT_SUM AMT_CREDIT_SUM_DEBT \
2 5357.250000 24282.000000 94537.800000 0.000000
5 15955.120659 0.000000 267606.000000 240057.000000
6 10418.670000 95841.000000 337500.000000 326628.000000
8 15955.120659 0.000000 145242.000000 0.000000
9 15955.120659 0.000000 474764.762905 278160.418613
AMT_CREDIT_y AMT_GOODS_PRICE_y AMT_INSTALMENT AMT_PAYMENT DAYS_BIRTH \
2 20106.000000 24282.000000 10573.965000 10573.965000 -19046
5 0.000000 227847.279283 17876.115000 17876.115000 -16941
6 88632.000000 95841.000000 10418.670000 10418.670000 -13778
8 0.000000 0.000000 563.355000 563.355000 -20099
9 0.000000 227847.279283 21391.785000 21391.785000 -14469
EXT_SOURCE_2
2 0.555912
5 0.354225
6 0.724000
8 0.205747
9 0.746644
2 0
5 0
6 0
8 0
9 0
Name: TARGET, dtype: int64
# As the data is imbalanced we are using SMOTE to make sure that the value counts for the binary classes is the same
# imbalanced datasets will give imparied prediction results as the model is trained with higher emphasis on one class versus the other
from imblearn.over_sampling import SMOTE #importing smote
oversampling = SMOTE() #initializing SMOTE
x_smote, y_smote = oversampling.fit_resample(x.astype('float'), y)
print(x_smote.shape, y_smote.shape)
(300442, 10) (300442,)
# checking to see if the data set is balanced
a = pd.DataFrame(y_smote)
print(a.value_counts())
1 150221
0 150221
dtype: int64
#feature scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_scaled = sc.fit_transform(x_smote)
X = pd.DataFrame(x_scaled)
# checking X
X.columns = list(x.columns)
X.head()
| AMT_ANNUITY_y | AMT_APPLICATION | AMT_CREDIT_SUM | AMT_CREDIT_SUM_DEBT | AMT_CREDIT_y | AMT_GOODS_PRICE_y | AMT_INSTALMENT | AMT_PAYMENT | DAYS_BIRTH | EXT_SOURCE_2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.116383 | -0.553803 | -0.677117 | -0.976767 | -0.644275 | -1.330380 | 0.030744 | 0.068846 | -0.888268 | 0.531928 |
| 1 | 0.901960 | -0.966198 | 0.189860 | 0.816720 | -0.965876 | 1.196831 | 1.037730 | 1.063330 | -0.388221 | -0.516665 |
| 2 | -0.152446 | 0.661525 | 0.539990 | 1.463499 | 0.451820 | -0.441993 | 0.009328 | 0.047696 | 0.363155 | 1.405833 |
| 3 | 0.901960 | -0.966198 | -0.423117 | -0.976767 | -0.965876 | -1.631835 | -1.349747 | -1.294504 | -1.138410 | -1.288615 |
| 4 | 0.901960 | -0.966198 | 1.227612 | 1.101394 | -0.965876 | 1.196831 | 1.522551 | 1.542131 | 0.199006 | 1.523561 |
# Checking for the skewness and kurtosis for 10 selected features and target
print("Skewness of AMT_ANNUITY_y: %f" %X['AMT_ANNUITY_y'].skew())
print("Kurtosis of AMT_ANNUITY_y: %f" %X['AMT_ANNUITY_y'].kurt())
print("Skewness of AMT_APPLICATION: %f" %X['AMT_APPLICATION'].skew())
print("Kurtosis of AMT_APPLICATION: %f" %X['AMT_APPLICATION'].kurt())
print("Skewness of AMT_CREDIT_SUM: %f" %X['AMT_CREDIT_SUM'].skew())
print("Kurtosis of AMT_CREDIT_SUM: %f" %X['AMT_CREDIT_SUM'].kurt())
print("Skewness of AMT_CREDIT_SUM_DEBT: %f" %X['AMT_CREDIT_SUM_DEBT'].skew())
print("Kurtosis of AMT_CREDIT_SUM_DEBT: %f" %X['AMT_CREDIT_SUM_DEBT'].kurt())
print("Skewness of AMT_CREDIT_y: %f" %X['AMT_CREDIT_y'].skew())
print("Kurtosis of AMT_CREDIT_y: %f" %X['AMT_CREDIT_y'].kurt())
print("Skewness of AMT_GOODS_PRICE_y: %f" %X['AMT_GOODS_PRICE_y'].skew())
print("Kurtosis of AMT_GOODS_PRICE_y: %f" %X['AMT_GOODS_PRICE_y'].kurt())
print("Skewness of AMT_INSTALMENT: %f" %X['AMT_INSTALMENT'].skew())
print("Kurtosis of AMT_INSTALMENT: %f" %X['AMT_INSTALMENT'].kurt())
print("Skewness of AMT_PAYMENT: %f" %X['AMT_PAYMENT'].skew())
print("Kurtosis of AMT_PAYMENT: %f" %X['AMT_PAYMENT'].kurt())
print("Skewness of DAYS_BIRTH: %f" %X['DAYS_BIRTH'].skew())
print("Kurtosis of DAYS_BIRTH: %f" %X['DAYS_BIRTH'].kurt())
print("Skewness of EXT_SOURCE_2: %f" %X['EXT_SOURCE_2'].skew())
print("Kurtosis of EXT_SOURCE_2: %f" %X['EXT_SOURCE_2'].kurt())
Skewness of AMT_ANNUITY_y: -0.134560
Kurtosis of AMT_ANNUITY_y: -1.054236
Skewness of AMT_APPLICATION: 0.977958
Kurtosis of AMT_APPLICATION: 0.185055
Skewness of AMT_CREDIT_SUM: 0.837077
Kurtosis of AMT_CREDIT_SUM: -0.138096
Skewness of AMT_CREDIT_SUM_DEBT: 0.951047
Kurtosis of AMT_CREDIT_SUM_DEBT: 0.427411
Skewness of AMT_CREDIT_y: 0.993466
Kurtosis of AMT_CREDIT_y: 0.156761
Skewness of AMT_GOODS_PRICE_y: 0.088276
Kurtosis of AMT_GOODS_PRICE_y: -1.647991
Skewness of AMT_INSTALMENT: 0.709794
Kurtosis of AMT_INSTALMENT: -0.127812
Skewness of AMT_PAYMENT: 0.713315
Kurtosis of AMT_PAYMENT: -0.149694
Skewness of DAYS_BIRTH: -0.333409
Kurtosis of DAYS_BIRTH: -0.877634
Skewness of EXT_SOURCE_2: -0.384029
Kurtosis of EXT_SOURCE_2: -0.829703
Reference - Skewness between -0.5 and 0.5: data fairly symmetrical. Skewness between -1 and – 0.5 or between 0.5 and 1: data moderately skewed. Skewness is less than -1 or greater than 1: the data are highly skewed. Kurtosis bettween -2 and +2 are considered acceptable.
Teams Remarks: The Skewness and Kurtosis for the predictor and target variables are within the acceptable range.
___
Modeling Strategy → This is a binary classification problem, several models will be used for the comparitive analysis and the best model will be chosen for this project.
Image URL
# Splitting the dataset into train and test data sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_smote, test_size=0.33, random_state=42, stratify=y_smote) #stratify -> it can reduce the variability of sample statistics
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((201296, 10), (99146, 10), (201296,), (99146,))
# importing
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
Model 1: Logistic Regression
# Building the model and predicting
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train,y_train)
LRy_predict= model.predict(X_test) #---> model predictions
# checking the accuracy
LRscore = accuracy_score(y_test,LRy_predict)
print(LRscore)
pd.crosstab(y_test,LRy_predict)
0.6477215419684103
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 32636 | 16937 |
| 1 | 17990 | 31583 |
# As there are many actual defaults that have been predicted as 'no defaults' we are running the below analysis to see if we can change the threshold
# the default threshold is 0.5, by running the below analysis for different threshold we can find the optimal threshold that will improve accuracy
# defining the function
def predict_threshold (model,X_test,thresholds):
#import numpy as np
return np.where(model.predict_proba(X_test)[:,1]>thresholds,1,0)
# checking for different thresholds from 0 to 1.0
for thr in np.arange(0,1.1,0.1):
y_predict = predict_threshold(model,X_test,thr)
print("Threshold :",thr)
print(confusion_matrix(y_test,y_predict))
print("accuracy score for" , thr , "is", accuracy_score(y_test, y_predict))
Threshold : 0.0
[[ 0 49573]
[ 0 49573]]
accuracy score for 0.0 is 0.5
Threshold : 0.1
[[ 13 49560]
[ 0 49573]]
accuracy score for 0.1 is 0.5001311197627741
Threshold : 0.2
[[ 2332 47241]
[ 215 49358]]
accuracy score for 0.2 is 0.5213523490609808
Threshold : 0.30000000000000004
[[11177 38396]
[ 2361 47212]]
accuracy score for 0.30000000000000004 is 0.5889193714320295
Threshold : 0.4
[[22700 26873]
[ 8651 40922]]
accuracy score for 0.4 is 0.6417001190164
Threshold : 0.5
[[32715 16858]
[18133 31440]]
accuracy score for 0.5 is 0.6470760292901377
Threshold : 0.6000000000000001
[[40099 9474]
[28839 20734]]
accuracy score for 0.6000000000000001 is 0.6135698868335586
Threshold : 0.7000000000000001
[[45249 4324]
[39149 10424]]
accuracy score for 0.7000000000000001 is 0.5615254271478426
Threshold : 0.8
[[48480 1093]
[46928 2645]]
accuracy score for 0.8 is 0.5156536824481068
Threshold : 0.9
[[49564 9]
[49555 18]]
accuracy score for 0.9 is 0.500090775220382
Threshold : 1.0
[[49573 0]
[49573 0]]
accuracy score for 1.0 is 0.5
It is evident from the above that the optimal threshold is 0.5 which is the default threshold.
Accuracy score is low as expected as the data is quite complex with no clear distinct boundaries for the two classes. Linear regression models cannot be used for such complex data sets.
Model 2: KNN
from sklearn.neighbors import KNeighborsClassifier
# Model building
# knn = KNeighborsClassifier()
# Search parameters
#param = range(10, 100, 2)
# Sets up GridSearchCV object and stores it in grid variable
#grid = GridSearchCV(knn,{'n_neighbors': param})
# Fits the grid object and gets the best model
#best_knn = grid.fit(X_train,y_train).best_estimator_
# Displays the optimum model
#best_knn
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=10, p=2,
weights='uniform')
# running the optimal model from the above analysis for further prediction
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=10, p=2,
weights='uniform')
# prediction
knn_train_predict = knn.predict(X_train)
knn_test_predict = knn.predict(X_test)
pd.crosstab(y_test,knn_test_predict)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 34083 | 15490 |
| 1 | 9703 | 39870 |
# training and testing accuracy scores
print(accuracy_score(y_train ,knn_train_predict))
KNNscore = accuracy_score(y_test ,knn_test_predict)
KNNscore
0.8000457038391224
0.7458999858794102
Improved score compared to Linear Regression.
Model 3: Decision Tree
from sklearn.tree import DecisionTreeClassifier
# Model building
#Deci_Tree_model = DecisionTreeClassifier()
#parameters = {'max_depth':[3,5,10,20,30],
'random_state': [0,1,2,3,4]
}
#grid = GridSearchCV(Deci_Tree_model,parameters,cv=5,verbose=1)
#grid.fit(X_train,y_train)
Fitting 5 folds for each of 25 candidates, totalling 125 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 125 out of 125 | elapsed: 4.3min finished
GridSearchCV(cv=5, error_score=nan,
estimator=DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort='deprecated',
random_state=None,
splitter='best'),
iid='deprecated', n_jobs=None,
param_grid={'max_depth': [3, 5, 10, 20, 30],
'random_state': [0, 1, 2, 3, 4]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=1)
# printing best parameters from the above grid analysis
#print(grid.best_params_)
{'max_depth': 30, 'random_state': 0}
# Model building with the optimal parameters from the above analysis
Deci_Tree_best_model = DecisionTreeClassifier(max_depth=30, random_state=0)
# Model fitting to the datasets
Deci_Tree_best_model.fit(X_train , y_train)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=30, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=0, splitter='best')
# Training and testing of the model
train_predict = Deci_Tree_best_model.predict(X_train)
test_predict = Deci_Tree_best_model.predict(X_test)
# checking the accuracy scores of the model
Deci_Tree_train_accuracyscore = accuracy_score(y_train ,train_predict)
Deci_Tree_test_accuracyscore = accuracy_score(y_test, test_predict)
print(Deci_Tree_train_accuracyscore, Deci_Tree_test_accuracyscore)
pd.crosstab(y_test,test_predict)
0.9621651697003418 0.7273717547858713
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 33700 | 15873 |
| 1 | 11157 | 38416 |
Model performance is comparable to KNN.
Model 4: Random Forest
from sklearn.ensemble import RandomForestClassifier
# Model building
#RFmodel = RandomForestClassifier() # Hyperparameters tuning
#parameters = {'max_depth':[5,10,15,20,30],
'random_state': [0,1,2,3,4],
'n_estimators':[10,30,50,70,100],
'criterion': ['entropy', 'ginni']
}
#grid = GridSearchCV(RFmodel,parameters,cv=5,verbose=1)
#grid.fit(X_train,y_train)
Fitting 5 folds for each of 250 candidates, totalling 1250 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1250 out of 1250 | elapsed: 451.4min finished
GridSearchCV(cv=5, error_score=nan,
estimator=RandomForestClassifier(bootstrap=True, ccp_alpha=0.0,
class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
max_samples=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=100, n_jobs=None,
oob_score=False,
random_state=None, verbose=0,
warm_start=False),
iid='deprecated', n_jobs=None,
param_grid={'criterion': ['entropy', 'ginni'],
'max_depth': [5, 10, 15, 20, 30],
'n_estimators': [10, 30, 50, 70, 100],
'random_state': [0, 1, 2, 3, 4]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=1)
# Printing the best parameters
#print(grid.best_params_)
#print(grid.best_estimator_)
{'criterion': 'entropy', 'max_depth': 30, 'n_estimators': 100, 'random_state': 3}
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='entropy', max_depth=30, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=3, verbose=0,
warm_start=False)
# Building the best fit model using the parameters from the grid search
RFBmodel = RandomForestClassifier(random_state=3, max_depth= 30 , n_estimators=100)
RFBmodel.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=30, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=3, verbose=0,
warm_start=False)
# Training and testing the model and checking accuracy scores
RFBtrain_predict = RFBmodel.predict(X_train)
RFBtest_predict = RFBmodel.predict(X_test)
print(accuracy_score(y_train ,RFBtrain_predict))
RFscore = accuracy_score(y_test , RFBtest_predict)
RFscore
0.9873072490263095
0.8196296371008411
pd.crosstab(y_test,RFBtest_predict)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 37946 | 11627 |
| 1 | 6256 | 43317 |
Better performance so far.
Model 5: XG Boost
#! pip install xgboost
# import XGBoost
import xgboost as xgb
# Model building
# We did not use hyper parameter tuning for this as the system is taking a very long time to run these models
from xgboost import XGBClassifier
params = {
'objective':'binary:logistic',
'max_depth': 30,
'learning_rate': 1.0,
'n_estimators':100
}
# instantiate the classifier
xgb_clf = XGBClassifier(**params)
# fit the classifier to the training data
xgb_clf.fit(X_train, y_train)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
learning_rate=1.0, max_delta_step=0, max_depth=30,
min_child_weight=1, missing=None, n_estimators=100, n_jobs=1,
nthread=None, objective='binary:logistic', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)
# Prediction using the best fit model and checking accuracy scores
y_pred = xgb_clf.predict(X_test)
XGBscore = accuracy_score(y_test, y_pred)
XGBscore
0.8430496439594134
pd.crosstab(y_test,y_pred)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 40250 | 9323 |
| 1 | 6238 | 43335 |
Good score given the complex nature of the data set.
Model 6: SVM Classification
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from mlxtend.plotting import plot_decision_regions
from sklearn.svm import SVC
# Building the best fit model using the gridsearch methodology
#param_grid = {'C': [0.1, 10, 1000],
'gamma': [1, 0.01, 0.001],
'max_iter': [1000],
'kernel': ['rbf', 'poly']}
#grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3)
# fitting the model for grid search
#grid.fit(X_train, y_train)
Fitting 5 folds for each of 18 candidates, totalling 90 fits
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000 .......................
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000, score=0.518, total= 19.3s
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000 .......................
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 19.3s remaining: 0.0s
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000, score=0.525, total= 19.2s
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000 .......................
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 38.5s remaining: 0.0s
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000, score=0.524, total= 19.2s
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000 .......................
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000, score=0.516, total= 19.3s
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000 .......................
[CV] C=0.1, gamma=1, kernel=rbf, max_iter=1000, score=0.514, total= 19.4s
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000 ......................
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000, score=0.510, total= 8.8s
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000 ......................
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000, score=0.512, total= 8.5s
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000 ......................
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000, score=0.513, total= 8.7s
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000 ......................
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000, score=0.520, total= 8.6s
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000 ......................
[CV] C=0.1, gamma=1, kernel=poly, max_iter=1000, score=0.535, total= 8.7s
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000 ....................
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000, score=0.501, total= 19.1s
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000 ....................
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000, score=0.519, total= 19.2s
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000 ....................
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000, score=0.529, total= 19.3s
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000 ....................
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000, score=0.539, total= 19.2s
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000 ....................
[CV] C=0.1, gamma=0.01, kernel=rbf, max_iter=1000, score=0.524, total= 19.0s
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000 ...................
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000, score=0.505, total= 10.9s
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000 ...................
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000, score=0.504, total= 11.0s
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000 ...................
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000, score=0.502, total= 10.8s
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000 ...................
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000, score=0.501, total= 10.9s
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000 ...................
[CV] C=0.1, gamma=0.01, kernel=poly, max_iter=1000, score=0.501, total= 11.1s
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000 ...................
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000, score=0.508, total= 19.0s
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000 ...................
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000, score=0.514, total= 18.9s
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000 ...................
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000, score=0.515, total= 18.9s
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000 ...................
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000, score=0.520, total= 19.0s
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000 ...................
[CV] C=0.1, gamma=0.001, kernel=rbf, max_iter=1000, score=0.506, total= 18.9s
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000 ..................
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000, score=0.505, total= 10.9s
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000 ..................
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000, score=0.504, total= 11.0s
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000 ..................
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000, score=0.502, total= 11.0s
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000 ..................
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000, score=0.501, total= 11.0s
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000 ..................
[CV] C=0.1, gamma=0.001, kernel=poly, max_iter=1000, score=0.501, total= 11.0s
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000 ........................
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000, score=0.504, total= 18.5s
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000 ........................
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000, score=0.524, total= 18.6s
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000 ........................
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000, score=0.514, total= 18.6s
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000 ........................
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000, score=0.522, total= 18.6s
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000 ........................
[CV] C=10, gamma=1, kernel=rbf, max_iter=1000, score=0.515, total= 18.6s
[CV] C=10, gamma=1, kernel=poly, max_iter=1000 .......................
[CV] C=10, gamma=1, kernel=poly, max_iter=1000, score=0.519, total= 8.7s
[CV] C=10, gamma=1, kernel=poly, max_iter=1000 .......................
[CV] C=10, gamma=1, kernel=poly, max_iter=1000, score=0.508, total= 8.7s
[CV] C=10, gamma=1, kernel=poly, max_iter=1000 .......................
[CV] C=10, gamma=1, kernel=poly, max_iter=1000, score=0.517, total= 8.3s
[CV] C=10, gamma=1, kernel=poly, max_iter=1000 .......................
[CV] C=10, gamma=1, kernel=poly, max_iter=1000, score=0.525, total= 8.8s
[CV] C=10, gamma=1, kernel=poly, max_iter=1000 .......................
[CV] C=10, gamma=1, kernel=poly, max_iter=1000, score=0.526, total= 8.2s
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000 .....................
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000, score=0.530, total= 19.0s
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000 .....................
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000, score=0.525, total= 19.1s
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000 .....................
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000, score=0.522, total= 19.1s
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000 .....................
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000, score=0.525, total= 19.0s
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000 .....................
[CV] C=10, gamma=0.01, kernel=rbf, max_iter=1000, score=0.531, total= 18.9s
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000 ....................
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000, score=0.501, total= 10.9s
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000 ....................
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000, score=0.502, total= 10.9s
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000 ....................
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000, score=0.506, total= 10.9s
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000 ....................
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000, score=0.504, total= 10.9s
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000 ....................
[CV] C=10, gamma=0.01, kernel=poly, max_iter=1000, score=0.506, total= 11.0s
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000 ....................
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000, score=0.513, total= 18.9s
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000 ....................
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000, score=0.515, total= 18.9s
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000 ....................
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000, score=0.512, total= 18.9s
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000 ....................
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000, score=0.510, total= 18.9s
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000 ....................
[CV] C=10, gamma=0.001, kernel=rbf, max_iter=1000, score=0.525, total= 18.9s
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000 ...................
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000, score=0.505, total= 11.0s
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000 ...................
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000, score=0.504, total= 11.1s
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000 ...................
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000, score=0.502, total= 11.0s
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000 ...................
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000, score=0.501, total= 11.0s
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000 ...................
[CV] C=10, gamma=0.001, kernel=poly, max_iter=1000, score=0.501, total= 11.0s
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000 ......................
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000, score=0.525, total= 17.6s
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000 ......................
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000, score=0.515, total= 17.2s
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000 ......................
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000, score=0.514, total= 17.5s
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000 ......................
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000, score=0.514, total= 17.7s
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000 ......................
[CV] C=1000, gamma=1, kernel=rbf, max_iter=1000, score=0.517, total= 17.2s
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000 .....................
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000, score=0.519, total= 8.5s
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000 .....................
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000, score=0.508, total= 8.6s
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000 .....................
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000, score=0.517, total= 8.2s
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000 .....................
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000, score=0.525, total= 8.7s
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000 .....................
[CV] C=1000, gamma=1, kernel=poly, max_iter=1000, score=0.526, total= 8.2s
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000 ...................
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000, score=0.632, total= 17.3s
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000 ...................
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000, score=0.527, total= 17.2s
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000 ...................
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000, score=0.542, total= 17.2s
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000 ...................
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000, score=0.459, total= 17.4s
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000 ...................
[CV] C=1000, gamma=0.01, kernel=rbf, max_iter=1000, score=0.557, total= 17.3s
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000 ..................
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000, score=0.506, total= 10.5s
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000 ..................
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000, score=0.504, total= 10.7s
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000 ..................
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000, score=0.507, total= 10.5s
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000 ..................
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000, score=0.507, total= 10.8s
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000 ..................
[CV] C=1000, gamma=0.01, kernel=poly, max_iter=1000, score=0.505, total= 10.6s
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000 ..................
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000, score=0.510, total= 18.6s
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000 ..................
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000, score=0.530, total= 18.8s
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000 ..................
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000, score=0.522, total= 18.8s
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000 ..................
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000, score=0.534, total= 18.7s
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000 ..................
[CV] C=1000, gamma=0.001, kernel=rbf, max_iter=1000, score=0.534, total= 18.7s
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000 .................
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000, score=0.505, total= 11.0s
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000 .................
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000, score=0.504, total= 11.0s
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000 .................
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000, score=0.501, total= 11.2s
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000 .................
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000, score=0.505, total= 11.0s
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000 .................
[CV] C=1000, gamma=0.001, kernel=poly, max_iter=1000, score=0.501, total= 10.9s
[Parallel(n_jobs=1)]: Done 90 out of 90 | elapsed: 21.5min finished
GridSearchCV(cv=None, error_score=nan,
estimator=SVC(C=1.0, break_ties=False, cache_size=200,
class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3,
gamma='scale', kernel='rbf', max_iter=-1,
probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False),
iid='deprecated', n_jobs=None,
param_grid={'C': [0.1, 10, 1000], 'gamma': [1, 0.01, 0.001],
'kernel': ['rbf', 'poly'], 'max_iter': [1000]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=3)
# print best parameter after tuning
#print(grid.best_params_)
# print how our model looks after hyper-parameter tuning
#print(grid.best_estimator_)
{'C': 1000, 'gamma': 0.01, 'kernel': 'rbf', 'max_iter': 1000}
SVC(C=1000, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.01, kernel='rbf',
max_iter=1000, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
# Running the bestfit model and checking for accuracy scores
svc = SVC(C=1000, gamma=0.01, kernel='rbf', max_iter = 10000)
svc.fit(X_train, y_train)
SVC(C=1000, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.01, kernel='rbf',
max_iter=10000, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
# Training and testing the best fit model from the gridsearch
svc_train_predict = svc.predict(X_train)
svc_test_predict = svc.predict(X_test)
# checking the accuracy of the best fit model
print(accuracy_score(y_train ,svc_train_predict))
SVCscore = accuracy_score(y_test ,svc_test_predict)
SVCscore
0.5235871552340832
0.5212615738405987
pd.crosstab(y_test,svc_test_predict)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 27564 | 22009 |
| 1 | 25456 | 24117 |
Accuracy score is not as good as the other models because of the lower no. of iterations which has been limited to 10,000. When higher no. of iterations is used the colab is crashing also the computer and not able to run the model for even overnight runs.
Note that the SVC algorithm is well suited for this type of complex dataset, as the model will take the data set into a higher dimension and provide a linear classification of the dataset. For the purpose of this project we are leaving the model as is because of the limited runtime options that we have in the google colab settings.
Summary of Analysis
# Summary of the Accuracy scores for test data
model_ev = pd.DataFrame({'Model': ['Logistic Regression','KNN','Decision Tree','Random Forest',
'XG Boost','SVM Classification'], 'Accuracy (%)': [round(LRscore*100, 3), round(KNNscore*100, 3),round(Deci_Tree_test_accuracyscore*100, 3),round(RFscore*100, 3),round(XGBscore*100, 3),round(SVCscore*100, 3)]})
model_ev
| Model | Accuracy (%) | |
|---|---|---|
| 0 | Logistic Regression | 64.772000 |
| 1 | KNN | 74.590000 |
| 2 | Decision Tree | 72.737000 |
| 3 | Random Forest | 81.963000 |
| 4 | XG Boost | 84.305000 |
| 5 | SVM Classification | 52.126000 |
colors = ['red','green','blue','c','orange', 'yellow']
plt.figure(figsize=(15,7))
plt.title("Barplot of 6 Models", size = 15)
plt.xlabel("Models")
plt.xticks(rotation=90)
plt.ylabel("Accuracy")
plt.bar(model_ev['Model'],model_ev['Accuracy (%)'],color = colors)
plt.show()
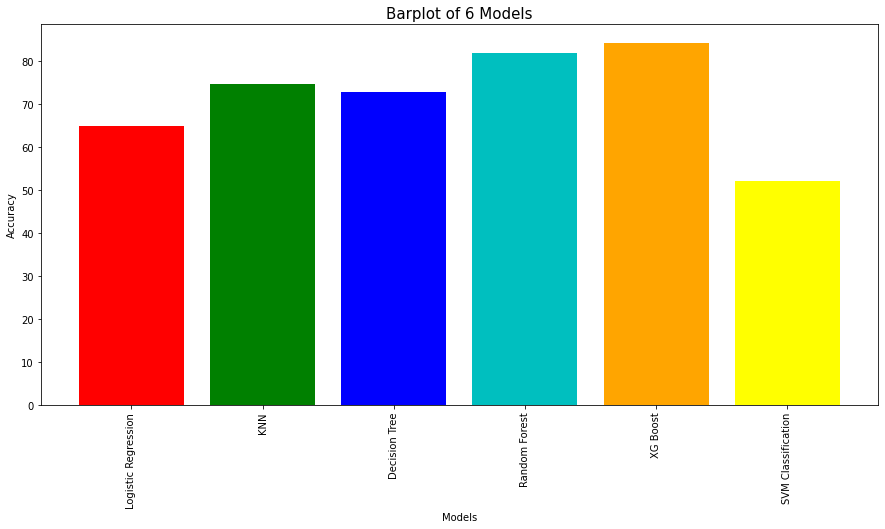
# Checking to see if the XGB model can be further improved by changing the threshold to optimal value
# As there are many actual defaults that have been predicted as no defaults we are running the below analysis to see if we can change the threshold
# the default threshold is 0.5, by running the below analysis for different threshold we can find the optimal threshold that will improve accuracy
# defining the function
def predict_threshold (model,X_test,thresholds):
#import numpy as np
return np.where(xgb_clf.predict_proba(X_test)[:,1]>thresholds,1,0)
# checking for different thresholds from 0 to 1.0
for thr in np.arange(0,1.1,0.1):
y_predict = predict_threshold(xgb_clf,X_test,thr)
print("Threshold :",thr)
print("accuracy score for" , thr , "is", accuracy_score(y_test, y_predict))
Threshold : 0.0
accuracy score for 0.0 is 0.5
Threshold : 0.1
accuracy score for 0.1 is 0.7063119036572327
Threshold : 0.2
accuracy score for 0.2 is 0.7466766183204567
Threshold : 0.30000000000000004
accuracy score for 0.30000000000000004 is 0.7649426098884473
Threshold : 0.4
accuracy score for 0.4 is 0.7757751195207069
Threshold : 0.5
accuracy score for 0.5 is 0.7796481955903415
Threshold : 0.6000000000000001
accuracy score for 0.6000000000000001 is 0.7778427773182983
Threshold : 0.7000000000000001
accuracy score for 0.7000000000000001 is 0.7692393036531983
Threshold : 0.8
accuracy score for 0.8 is 0.7460008472353903
Threshold : 0.9
accuracy score for 0.9 is 0.6889334920218667
Threshold : 1.0
accuracy score for 1.0 is 0.5
The optimal threshold is 0.5 same as the default threshold. So leaving the model as is.
Phase 5
In this last phase, we agree to reduce 4 features (refers to highly correlated to each other).
#feature scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_scaled = sc.fit_transform(x_smote)
X = pd.DataFrame(x_scaled)
X.columns = list(x.columns)
X.head()
| AMT_ANNUITY_y | AMT_APPLICATION | AMT_CREDIT_SUM | AMT_INSTALMENT | DAYS_BIRTH | EXT_SOURCE_2 | |
|---|---|---|---|---|---|---|
| 0 | -1.138667 | -0.564436 | -0.685497 | 0.006810 | -0.867234 | 0.529434 |
| 1 | 0.863803 | 2.935385 | -0.452646 | 0.737889 | -1.074674 | -0.682251 |
| 2 | 0.848332 | -0.945152 | 0.093800 | 0.983891 | -0.374388 | -0.518632 |
| 3 | -0.189699 | 0.557533 | 0.408521 | -0.013969 | 0.366167 | 1.402901 |
| 4 | 0.848332 | -0.945152 | -0.457185 | -1.332682 | -1.113774 | -1.290194 |
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_smote, test_size=0.33, random_state=42, stratify=y_smote) #stratify -> it can reduce the variability of sample statistics
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((214792, 6), (105794, 6), (214792,), (105794,))
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
Model 1: Logistric Regression
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train,y_train)
LRy_predict= model.predict(X_test) #---> model predictions
LRscore = accuracy_score(y_test,LRy_predict)
print(LRscore)
pd.crosstab(y_test,LRy_predict)
0.6447057489082557
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 35383 | 17514 |
| 1 | 20074 | 32823 |
def predict_threshold (model,X_test,thresholds):
#import numpy as np
return np.where(model.predict_proba(X_test)[:,1]>thresholds,1,0)
for thr in np.arange(0,1.1,0.1):
y_predict = predict_threshold(model,X_test,thr)
print("Threshold :",thr)
print(confusion_matrix(y_test,y_predict))
print("accuracy score for" , thr , "is", accuracy_score(y_test, y_predict))
Threshold : 0.0
[[ 0 52897]
[ 0 52897]]
accuracy score for 0.0 is 0.5
Threshold : 0.1
[[ 0 52897]
[ 0 52897]]
accuracy score for 0.1 is 0.5
Threshold : 0.2
[[ 1370 51527]
[ 98 52799]]
accuracy score for 0.2 is 0.5120233661644328
Threshold : 0.30000000000000004
[[10662 42235]
[ 2199 50698]]
accuracy score for 0.30000000000000004 is 0.579995084787417
Threshold : 0.4
[[24187 28710]
[ 9430 43467]]
accuracy score for 0.4 is 0.6394880617048225
Threshold : 0.5
[[35383 17514]
[20074 32823]]
accuracy score for 0.5 is 0.6447057489082557
Threshold : 0.6000000000000001
[[43081 9816]
[31698 21199]]
accuracy score for 0.6000000000000001 is 0.6075958939070268
Threshold : 0.7000000000000001
[[48603 4294]
[42419 10478]]
accuracy score for 0.7000000000000001 is 0.558453220409475
Threshold : 0.8
[[51909 988]
[50607 2290]]
accuracy score for 0.8 is 0.5123069361211411
Threshold : 0.9
[[52897 0]
[52897 0]]
accuracy score for 0.9 is 0.5
Threshold : 1.0
[[52897 0]
[52897 0]]
accuracy score for 1.0 is 0.5
Model 2: KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=10, p=2,
weights='uniform')
# prediction
knn_train_predict = knn.predict(X_train)
knn_test_predict = knn.predict(X_test)
pd.crosstab(y_test,knn_test_predict)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 36108 | 16789 |
| 1 | 12283 | 40614 |
# training and testing accuracy scores
print(accuracy_score(y_train ,knn_train_predict))
KNNscore = accuracy_score(y_test ,knn_test_predict)
KNNscore
0.7832926738426013
0.7252018072858574
Model 3: Decision Tree
from sklearn.tree import DecisionTreeClassifier
# Model building
Deci_Tree_best_model = DecisionTreeClassifier(max_depth=30, random_state=0)
# Model fitting to the datasets
Deci_Tree_best_model.fit(X_train , y_train)
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=30, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=0, splitter='best')
# Training and testing of the model
train_predict = Deci_Tree_best_model.predict(X_train)
test_predict = Deci_Tree_best_model.predict(X_test)
# checking the accuracy scores of the model
Deci_Tree_train_accuracyscore = accuracy_score(y_train ,train_predict)
Deci_Tree_test_accuracyscore = accuracy_score(y_test, test_predict)
print(Deci_Tree_train_accuracyscore, Deci_Tree_test_accuracyscore)
pd.crosstab(y_test,test_predict)
0.9577172334165146 0.7032629449685237
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 35346 | 17551 |
| 1 | 13842 | 39055 |
Model 4: Random Forest
from sklearn.ensemble import RandomForestClassifier
# Building the best fit model using the parameters from the grid search
RFBmodel = RandomForestClassifier(random_state=3, max_depth= 30 , n_estimators=100)
RFBmodel.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=30, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=3, verbose=0,
warm_start=False)
# Training and testing the model and checking accuracy scores
RFBtrain_predict = RFBmodel.predict(X_train)
RFBtest_predict = RFBmodel.predict(X_test)
print(accuracy_score(y_train ,RFBtrain_predict))
RFscore = accuracy_score(y_test , RFBtest_predict)
RFscore
0.9904605385675445
0.7884946216231544
pd.crosstab(y_test,RFBtest_predict)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 38860 | 14037 |
| 1 | 8339 | 44558 |
Model 5: XG Boost
#! pip install xgboost
# import XGBoost
import xgboost as xgb
# Model building and using gridsearch to get the optimal parameters
from xgboost import XGBClassifier
params = {
'objective':'binary:logistic',
'max_depth': 30,
'learning_rate': 1.0,
'n_estimators':100
}
# instantiate the classifier
xgb_clf = XGBClassifier(**params)
# fit the classifier to the training data
xgb_clf.fit(X_train, y_train)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
learning_rate=1.0, max_delta_step=0, max_depth=30,
min_child_weight=1, missing=None, n_estimators=100, n_jobs=1,
nthread=None, objective='binary:logistic', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)
# Prediction using the best fit model and checking accuracy scores
y_pred = xgb_clf.predict(X_test)
XGBscore = accuracy_score(y_test, y_pred)
XGBscore
0.7562999792048698
pd.crosstab(y_test,y_pred)
| col_0 | 0 | 1 |
|---|---|---|
| row_0 | ||
| 0 | 38698 | 14199 |
| 1 | 11583 | 41314 |
Model 6: SVM Classification
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from mlxtend.plotting import plot_decision_regions
from sklearn.svm import SVC
# Running the bestfit model and checking for accuracy scores
svc = SVC(C=1000, gamma=0.01, kernel='rbf', max_iter = 10000)
svc.fit(X_train, y_train)
# Training and testing the best fit model from the gridsearch
svc_train_predict = svc.predict(X_train)
svc_test_predict = svc.predict(X_test)
# checking the accuracy of the best fit model
print(accuracy_score(y_train ,svc_train_predict))
SVCscore = accuracy_score(y_test ,svc_test_predict)
SVCscore
pd.crosstab(y_test,svc_test_predict)
Interpretation:
The scores are lower for all the algorithms using the 6 features when compared to the 10 features, which means there seems to be an interaction effect between the variables that is contributing to the variance of the Target which gets lost when the 4 correlated features are eliminated from the data.
Decision:
We have chosen to discard this analysis and these models and use the best of the 10 featured models (previous phase) for our recommendation.
Recommendation
-
The Random Forest and XG Boost models are comparable and suit this project very well with the best accuracies.
-
SVM classification algorithm is a good modeling techinque for this project. This makes sense as the SVM methodology is the best technique for cluttered datasets with more than 3 dimensions. The data seems to be quite overlapping with no distinct classification boundaries but the SVM algorithm models the data at higher dimensions where the dataset can be linearly or distinctly divided into unique classes. Unfortunately we were unable to run the model with the limited runtime options in Colab.
-
Random Forest and the XG Boost Models give a comparable accuracy score and take lesser time to run.
-
We tried to improve the models further by reducing the no of feature variables (dropping those variables that were highly correlated to each other). However the accuracy scores of those models were poorer when compared to these models as there might have been some interaction effects between the variables that might have been lost when those predictor variables were lost. The results of the analysis is enclosed in HomeLoan_Phase5.ipynb for reference.
-
Model can also be further improved with the hyperparameter tuning of the SVM and XG Boost model but due to many hours of computing time and the constant crashing of the google drive due to extended usage we chose not to do that for our project.
Project Risks
-
We have taken the 10 best features from the PCA analysis to reduce the dimensionality problem for modeling purposes, so if there are any interaction effects between the features that have not been modeled, due to lack of expertise in this field, there may be considerable amount of underperformance in the model when it is implemented.
-
The project assumes that the dataset used for modeling in this project is a representative of the population dataset else the models may not provide the accuracies that are shown here.